1.0 分布式事务概述 2018-02-05 02:05:26 32,685 16
1、事务简介
事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。在关系数据库中,一个事务由一组SQL语句组成。事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
原子性(atomicity):个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
一致性(consistency):事务必须是使数据库从一个一致性状态变到另一个一致性状态,事务的中间状态不能被观察到的。
隔离性(isolation):一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。隔离性又分为四个级别:读未提交(read uncommitted)、读已提交(read committed,解决脏读)、可重复读(repeatable read,解决虚读)、串行化(serializable,解决幻读)。
持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
任何事务机制在实现时,都应该考虑事务的ACID特性,包括:本地事务、分布式事务,及时不能都很好的满足,也要考虑支持到什么程度。
2 本地事务
大多数场景下,我们的应用都只需要操作单一的数据库,这种情况下的事务称之为本地事务(Local Transaction)。本地事务的ACID特性是数据库直接提供支持。本地事务应用架构如下所示:
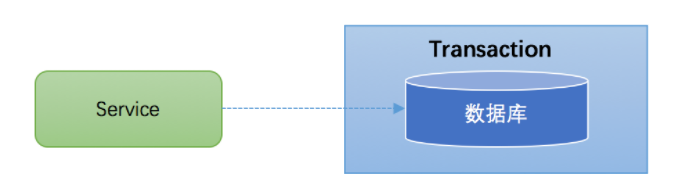
在JDBC编程中,我们通过java.sql.Connection对象来开启、关闭或者提交事务。代码如下所示:
Connection conn = ... //获取数据库连接
conn.setAutoCommit(false); //开启事务
try{
//...执行增删改查sql
conn.commit(); //提交事务
}catch (Exception e) {
conn.rollback();//事务回滚
}finally{
conn.close();//关闭链接
}
此外,很多java应用都整合了spring,并使用其声明式事务管理功能来完成事务功能。一般使用的步骤如下:
1、配置事务管理器。spring提供了一个PlatformTransactionManager接口,其有2个重要的实现类:
DataSourceTransactionManager:用于支持本地事务,事实上,其内部也是通过操作java.sql.Connection来开启、提交和回滚事务。
JtaTransactionManager:用于支持分布式事务,其实现了JTA规范,使用XA协议进行两阶段提交。需要注意的是,这只是一个代理,我们需要为其提供一个JTA provider,一般是Java EE容器提供的事务协调器(Java EE server's transaction coordinator),也可以不依赖容器,配置一个本地的JTA provider。
2、 在需要开启的事务的bean的方法上添加@Transitional注解
可以看到,spring除了支持本地事务,也支持分布式事务,下面我们先对分布式事务的典型应用场景进行介绍。
3 分布式事务典型场景
当下互联网发展如火如荼,绝大部分公司都进行了数据库拆分和服务化(SOA)。在这种情况下,完成某一个业务功能可能需要横跨多个服务,操作多个数据库。这就涉及到到了分布式事务,用需要操作的资源位于多个资源服务器上,而应用需要保证对于多个资源服务器的数据的操作,要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同资源服务器的数据一致性。
典型的分布式事务场景:
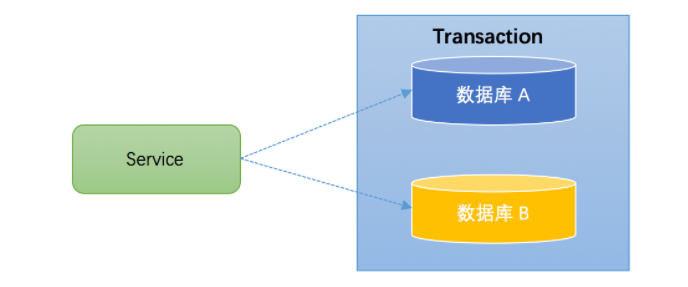
1、跨库事务
跨库事务指的是,一个应用某个功能需要操作多个库,不同的库中存储不同的业务数据。笔者见过一个相对比较复杂的业务,一个业务中同时操作了9个库。下图演示了一个服务同时操作2个库的情况:
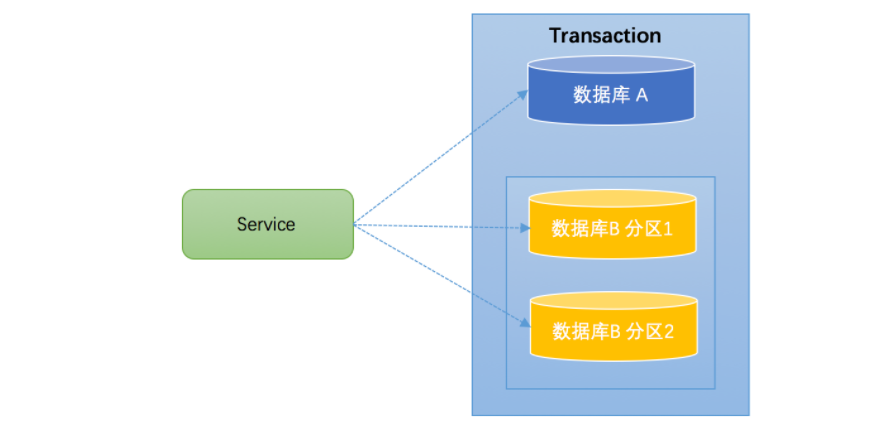
2、分库分表
通常一个库数据量比较大或者预期未来的数据量比较大,都会进行水平拆分,也就是分库分表。如下图,将数据库B拆分成了2个库:
对于分库分表的情况,一般开发人员都会使用一些数据库中间件来降低sql操作的复杂性。如,对于sql:insert into user(id,name) values (1,"tianshouzhi"),(2,"wangxiaoxiao")。这条sql是操作单库的语法,单库情况下,可以保证事务的一致性。
但是由于现在进行了分库分表,开发人员希望将1号记录插入分库1,2号记录插入分库2。所以数据库中间件要将其改写为2条sql,分别插入两个不同的分库,此时要保证两个库要不都成功,要不都失败,因此基本上所有的数据库中间件都面临着分布式事务的问题。
3、服务化(SOA)
微服务架构是目前一个比较一个比较火的概念。例如上面笔者提到的一个案例,某个应用同时操作了9个库,这样的应用业务逻辑必然非常复杂,对于开发人员是极大的挑战,应该拆分成不同的独立服务,以简化业务逻辑。拆分后,独立服务之间通过RPC框架来进行远程调用,实现彼此的通信。下图演示了一个3个服务之间彼此调用的架构:
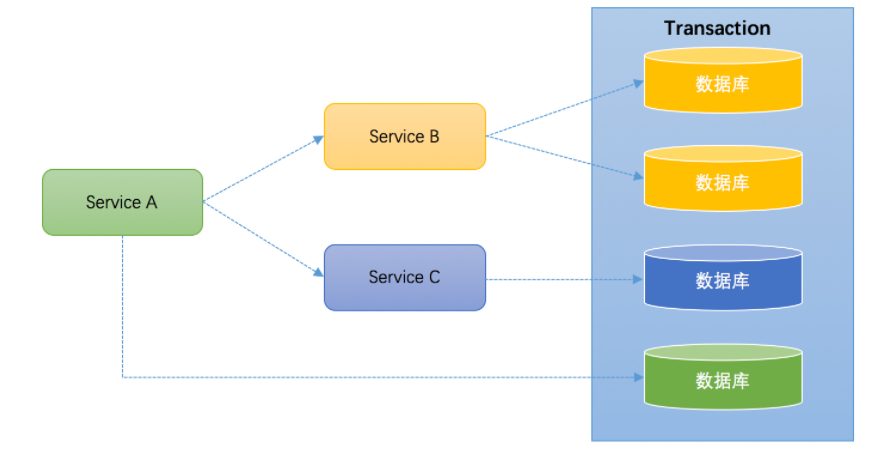
Service A完成某个功能需要直接操作数据库,同时需要调用Service B和Service C,而Service B又同时操作了2个数据库,Service C也操作了一个库。需要保证这些跨服务的对多个数据库的操作要不都成功,要不都失败,实际上这可能是最典型的分布式事务场景。
小结:上述讨论的分布式事务场景中,无一例外的都直接或者间接的操作了多个数据库。如何保证事务的ACID特性,对于分布式事务实现方案而言,是非常大的挑战。同时,分布式事务实现方案还必须要考虑性能的问题,如果为了严格保证ACID特性,导致性能严重下降,那么对于一些要求快速响应的业务,是无法接受的。
4 X/Open DTP模型与XA规范
X/Open,即现在的open group,是一个独立的组织,主要负责制定各种行业技术标准。官网地址:http://www.opengroup.org/。X/Open组织主要由各大知名公司或者厂商进行支持,这些组织不光遵循X/Open组织定义的行业技术标准,也参与到标准的制定。下图展示了open group目前主要成员(官网截图):

可以看到,中国人的骄傲,华为,赫然在列!!!此处应该有掌声。
就分布式事务处理(Distributed Transaction Processing,简称DTP)而言,X/Open主要提供了以下参考文档:
DTP 参考模型: <
DTP XA规范: << Distributed Transaction Processing: The XA Specification>>
4.1 DTP模型
1、模型元素
在<
应用程序(Application Program ,简称AP):用于定义事务边界(即定义事务的开始和结束),并且在事务边界内对资源进行操作。
资源管理器(Resource Manager,简称RM):如数据库、文件系统等,并提供访问资源的方式。
事务管理器(Transaction Manager ,简称TM):负责分配事务唯一标识,监控事务的执行进度,并负责事务的提交、回滚等。
通信资源管理器(Communication Resource Manager,简称CRM):控制一个TM域(TM domain)内或者跨TM域的分布式应用之间的通信。
通信协议(Communication Protocol,简称CP):提供CRM提供的分布式应用节点之间的底层通信服务。
其中由于通信资源管理器(Communication Resource Manager)和通信协议(Communication Protocol)是一对好基友,从Communication Protocol的简称CP上就可以看出来,两个元素的关系不一般,因此有的文章在介绍DTP模型元素时,只提到了通信资源管理器....
2、模型实例(Instance of the Model)
一个DTP模型实例,至少有3个组成部分:AP、RMs、TM。如下所示:
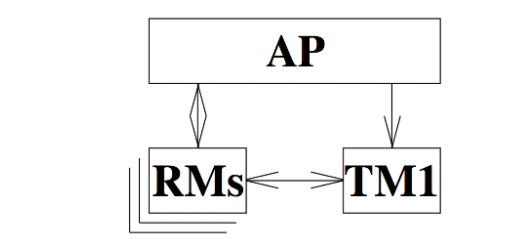
这张图类似于我们之前提到的跨库事务的概念,即单个应用需要操作多个库。在这里就是一个AP需要操作多个RM上的资源。AP通过TM来声明一个全局事务,然后操作不同的RM上的资源,最后通知TM来提交或者回滚全局事务。
特别的,如果分布式事务需要跨多个应用,类似于我们前面的提到的分布式事务场景中的服务化,那么每个模型实例中,还需要额外的加入一个通信资源管理器CRM。
下图中演示了2个模型实例,如何通过CRM来进行通信:
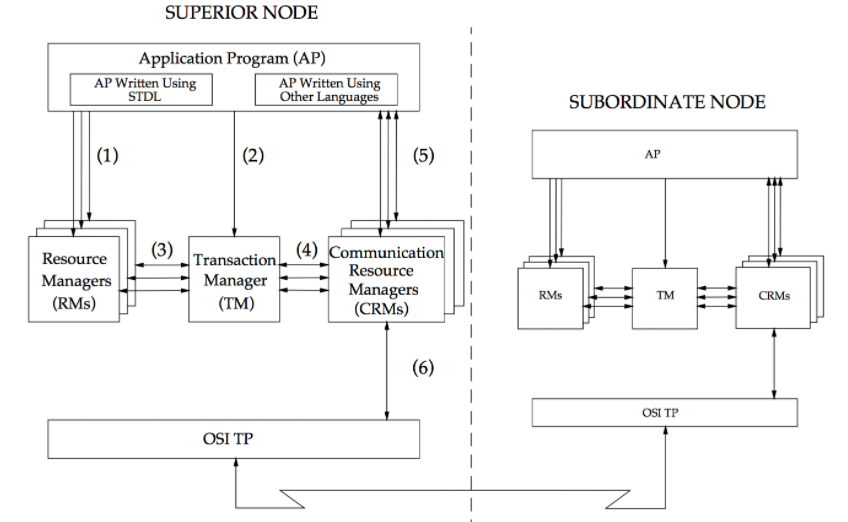
CRM作为多个模型实例之间通信的桥梁,主要作用如下:
基本的通信能力:从这个角度,可以将CRM类比为RPC框架,模型实例之间通过RPC调用实现彼此的通信。这一点体现在AP、CRM之间的连线。
事务传播能力:与传统RPC框架不同的是,CRM底层采用OSI TP(Open Systems Interconnection — Distributed Transaction Processing)通信服务,因此CRM具备事务传播能力。这一点体现TM、CRM之间的连线。
2、事务管理器作用域 (TM domain)
一个TM domain中由一个或者多个模型实例组成,这些模型实例使用的都是同一个TM,但是操作的RMs各不相同,由TM来统一协调这些模型实例共同参与形成的全局事务(global transaction)。
下图展示了一个由四个模型实例组成的TM Domain,这四个模型实例使用的都是同一个事务管理器TM1。
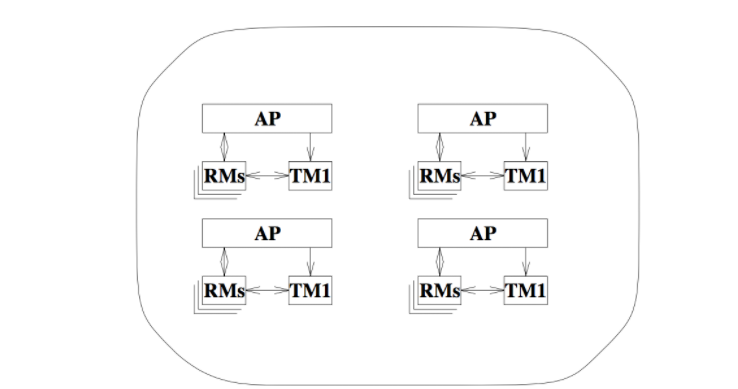
TM domain只是列出了最终参与到一个全局事务中,有哪些模型实例,并不关心这些模型实例之间的关系。这就好比,有一个班级,我们只是想知道这个班级中每位同学的名字,但是并不是关心谁是班长、谁是学习委员等。
不过显然的,当一个TM domain中存在多个模型实例时,模型实例彼此之间存在一定的层级调用关系。这就是全局事务的树形结构。
3 全局事务树形结构(Global Transaction Tree Structure)
当一个TM domain中,存在多个模型实例时,会形成一种树形条用关系,如下图所示:
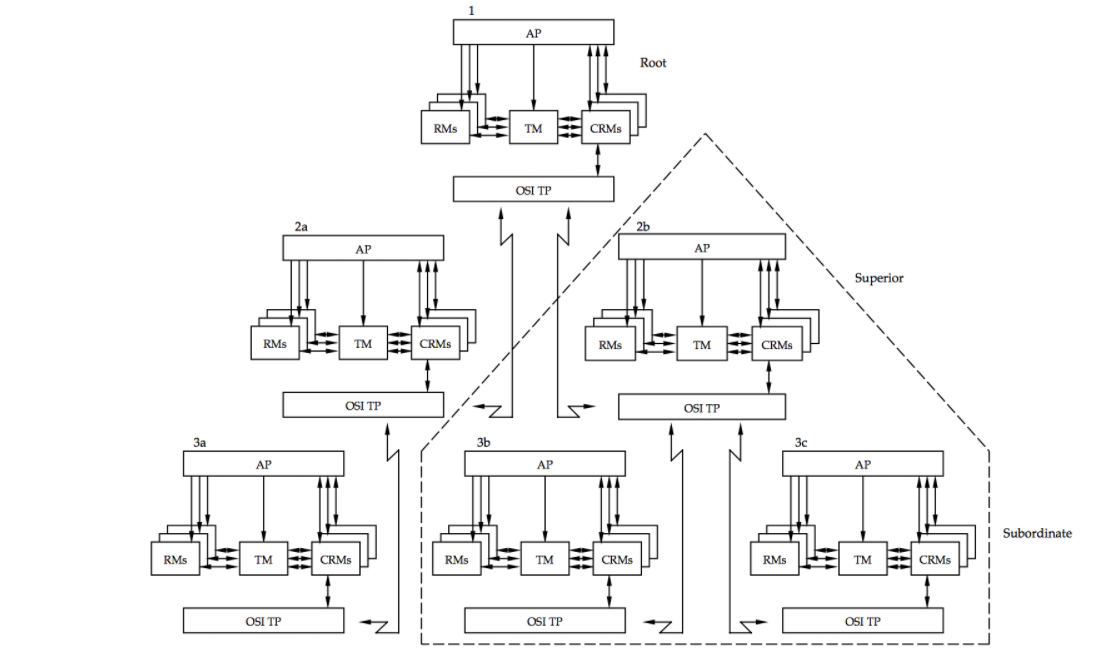
其中:
发起分布式事务的模型实例称之为root节点,或者称之为事务的发起者,其他的模型实例可以统称为事务的参与者。事务发起者负责开启整个全局事务,事务参与者各自负责执行自己的事务分支。
而从模型实例之间的相互调用关系来说,调用方称之为上游节点(Superior Node),被调用方称之为下游节点(Subordinate Node)。
小结:通过对DTP模型的介绍,我们可以看出来,之前提到的分布式事务的几种典型场景实际上在DTP模型中都包含了,甚至比我们考虑的还复杂。DTP模型从最早提出到现在已经有接近30年,到如今依然适用,不得不佩服模型的设计者是很有远见的。
4.2 XA规范
在DTP本地模型实例中,由AP、RMs和TM组成,不需要其他元素。AP、RM和TM之间,彼此都需要进行交互,如下图所示:
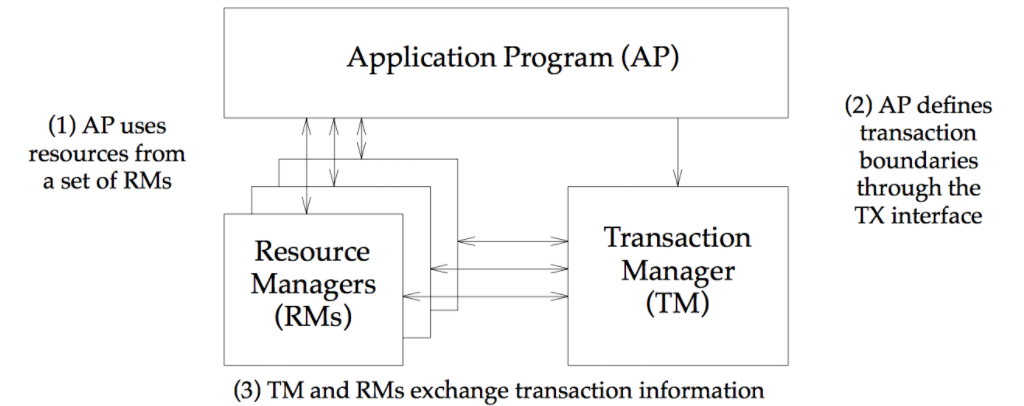
这张图中(1)表示AP-RM的交互接口,(2)表示AP-TM的交互接口,(3)表示RM-TM的交互接口。关于这张图,XA规范有以下描述:
The subject of this X/Open specification is interface (3) in the diagram above, the XA interface by which TMs and RMs interact.
For more details on this model and diagram, including detailed definitions of each component, see the referenced DTP guide.
也就是说XA规范的最主要的作用是,就是定义了RM-TM的交互接口,下图更加清晰了演示了XA规范在DTP模型中发挥作用的位置,从下图中可以看出来,XA仅仅出现在RM和TM的连线上。
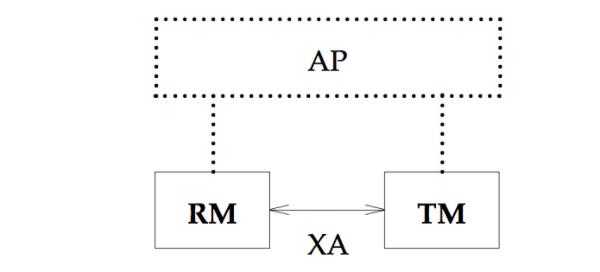
XA规范除了定义的RM-TM交互的接口(XA Interface)之外,还对两阶段提交协议进行了优化。 一些读者可能会误认为两阶段提交协议是在XA规范中提出来的。事实上: 两阶段协议(two-phase commit)是在OSI TP标准中提出的;在DTP参考模型(<<Distributed Transaction Processing: Reference Model>>)中,指定了全局事务的提交要使用two-phase commit协议;而XA规范(<< Distributed Transaction Processing: The XA Specification>>)只是定义了两阶段提交协议中需要使用到的接口,也就是上述提到的RM-TM交互的接口,因为两阶段提交过程中的参与方,只有TM和RMs。参见<<Distributed Transaction Processing: Reference Model>> 第3版 2.1节,原文如下:
Commitment Protocol
A commitment protocol is the synchronisation that occurs at transaction completion. The X/Open DTP Model follows the two-phase commit with presumed rollback1 protocol defined in the referenced OSI TP standards. A description of the basic protocol is given in Section 3.4.3 on page 13. In certain cases, a global transaction may be completed heuristically. Heuristic transaction completion is described in Section 3.4.5 on page 14.
4.2.1 XA Interface
XA规范中定义的RM 和 TM交互的接口如下图所示:

关于这些接口的详细解释,可以直接参考XA规范。后面在讲解到mysql对XA事务的支持时,我们也会使用到部分命令。
4.2.2 两阶段提交协议(2PC)
两阶段提交协议(Two Phase Commit)不是在XA规范中提出,但是XA规范对其进行了优化,因此统一放到这里进行讲解。而从字面意思来理解,Two Phase Commit,就是将提交(commit)过程划分为2个阶段(Phase):
In Phase 1, the TM asks all RMs to prepare to commit (or prepare) transaction branches. This asks whether the RM can guarantee its ability to commit the transaction branch. An RM may have to query other entities internal to that RM.
If an RM can commit its work, it records stably the information it needs to do so, then replies affirmatively. A negative reply reports failure for any reason. After making a negative reply and rolling back its work, the RM can discard any knowledge it has of the transaction branch.
In Phase 2, the TM issues all RMs an actual request to commit or roll back the transaction branch, as the case may be. (Before issuing requests to commit, the TM stably records the fact that it decided to commit, as well as a list of all involved RMs.) All RMs commit or roll back changes to shared resources and then return status to the TM. The TM can then discard its knowledge of the global transaction.
阶段1:
TM通知各个RM准备提交它们的事务分支。如果RM判断自己进行的工作可以被提交,那就就对工作内容进行持久化,再给TM肯定答复;要是发生了其他情况,那给TM的都是否定答复。在发送了否定答复并回滚了已经的工作后,RM就可以丢弃这个事务分支信息。
以mysql数据库为例,在第一阶段,事务管理器向所有涉及到的数据库服务器发出prepare"准备提交"请求,数据库收到请求后执行数据修改和日志记录等处理,处理完成后只是把事务的状态改成"可以提交",然后把结果返回给事务管理器。
阶段2
TM根据阶段1各个RM prepare的结果,决定是提交还是回滚事务。如果所有的RM都prepare成功,那么TM通知所有的RM进行提交;如果有RM prepare失败的话,则TM通知所有RM回滚自己的事务分支。
以mysql数据库为例,如果第一阶段中所有数据库都prepare成功,那么事务管理器向数据库服务器发出"确认提交"请求,数据库服务器把事务的"可以提交"状态改为"提交完成"状态,然后返回应答。如果在第一阶段内有任何一个数据库的操作发生了错误,或者事务管理器收不到某个数据库的回应,则认为事务失败,回撤所有数据库的事务。数据库服务器收不到第二阶段的确认提交请求,也会把"可以提交"的事务回撤。
XA规范对两阶段提交协议有2点优化:
Protocol Optimisations
• Read-only
An RM can respond to the TM’s prepare request by asserting that the RM was not asked to update shared resources in this transaction branch. This response concludes the RM’s involvement in the transaction; the Phase 2 dialogue between the TM and this RM does not occur. The TM need not stably record, in its list of participating RMs, an RM that asserts a read-only role in the global transaction.
However, if the RM returns the read-only optimisation before all work on the global transaction is prepared, global serialisability1 cannot be guaranteed. This is because the RM may release transaction context, such as read locks, before all application activity for that global transaction is finished.
-
One-phase Commit
A TM can use one-phase commit if it knows that there is only one RM anywhere in the DTP system that is making changes to shared resources. In this optimisation, the TM makes its Phase 2 commit request without having made a Phase 1 prepare request. Since the RM decides the outcome of the transaction branch and forgets about the transaction branch before returning to the TM, there is no need for the TM to record stably these global transactions and, in some failure cases, the TM may not know the outcome.
只读断言
在Phase 1中,RM可以断言“我这边不涉及数据增删改”来答复TM的prepare请求,从而让这个RM脱离当前的全局事务,从而免去了Phase 2。
这种优化发生在其他RM都完成prepare之前的话,使用了只读断言的RM早于AP其他动作(比如说这个RM返回那些只读数据给AP)前,就释放了相关数据的上下文(比如读锁之类的),这时候其他全局事务或者本地事务就有机会去改变这些数据,结果就是无法保障整个系统的可序列化特性——通俗点说那就会有脏读的风险。
一阶段提交
如果需要增删改的数据都在同一个RM上,TM可以使用一阶段提交——跳过两阶段提交中的Phase 1,直接执行Phase 2。
这种优化的本质是跳过Phase 1,RM自行决定了事务分支的结果,并且在答复TM前就清除掉事务分支信息。对于这种优化的情况,TM实际上也没有必要去可靠的记录全局事务的信息,在一些异常的场景下,此时TM可能不知道事务分支的执行结果。
4.2.3 两阶段提交协议(2PC)存在的问题
二阶段提交看起来确实能够提供原子性的操作,但是不幸的是,二阶段提交还是有几个缺点的:
1、同步阻塞问题。两阶段提交方案下全局事务的ACID特性,是依赖于RM的。例如mysql5.7官方文档关于对XA分布式事务的支持有以下介绍:
https://dev.mysql.com/doc/refman/5.7/en/xa.html
A global transaction involves several actions that are transactional in themselves, but that all must either complete successfully as a group, or all be rolled back as a group. In essence, this extends ACID properties “up a level” so that multiple ACID transactions can be executed in concert as components of a global operation that also has ACID properties. (As with nondistributed transactions, SERIALIZABLE may be preferred if your applications are sensitive to read phenomena. REPEATABLE READ may not be sufficient for distributed transactions.)
大致含义是说,一个全局事务内部包含了多个独立的事务分支,这一组事务分支要不都成功,要不都失败。各个事务分支的ACID特性共同构成了全局事务的ACID特性。也就是将单个事务分支的支持的ACID特性提升一个层次(up a level)到分布式事务的范畴。
括号中的内容的意思是: 即使在非分布事务中(即本地事务),如果对操作读很敏感,我们也需要将事务隔离级别设置为SERIALIZABLE。而对于分布式事务来说,更是如此,可重复读隔离级别不足以保证分布式事务一致性。
也就是说,如果我们使用mysql来支持XA分布式事务的话,那么最好将事务隔离级别设置为SERIALIZABLE。 地球人都知道,SERIALIZABLE(串行化)是四个事务隔离级别中最高的一个级别,也是执行效率最低的一个级别。
2、单点故障。由于协调者的重要性,一旦协调者TM发生故障。参与者RM会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
3、数据不一致。在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据不一致性的现象。
由于二阶段提交存在着诸如同步阻塞、单点问题等缺陷,所以,研究者们在二阶段提交的基础上做了改进,提出了三阶段提交。
5 三阶段提交协议(Three-phase commit)
三阶段提交(3PC),是二阶段提交(2PC)的改进版本。参考维基百科:https://en.wikipedia.org/wiki/Three-phase_commit_protocol
与两阶段提交不同的是,三阶段提交有两个改动点。
1、引入超时机制。同时在协调者和参与者中都引入超时机制。
2、在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。也就是说,除了引入超时机制之外,3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
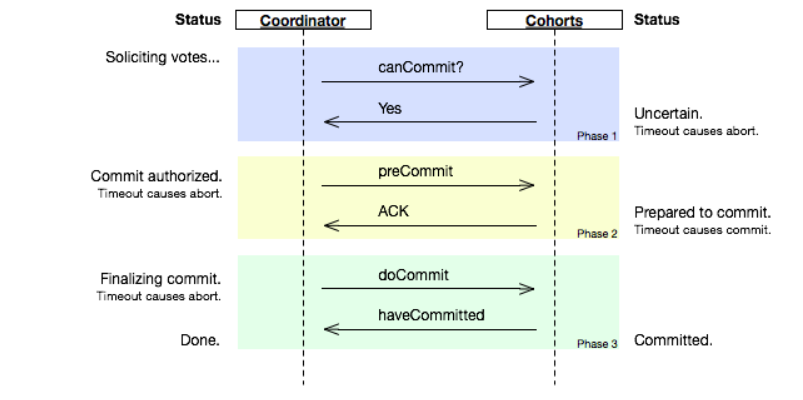
CanCommit阶段
3PC的CanCommit阶段其实和2PC的准备阶段很像。协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
1.事务询问 协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待参与者的响应。
2.响应反馈 参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态。否则反馈No
PreCommit阶段
协调者根据参与者的反应情况来决定是否可以记性事务的PreCommit操作。根据响应情况,有以下两种可能。
假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务的预执行。
1.发送预提交请求 协调者向参与者发送PreCommit请求,并进入Prepared阶段。
2.事务预提交 参与者接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
3.响应反馈 如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。
假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。
1.发送中断请求 协调者向所有参与者发送abort请求。
2.中断事务 参与者收到来自协调者的abort请求之后(或超时之后,仍未收到协调者的请求),执行事务的中断。
doCommit阶段
该阶段进行真正的事务提交,也可以分为以下两种情况。
Case 1:执行提交
1.发送提交请求 协调接收到参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送doCommit请求。
2.事务提交 参与者接收到doCommit请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源。
3.响应反馈 事务提交完之后,向协调者发送Ack响应。
4.完成事务 协调者接收到所有参与者的ack响应之后,完成事务。
Case 2:中断事务 协调者没有接收到参与者发送的ACK响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。
1.发送中断请求 协调者向所有参与者发送abort请求
2.事务回滚 参与者接收到abort请求之后,利用其在阶段二记录的undo信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源。
3.反馈结果 参与者完成事务回滚之后,向协调者发送ACK消息
4.中断事务 协调者接收到参与者反馈的ACK消息之后,执行事务的中断。
在doCommit阶段,如果参与者无法及时接收到来自协调者的doCommit或者rebort请求时,会在等待超时之后,会继续进行事务的提交。(其实这个应该是基于概率来决定的,当进入第三阶段时,说明参与者在第二阶段已经收到了PreCommit请求,那么协调者产生PreCommit请求的前提条件是他在第二阶段开始之前,收到所有参与者的CanCommit响应都是Yes。(一旦参与者收到了PreCommit,意味他知道大家其实都同意修改了)所以,一句话概括就是,当进入第三阶段时,由于网络超时等原因,虽然参与者没有收到commit或者abort响应,但是他有理由相信:成功提交的几率很大。 )
小结:2PC与3PC的区别
相对于2PC,3PC主要解决的单点故障问题,并减少阻塞,因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行commit。而不会一直持有事务资源并处于阻塞状态。但是这种机制也会导致数据一致性问题,因为,由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作。这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
了解了2PC和3PC之后,我们可以发现,无论是二阶段提交还是三阶段提交都无法彻底解决分布式的一致性问题。Google Chubby的作者Mike Burrows说过, there is only one consensus protocol, and that’s Paxos” – all other approaches are just broken versions of Paxos. 意即世上只有一种一致性算法,那就是Paxos,所有其他一致性算法都是Paxos算法的不完整版。后面的文章会介绍这个公认为难于理解但是行之有效的Paxos算法。
6 BASE理论与柔性事务
6.1 经典的分布式系统理论-CAP
2000年7月,加州大学伯克利分校的Eric Brewer教授在ACM PODC会议上提出CAP猜想。Brewer认为在设计一个大规模的分布式系统时会遇到三个特性:一致性(consistency)、可用性(Availability)、分区容错(partition-tolerance),而一个分布式系统最多只能满足其中的2项。2年后,麻省理工学院的Seth Gilbert和Nancy Lynch从理论上证明了CAP。之后,CAP理论正式成为分布式计算领域的公认定理。
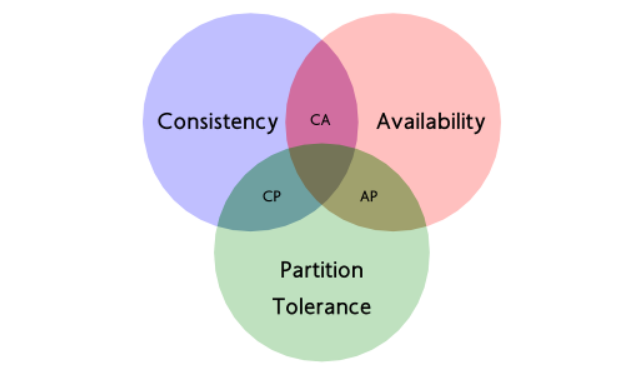
-
一致性
一致性指“all nodes see the same data at the same time”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致,不能存在中间状态。例如对于电商系统用户下单操作,库存减少、用户资金账户扣减、积分增加等操作必须在用户下单操作完成后必须是一致的。不能出现类似于库存已经减少,而用户资金账户尚未扣减,积分也未增加的情况。如果出现了这种情况,那么就认为是不一致的。
关于一致性,如果的确能像上面描述的那样时刻保证客户端看到的数据都是一致的,那么称之为强一致性。如果允许存在中间状态,只要求经过一段时间后,数据最终是一致的,则称之为最终一致性。此外,如果允许存在部分数据不一致,那么就称之为弱一致性。
-
可用性
可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。“有限的时间内”是指,对于用户的一个操作请求,系统必须能够在指定的时间内返回对应的处理结果,如果超过了这个时间范围,那么系统就被认为是不可用的。试想,如果一个下单操作,为了保证分布式事务的一致性,需要10分钟才能处理完,那么用户显然是无法忍受的。“返回结果”是可用性的另一个非常重要的指标,它要求系统在完成对用户请求的处理后,返回一个正常的响应结果,不论这个结果是成功还是失败。
-
分区容错性
分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
小结: 既然一个分布式系统无法同时满足一致性、可用性、分区容错性三个特点,我们就需要抛弃一个,需要明确的一点是,对于一个分布式系统而言,分区容错性是一个最基本的要求。因为既然是一个分布式系统,那么分布式系统中的组件必然需要被部署到不同的节点,否则也就无所谓分布式系统了。而对于分布式系统而言,网络问题又是一个必定会出现的异常情况,因此分区容错性也就成为了一个分布式系统必然需要面对和解决的问题。因此系统架构师往往需要把精力花在如何根据业务特点在C(一致性)和A(可用性)之间寻求平衡。而前面我们提到的X/Open XA 两阶段提交协议的分布式事务方案,强调的就是一致性;由于可用性较低,实际应用的并不多。而基于BASE理论的柔性事务,强调的是可用性,目前大行其道,大部分互联网公司采可能会优先采用这种方案。
6.2 BASE理论
eBay的架构师Dan Pritchett源于对大规模分布式系统的实践总结,在ACM上发表文章提出BASE理论。文章链接:https://queue.acm.org/detail.cfm?id=1394128
BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性(Strong Consistency,CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consitency)。
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的缩写。
1. 基本可用(Basically Available)
指分布式系统在出现不可预知故障的时候,允许损失部分可用性。
2. 软状态( Soft State)
指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性。
3. 最终一致( Eventual Consistency)
强调的是所有的数据更新操作,在经过一段时间的同步之后,最终都能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
BASE理论面向的是大型高可用可扩展的分布式系统,和传统的事物ACID特性是相反的。它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性和BASE理论往往又会结合在一起。
6.3 典型的柔性事务方案
最大努力通知(非可靠消息、定期校对)
可靠消息最终一致性(异步确保型)
TCC(两阶段型、补偿型)
来源:http://www.tianshouzhi.com/api/tutorials/distributed_transaction
欢迎关注公众号 【码农开花】一起学习成长
我会一直分享Java干货,也会分享免费的学习资料课程和面试宝典
回复:【计算机】【设计模式】【面试】有惊喜哦