简介
spark graphx官网:http://spark.apache.org/docs/latest/graphx-programming-guide.html#overview
spark graphx是基于spark core之上的一个图计算组件,graphx扩展了spark RDD,是spark对于图计算的一种抽象。
这里的图,不是“图画”的意思,是一种数据结构。这种数据结构由“点”和“线”组成,拿用户关系图来说,“点”描述的就是用户,“线”描述的就是这些用户之间的关系,所以由“点”和“线”组成了一张“用户关系图”,如图:
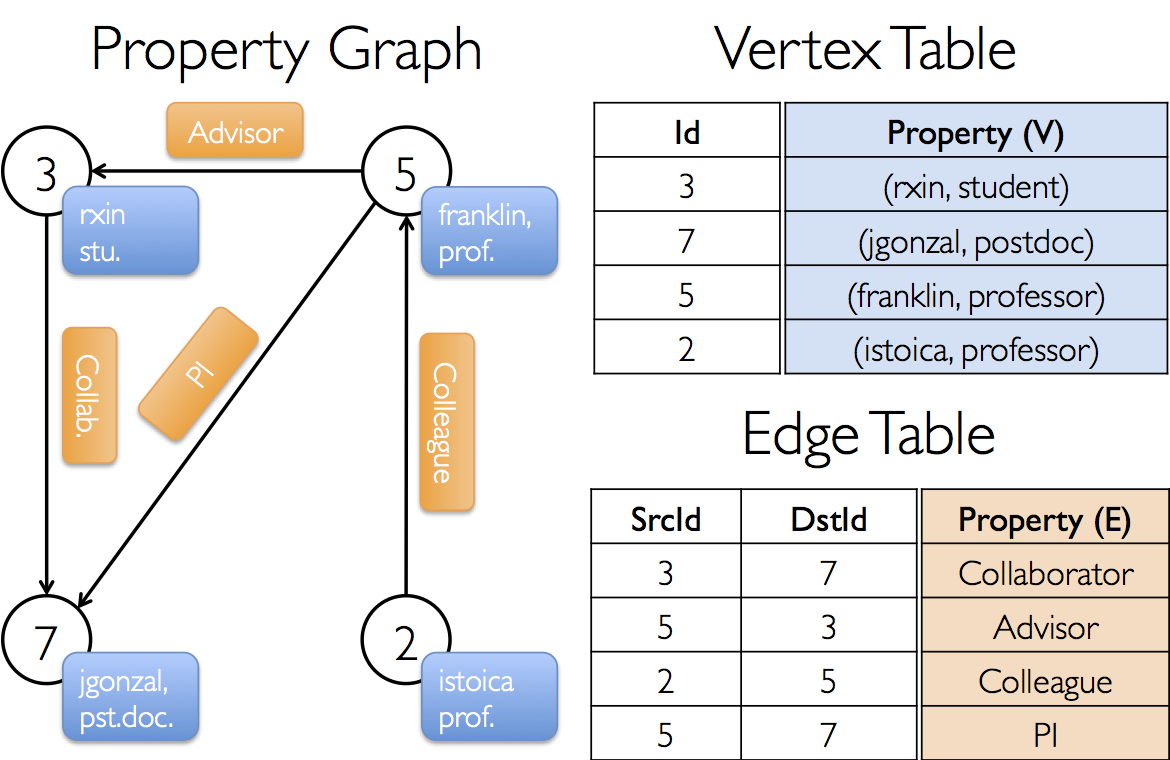
vertex table: 点,是由ID和Property属性组成的,ID必须是Long类型
edge table:线,是由起始ID,终点ID,property属性组成的,ID也必须为Long类型
property graph:图,由vertex和edge的数据,就可以构建出一张graph图数据结构
而spark graphx就是将这种数据结构创建出来,并提供简单易用的API来操作这个数据结构,如:查询、转换、关联、聚合等
代码示例
下面是scala语言的代码示例:
import org.apache.spark.graphx.{Edge, Graph} import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @Description spark graphx demo * @Author lay * @Date 2018/12/09 20:19 */ object SparkGraphxDemo { var conf: SparkConf = _ var sc: SparkContext = _ var userData: Array[String] = Array("1 lay", "2 marry", "3 gary") var relationData: Array[String] = Array("1 2 朋友", "1 3 同事", "2 3 姐弟") var userRDD: RDD[(Long, String)] = _ var relationRDD: RDD[Edge[String]] = _ def init(): Unit = { conf = new SparkConf().setAppName("spark graphx demo").setMaster("local") sc = new SparkContext(conf) } def loadRdd(): Unit = { userRDD = sc.parallelize(userData).map { x => val lines = x.split(" "); (lines(0).toLong, lines(1)) } relationRDD = sc.parallelize(relationData).map { x => val lines = x.split(" "); Edge(lines(0).toLong, lines(1).toLong, lines(2)) } } def main(args: Array[String]): Unit = { // 初始化 init() // 加载rdd loadRdd() // 创建graph var graph = Graph(userRDD, relationRDD) // 找出和lay有关系的人 graph.triplets.filter(x => x.srcId == 1L).foreach{x => printf("%s是%s的%s", x.dstAttr, x.srcAttr, x.attr);println()} } }
我们将userRDD和relationRDD构建成了一个抽象结构Graph,然后过滤出了和lay有关系的人,并循环打印出结果,如下:
marry是lay的朋友
gary是lay的同事