spark集群架构官方文档:http://spark.apache.org/docs/latest/cluster-overview.html
集群架构
我们先看这张图
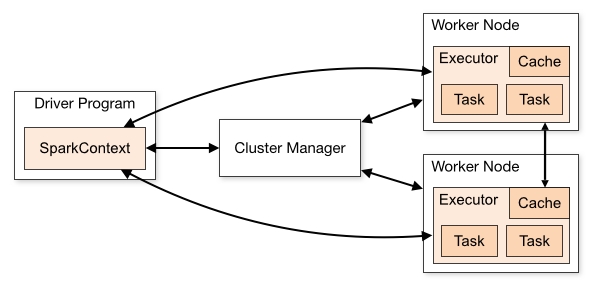
这张图把spark架构拆分成了两块内容:
1)spark应用程序:即左边的DriverProgram这块;
2)spark 集群:即右边的ClusterManager和另外两个Worker Node;
这样的结构,我们大概可以猜测一下spark是怎么工作的。首先我们会编写一个spark程序,然后启动spark集群,这个spark程序需要和spark集群交互并让spark集群运行计算并最终产生结果。
下面,分别看看什么是spark程序,什么是spark集群
什么是spark应用程序?
spark应用程序指的就是我们编写程序代码,我们的程序代码会包含一个驱动程序Driver,有了这个Driver它会调用程序的main方法去启动我们的程序,并创建一个SparkContext。
当我们的sparkContext创建完成之后,我们的程序就可以通过sparkContext和Spark集群进行交互了。
如:Driver -> 调用main() -> 创建sparkContext -> 与spark集群交互
什么是spark集群?
spark集群分为三种运行模式:standalone、yarn、mesos
为了排除干扰因素,我们这里只以standalone来理解spark集群
我们先看上图右侧部分,spark集群分为两部分:Cluster Manager和两个WorkNode。这个结构就是一个很明显的master-slaver(主从)的结构,由master来负责资源管理,而slaver来负责执行相应的任务。
sparkContext在与Cluster Manager建立连接以后就会向Cluster Manager申请资源,之后sparkContext把程序代码解析成一些task,并把这些task分发给WorkNode让WorkNode去执行task。直到所有的task执行完毕以后,sparkContext会注销,并释放资源。
如:sparkContext -> 连接ClusterManager -> 申请资源 -> 解析成多个task -> 分发给workNode -> 执行task -> 执行完毕释放资源
总结
当前Driver启动以后,会去执行应用程序的main方法,并构建sparkConext对象。sparkContext与ClusterManager连接交互,并且sparkContext将程序代码解析成多个task,将task发送给workNode,workNode又会把task丢给任务执行器executor去执行,executor会启动线程池开始执行task。当所有的task执行完毕,spark向ClusterManager注销,并释放资源。
下面是spark集群架构的一些概念:
| Application | 用户编程的spark程序. 包含一个Driver驱动程序和executor要执行的代码 |
| Application jar | 一个包含spark应用程序的jar包 |
| Driver program | 驱动程序,包含在application当中,用于执行main方法和创建sparkContext。注意:Driver可以运行在Client中,也可以运行在master中。例如,当使用spark-shell提交spark job的时候Driver运行在master上,当使用spark-submit提交或者IDEA开发的时候Driver运行在Client上 |
| Cluster manager | spark集群,主要有三种运行模式在standalone(默认)、yarn、mesos,你也可以理解为后两者是基于standalone的 |
| Deploy mode | 部署模式,分为单机部署、伪分布式、完全分布式 |
| Worker node | spark的集群的从节点,用于执行任务 |
| Executor | 任务的执行器,存在于workNode当中 |
| Task | application的代码被解析成许多task,并发送给executor去执行 |
| Job | 当碰到action操作的时候就会催生job,job中包含着多个task并行计算 |
| Stage | task的组 |
| Client | 客户端程序,用于提交spark job |
这里的job、task、stage你可能会产生疑惑,它们具体是什么东西
spark的应用程序包含着用户编写的可执行代码,那么这些程序代码会被sparkContext解析成一个叫有向无环图(dag)的结构(这里我们不讨论dag,只需要知道它是一种结构)。
而后,当碰到一个action这种代码操作的时候,就会根据dag结构去催生job。这个job包含着许多task,而这些混乱的task需要被组织起来,task的组就是stage。
如:task -> 分组 -> stage -> 组成 -> job