回顾yield
yield
1.用在函数里,把函数的执行结果做成一个生成器,注意:是执行结果
2.与return功能类似,都可以返回值;return只能返回一次值,然后结束函数;yield可以返回多个值
3.yield会暂停函数,保存函数状态
 举例
举例

def func(count):
print('start')
while True:
yield count
count +=1
func(10)
g=func(10)
print(g) #<generator object func at 0x000002341F69FDB0> 注意注意!!把函数的执行结果做成生成器generator,执行结果
next(g)#start next会触发生成器的执行
print(next(g)) #11
g.__iter__() #只有iter属性的是迭代对象
g.__next__()#iter和next都有的是迭代器,触发迭代器执行的是next,生成器本质上是迭代器
协程函数讲解
本质上是 yield的表达式的应用
yield的表达式应用:
两个阶段:
1.初始化
next(g)
g.send(None)
2.传值
g.send('apple')
#一个什么都不做的装饰器模板
def init(func):
def wrapper(*args,**kwargs):
pass
return wrapper
#自动初始化的装饰器
def init(func):
def warpper(*args,**kwargs):
g=func(*args,**kwargs)
next(g)
return g
return warpper
@init
def eater(name):
print('%s start eat' %name)
food_list=[]
while True:
food=yield food_list
food_list.append(food)
print('%s start eat %s' %(name,food))
g=eater('alex')
print(g)
#初始化
#next(g)
#传值
print(g.send('apple'))
print(g.send('banana'))
面向过程
核心是过程
介绍
核心是过程,过程即解决问题的步骤。基于面向过程的程序,就像是在设计一条工业流水线,是机械式的思维
优点:程序结构清晰,可以把复杂的问题简单化,流程化
缺点:可扩展性差,一条流水线只用来解决一个问题
应用场景:httpd shell脚本 linux内核
举例详解
利用python实现以下命令的作用
grep -rl 'error' /dir/ 过滤出dir目录下所有带有‘error’的文件名字
先分析实现的过程(面向过程)
1.找出dir目录下所有的文件的绝对路径 os.walk()
2.打开文件
3. 每打开一个文件,循环过滤每一行
4.过滤‘error’关键字
5.打印带有‘error’行所属于的文件的绝对路径
基于分析步骤写代码
目录结构如下:

每个文件的内容如下
a1.txt
ergreggr
error
error
a2.txt
fdhskdfvb
bdsskfhdsf
fdksfdsnf
ndskfuod
b1.txt
error
c1.txt
dhfdfh
errornfkd
dkjfhbv
djfdj
errornfkd
dkjfhbv
djfdj
先介绍一下 os.walk()的用法
import os
g=os.walk(r'F:untitleda')
print(g)
print(next(g))
print(next(g))
print(next(g))
'''
打印结果
<generator object walk at 0x000002C158C3FE60>
('F:\untitled\a', ['b'], ['a1.txt', 'a2.txt']) 元组 列表 子目录 子文件
('F:\untitled\a\b', ['c'], ['b1.txt'])
('F:\untitled\a\b\c', [], ['c1.txt'])
'''
代码如下:
#装饰器
def init(func):
def warpper(*args,**kwargs):
g=func(*args,**kwargs)
next(g)
return g
return warpper
import os
#第一阶段:找到所有文件的绝对路径
@init
def search(target):
while True:
filepath=yield
g=os.walk(filepath)
for pardir,_,files in g:
for file in files:
abspath=r'%s/%s' %(pardir,file)
target.send(abspath)
#第二阶段:打开文件
@init
def opener(target):
while True:
abspath=yield
with open(abspath,'rb') as f:
target.send((abspath,f))
#第三阶段:循环读出每一行内容
@init
def cat(target):
while True:
abspath,f=yield
for line in f:
res=target.send((abspath,line))
if res:break
#第四阶段:过滤
@init
def grep(pattern,target):
tag=False
while True:
abspath,line=yield tag
tag=False
if pattern in line:
target.send(abspath)
tag=True
#第五阶段:打印该行属于的文件名
@init
def printer():
while True:
abspath=yield
print(abspath)
g = search(opener(cat(grep('error'.encode('utf-8'), printer()))))
g.send(r'F:untitleda')
递归调用
定义
在调用一个函数的过程中,直接或间接的调用了函数本身
递归效率低,需要在进入下一次递归时保留当前的状态,
解决方法是尾递归,即在函数的最后一步(而非最后一行)调用自己
但是python又没有尾递归,且对递归层级做了限制
解决方法是尾递归,即在函数的最后一步(而非最后一行)调用自己
但是python又没有尾递归,且对递归层级做了限制
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
尾递归优化:http://egon09.blog.51cto.com/9161406/1842475
def func():
print('sb')
func()
func()
打印结果 递归在python里有次数限制,不会无限制递归的
RecursionError: maximum recursion depth exceeded while calling a Python object
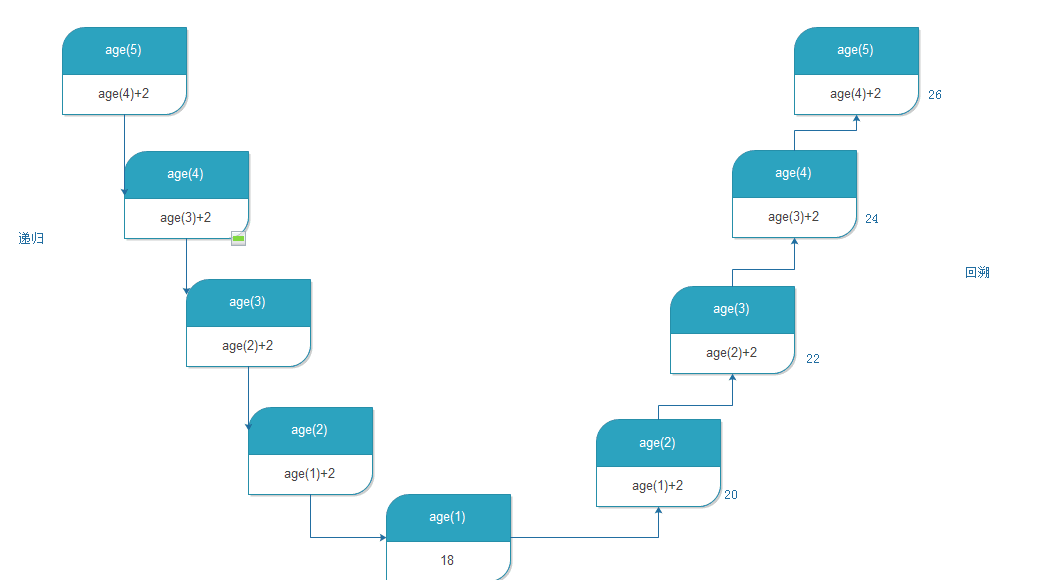
递归必须有两个阶段:
递推
回溯
举例算年龄 每个人之间都相差两岁
def age(n):
if n ==1:
return 18
return age(n-1)+2
print(age(6))
查看python解释器递归的限制数:
进入python解释器
>>> import sys
>>> sys.getrecursionlimit()
1000
>>> sys.setrecursionlimit(10000)
>>> sys.getrecursionlimit()
10000
二分法
二分法也是递归的应用举例如下:
l=[1,22,33,34,39,40,41,44,55,66,77,88,99,]
def binary_search(l,num):
if len(l) > 1:
mid_index=len(l)//2
if num > l[mid_index]:
l=l[mid_index:]
binary_search(l,num)
elif num < l[mid_index]:
l=l[:mid_index]
binary_search(l,num)
else:
print('find it',num)
else:
if l[0]==num:
print('find it',num)
else:
print('not exits')
return
binary_search(l,100)