作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2684
1.字符串操作:
- 解析身份证号:生日、性别、出生地等。
详细代码:
ID = input("请输入身份证号:")
ID_birth = ID[6:14]
ID_sex = ID[14:17]
ID_place = ID[0:6]
arry = {"440100":"广东省广州市","440101":"广东省市辖区","440103":"广东省广州市荔湾区","440184":"广东省广州市从化市","440183":"广东省广州市增城市","440104":"广东省广州市越秀区","440105":"广东省广州市海珠区"}
if int(ID_sex)%2 == 0:
sex = '女'
else:
sex = '男'
print("身份证所属地为:"+arry[ID_place]+"
"+"出生年月为:"+ID_birth+"
"+"性别为:"+sex)
运行截图

- 凯撒密码编码与解码
详细代码:
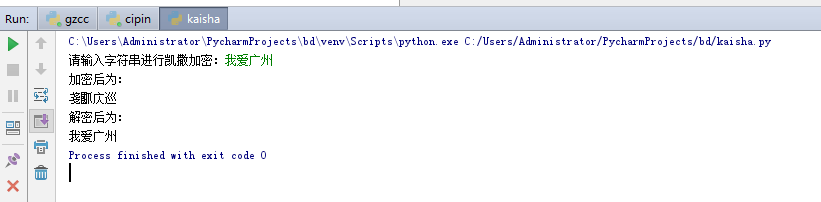
jiami = input("请输入字符串进行凯撒加密:")
jiemi = ""
print("加密后为:")
for i in jiami:
jiemi =jiemi+chr(ord(i)+3)
print(chr(ord(i)+3),end='')
print("
解密后为:")
for j in jiemi:
print(chr(ord(j)-3),end='')
运行截图:
- 网址观察与批量生成
详细代码:
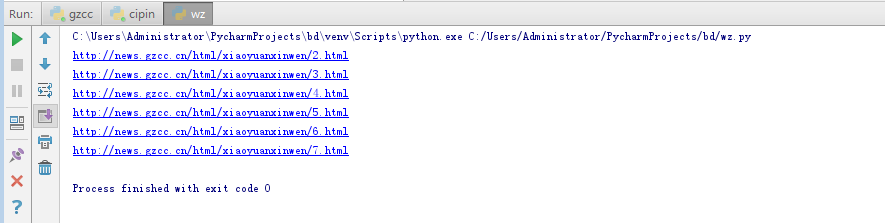
for i in range(2,8):
url='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
print(url)
运行截图:
2.英文词频统计预处理
- 下载一首英文的歌词或文章或小说。
- 将所有大写转换为小写
- 将所有其他做分隔符(,.?!)替换为空格
- 分隔出一个一个的单词
- 并统计单词出现的次数。
详细代码:
text = '''
I wanna hear you say you love me
that you just can't live without me
even if you have to lie
I just wanna hear you say
I wanna be the one you dream of
the one who knows all your secrets
the one you can't live without
'''
op=',.?!:;_/<>|'
text = text.lower()
for i in op:
text=text.replace(i,' ')
print(text.split())
word=input('输入要查询的单词的次数:')
print(text.count(word))
运行截图:

3.文件操作
- 凯撒密码:从文件读入密函,进行加密或解密,保存到文件。
详细代码:
import os
def main():
print("----------201606120048 黄泳棋--------
")
print("-------欢迎使用凯撒密码加密解密-------
")
print(" 1.凯撒加密功能
")
print(" 2.凯撒解密功能
")
print("-------------------------------------
")
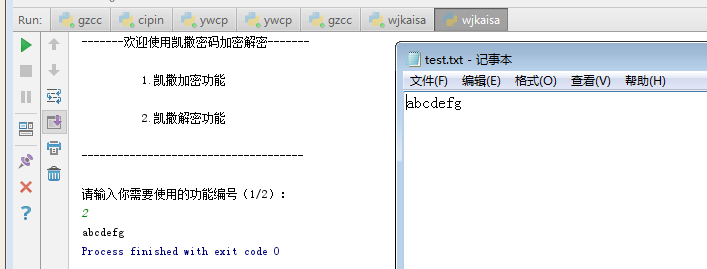
print("请输入你需要使用的功能编号(1/2):")
choice = input()
if choice=='1':
f = open('C:\test.txt', 'r')
s = f.read()
str=''
for i in s:
str = str +chr(ord(i)+3)
print(chr(ord(i) + 3), end='')
f.close()
f = open('C:\test.txt', 'w')
f.write(str)
f.close()
elif choice=='2':
f = open('C:\test.txt', 'r')
s = f.read()
str = ''
for i in s:
str = str + chr(ord(i) - 3)
print(chr(ord(i) - 3), end='')
f.close()
f = open('C:\test.txt', 'w')
f.write(str)
f.close()
else:
print("输入错误")
if __name__=='__main__':
main()
运行截图:
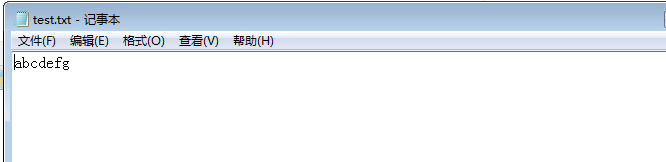
开始文件:
加密文件:

解密文件:
- 词频统计:下载一首英文的歌词或文章或小说,保存为utf8文件。从文件读入文本进行处理。
详细代码:
f = open('C:\test2.txt','r',encoding='utf8')
text = f.read()
op=',.?!:;'
text = text.lower()
for i in op:
text=text.replace(i,' ')
print(text.split())
word=input('输入要查询的单词的次数:')
print(text.count(word))
f.close()
运行截图:
