数据库引擎
什么是引擎?一个功能的核心部分
核心功能是存储数据,涉及到存储数据的代码就称之为存储引擎
根据不同的需求也有着不同的引擎分类
创建表时在最后指定引擎名称 engine=xxx
create table t1(id int)engine=innodb
create table t1(id int not null)engine=CSV
create table t1(id int)engine=memory
create table t1(id int)engine=blackhole
总结:innodb是默认的引擎因为它是永久存储并且支持事务,行锁,外键
表详情
创建表的完整语法
create table 表名(字段名称 数据类型[(长度) 约束条件],字段名称 数据类型[(长度) 约束条件]);
字段名 数据类型 表名 都是必须填的 长度,约束条件是可写可不写的。 长度用于设置数据的长度
数据类型也是一种约束,约束指的是除了数据类型外的额外的规范。如果添加的数据超过了指定的长度范围,超出范围的就丢弃
注意:字段名 表名 库名 都不能是mysql的关键字
数据类型
为什么要将数据分类?
1.为了描述事物 更加准确
2.描述起来更方便
3.节省内存空间
a s 你
utf8下5个字节
l a b c
unicode 6个字节
整型:
tinyint 字节数1 smallint 字节数2 mediumint 字节数3 int字节数4 bigint字节数8
默认情况下整型都是有符号的,需要一个二进制位存储符号
给整型加上约束 unsigned 来表示无符号
如果数据超出范围就尽可能保存最大的例如在无符号下保存256其实存的255
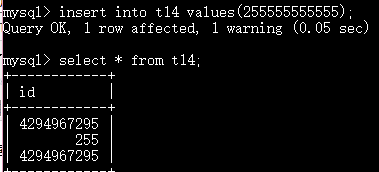
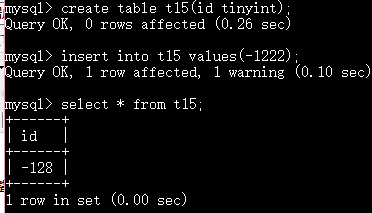
如果有符号 例如tinyint 保存-1222 其实存的是-128 是最小值
修改严格模式 set global sql_mode = "STRICT_TRANS_TABLES";
严格模式下,如果值超出范围就直接报错,在一些版本中默认就是严格模式。
长度限制对于整型的意义:
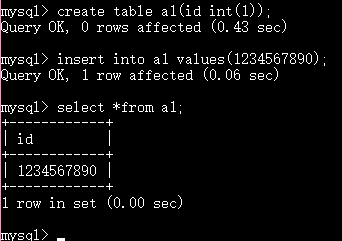
这个数能存储成功说明这里的长度指的不是存储容量限制而是显示的宽度,如果你的数据超过了显示宽度 有几个显示几个 如果不足则补全到指定长度 默认下用空格补全
zerofill 告诉它用0来补全
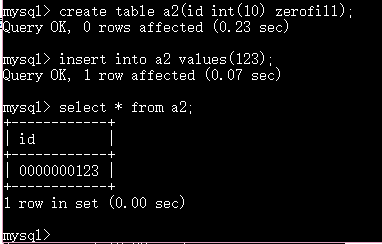
总结 不是容量限制而是现实宽度
要限制现实宽度
1.创建表时给整型加上宽度
2.加上zerofill约束
浮点型:小数型
float 字节数4 double 字节数8 decimal 不确定(手动指定)
给浮点设置宽度限制
float(m,d)
double(m,d)
decimal(m,d)
m表示 这个浮点数整体的长度
d表示 小数部分的长度 小数部分的最大长度是30
这里float(5,3) 最大值:99.999
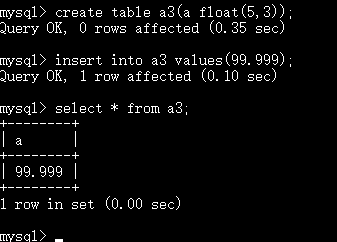
相同点:小数部分最大长度都是30
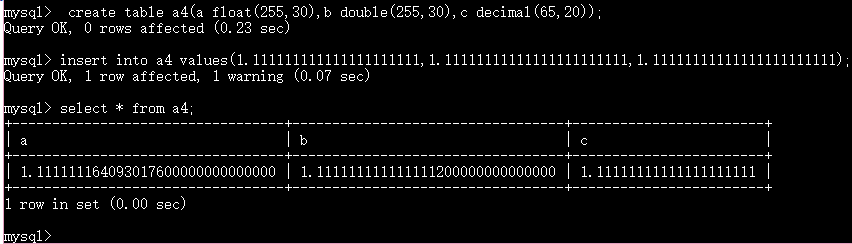
float和double的最大长度为255
不同点:decimal的整体最大长度65
精度不同
double比float精度高
decimal是准确的 不会丢失精度
对于精度的要求越高就使用decimal
字符型
char 定长字符
varchar 变长字符
char类型的长度是固定的无论你存储的数据有多长占用的容量都一样
char(3) 存储的数据为“a” 在硬盘保存的数据还是占3字符长度,实际保存的是“a ”
varchar(3)长度是可变的存储的数据有多长就占用多长
varchar(3) 存储的数据为“a” 在硬盘保存的数据还是占1字符长度 实际保存的是“a”
yxx exx lxx zxx cx wxx char(3)
(1bytes+yx)(1bytes+exx)(1bytes+lx)(1bytes+zxx) varchar(3)
如果是可变长度 则有问题 不知道数据从哪里开始到哪里结束 所以需要有一个位置保存数据的长度
vharchar 能支持的最大长度是65535 用于保存数据长度的数据最长两个bytes
如果是char类型 如果你的数据不足指定长度 就在后面用空格补全
char
存取效率高
浪费存储空间
varchar
存取效率低于char
节省存储空间
使用起来感受不到区别 通常用的是char
char和varchar 长度都比较小 最大就是65535
时间和日期
time 时分秒 HH:MM:SS ***
year 年份 ***
date 日期 年月日 ***
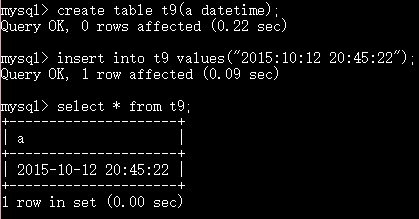
datetime 日期加时间 年月日 时分秒 年份最大是9999 *****
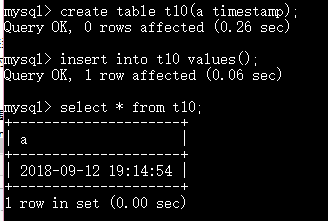
timestamp 时间戳 从1970-1-1开始算 年份最大是2037 *****
相同:
时间的存取通过字符串类型,都可以使用now()函数来插入当前时间
datetime 和 时间戳都能够表示日期和时间
不同:
年份最大范围不同
时间戳可以为空 代表当前时间
时间戳在你更新记录时 会自动更新为当前时间
枚举:
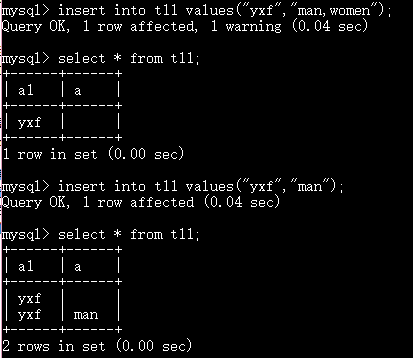
用于描述一个已知范围的数据 例如性别: 只有男、女、其他
enum("man","woman","other")
总结: 枚举中只能是字符串类型
添加的数据只能是已经出现在枚举中的值
你的值只能是其中的一个
你也可以使用枚举值的序号来插入值从1开始
只能多个值选择一个
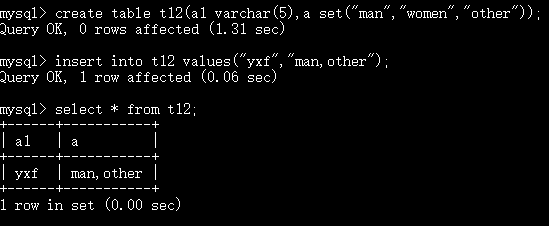
集合:
用于描述一堆数据 比如你的兴趣爱好
set("watch movie","listen music","play game")
总结:集合中的数据 只能是字符串
添加的数据只能是已经出现在集合中的值
你的值可以是其中的任意几个
你也可以使用枚举值的序号来插入值 从1开始,但是只能给一个序号
可以多个值选择多个