20172306 哈夫曼编码测试
测试要求
设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
给定一个包含26个英文字母的文件,统计每个字符出现的概率,根据计算的概率构造一颗哈夫曼树。
并完成对英文文件的编码和解码。
要求:
(1)准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率
(2)构造哈夫曼树
(3)对英文文件进行编码,输出一个编码后的文件
(4)对编码文件进行解码,输出一个解码后的文件
(5)撰写博客记录实验的设计和实现过程,并将源代码传到码云
(6)把实验结果截图上传到云班课
哈夫曼树的理解
哈夫曼树是二叉树中很特别的一种,也是最优二叉树,通过某种权值来构造出哈夫曼二叉树,在这个二叉树中,只有叶子节点才是有效的数据节点,其他的非叶子节点是为了构造出哈夫曼而引入的!
哈夫曼编码是一个通过哈夫曼树进行的一种编码,一般情况下,以字符:‘0’与‘1’表示。编码的实现过程很简单,只要实现哈夫曼树,通过遍历哈夫曼树,规定向左子树遍历一个节点编码为“0”,向右遍历一个节点编码为“1”,结束条件就是遍历到叶子节点。
- 引入一个例子,来对哈夫曼树进行理解:
对4,8,12,26,32进行哈夫曼树的构造和编码 - 1.

- 2.
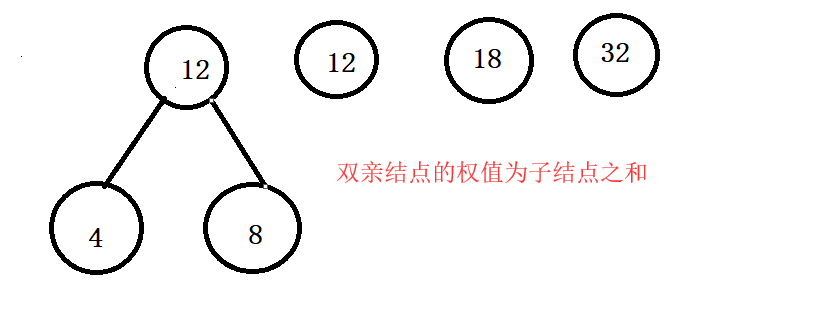
- 3.
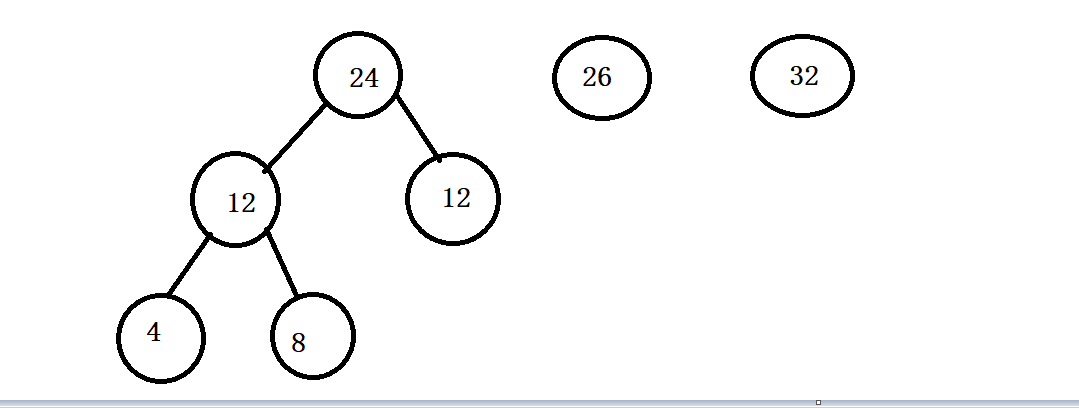
- 4.
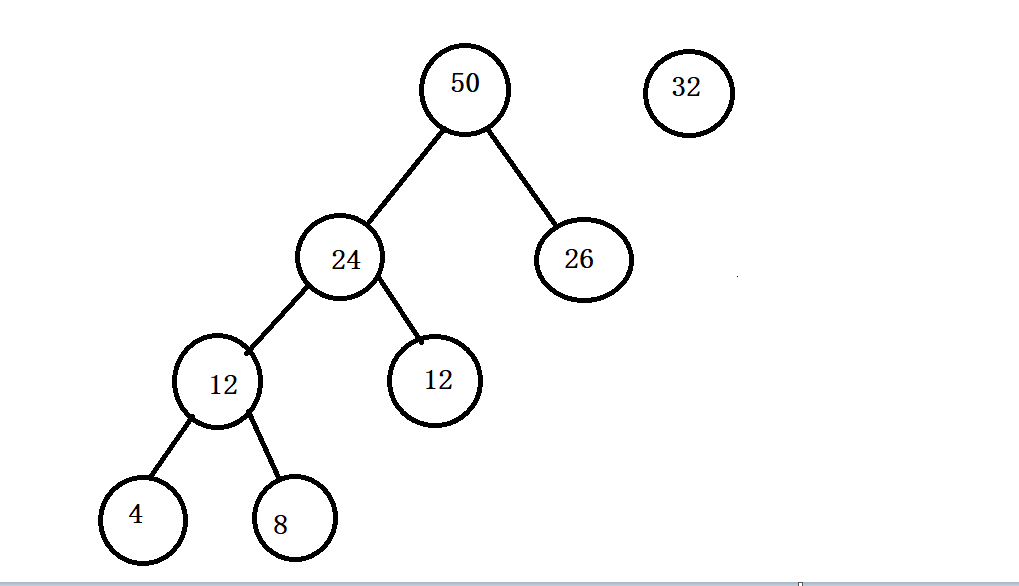
- 5.
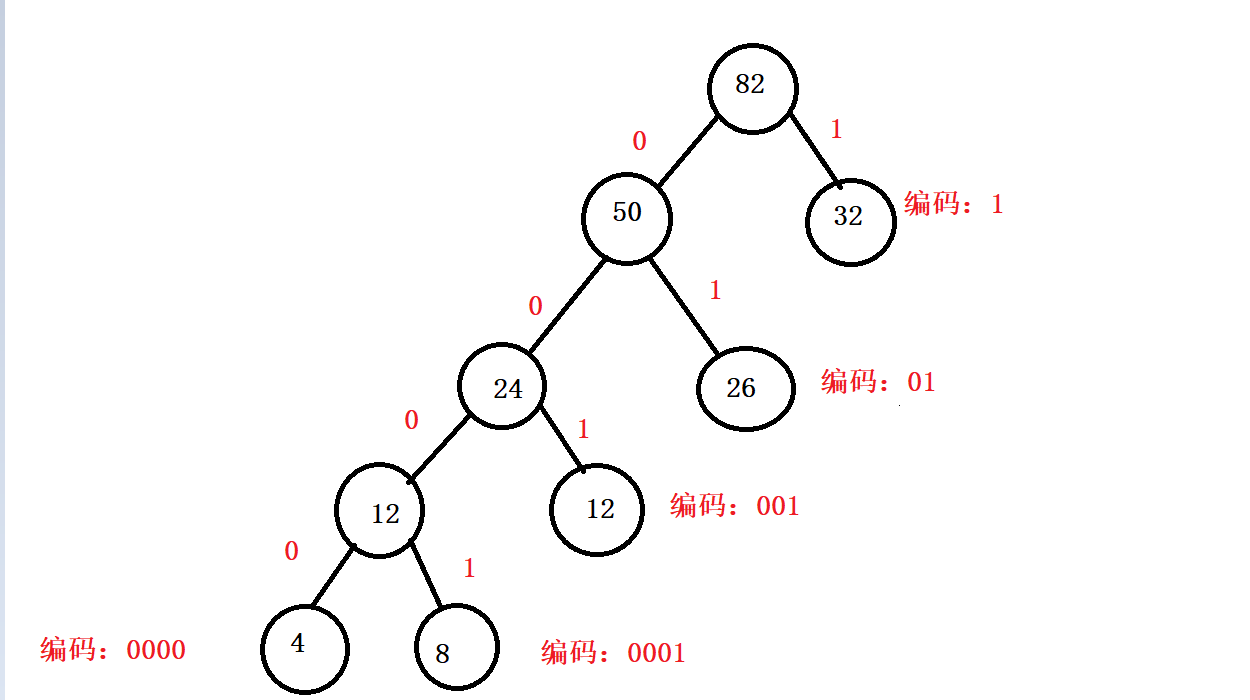
哈夫曼编码
- 第一步当然是要构造一个结点类啦,在这里,我们要定义好字符、权值、左结点、右结点、哈夫曼编码。
public class HuffmanNode<T> implements Comparable<HuffmanNode<T>> {
private char data;//字符
private double weight;//权值
private HuffmanNode left;//左结点
private HuffmanNode right;//右结点
String code;//哈夫曼编码
public HuffmanNode(char data, double weight){
this.data = data;
this.weight = weight;
this.code ="";
}
- 第二步就是开始构造哈夫曼树了
public static HuffmanNode createTree(List<HuffmanNode> nodes) {
// 只要nodes数组中有2个以上的节点
while (nodes.size() > 1) {
//这个是将结点进行排序,这个实现,是在结点类中自己写了一个比较的方法
Collections.sort(nodes);
//左侧编码为0,将左孩子定义为列表中的倒数第二个
HuffmanNode left = nodes.get(nodes.size() - 1);
//右侧编码为1,右孩子为列表中的倒数第一个
HuffmanNode right = nodes.get(nodes.size() - 2);
//那么我们知道,他们的双亲结点就是他们的权值之和
HuffmanNode parent = new HuffmanNode('无', left.getWeight() + right.getWeight());
//这里把双亲结点就放进去了
parent.setLeft(left);
left.setCode("0");
parent.setRight(right);
right.setCode("1");
//删除权值最小的两个节点
nodes.remove(left);
nodes.remove(right);
//将新节点加入到集合中
nodes.add(parent);
}
return nodes.get(0);
}
- 接下来我们就要考虑输出编码啦
public static List<HuffmanNode> breadth(HuffmanNode root) {//这里利用了广度优先遍历的内容
List<HuffmanNode> list = new ArrayList<HuffmanNode>();
Queue<HuffmanNode> queue = new ArrayDeque<HuffmanNode>();
//如果根结点存在,那么我们就将根放入列表中
if (root != null) {
queue.offer(root);
root.getLeft().setCode(root.getCode() + "0");
root.getRight().setCode(root.getCode() + "1");
}
//如果队列不是空的,那么我们就队尾放进列表中
while (!queue.isEmpty()) {
list.add(queue.peek());
HuffmanNode node = queue.poll();
//如果左子节点不为null,将它加入到队列
if (node.getLeft() != null) {
queue.offer(node.getLeft());
node.getLeft().setCode(node.getCode() + "0");
}
//如果右子节点不为null,将它加入到队列
if (node.getRight() != null) {
queue.offer(node.getRight());
node.getRight().setCode(node.getCode() + "1");
}
}
return list;
}
- 最后就是进行测试了
- 在文件中分别写出字符和哈夫曼的编码
- 通过一些循环的方式,对编码进行输出和解密
public static void main(String[] args) throws IOException {
//把字符集从文件中读出来,并保存在一个数组里
File file = new File("C:\Users\DELL\IdeaProjects\20172306\text1.txt");
Reader reader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(reader);
String temp = bufferedReader.readLine();
char characters[] = new char[temp.length()];
for (int i = 0; i < temp.length(); i++) {
characters[i] = temp.charAt(i);
}
System.out.println("原字符集为:" + Arrays.toString(characters));
double frequency[] = new double[27];//26个字母加空格
int numbers = 0;//空格的个数
for (int i = 0; i < characters.length; i++) {
if (characters[i] == ' ') {
numbers++;
}
frequency[26] = (float) numbers / characters.length;
}
System.out.println("字符集为");
for (int j = 97; j <= 122; j++) {
int number = 0;//给字母计数
for (int m = 0; m < characters.length; m++) {
if (characters[m] == (char) j) {
number++;
}
frequency[j - 97] = (float) number / characters.length;
}
System.out.print((char) j + ",");
}
System.out.println("空格");
System.out.println("每个字符的概率是" + "
" + Arrays.toString(frequency));
double result = 0.0;
for (int z = 0; z < 27; z++) {
result += frequency[z];
}
System.out.println("总概率之和为" + result);
List<HuffmanNode> nodes = new ArrayList<HuffmanNode>();
for (int o = 97; o <= 122; o++) {
nodes.add(new HuffmanNode((char) o, frequency[o - 97]));
}
nodes.add(new HuffmanNode(' ', frequency[26]));
HuffmanNode root = HuffmanTree.createTree(nodes);
System.out.println("哈夫曼树为:");
System.out.println(breadth(root));
//对英文文件进行编码,输出一个编码后的文件
String result1 = "";
List<HuffmanNode> temp1 = breadth(root);
for (int i = 0; i < characters.length; i++) {
for (int j = 0; j < temp1.size(); j++) {
if (characters[i] == temp1.get(j).getData()) {
result1 += temp1.get(j).getCode();
}
}
}
System.out.println("对文件进行编码后的结果为:");
System.out.println(result1);
File file2 = new File("C:\Users\DELL\IdeaProjects\20172306\text2.txt");
Writer writer = new FileWriter(file2);
writer.write(result1);
writer.close();
//对英文文件进行解码,输出一个解码后的文件
List<String> newlist = new ArrayList<>();
for(int m=0;m < temp1.size();m++)
{
if(temp1.get(m).getData()!='无')
newlist.add(String.valueOf(temp1.get(m).getData()));
}
System.out.println("字符:"+newlist);
List<String> newlist1 = new ArrayList<>();
for(int m=0;m < temp1.size();m++)
{
if(temp1.get(m).getData()!='无')
newlist1.add(String.valueOf(temp1.get(m).getCode()));
}
System.out.println("对应编码:"+newlist1);
//先从编完码的文件中读出密文
FileReader fileReader = new FileReader("C:\Users\DELL\IdeaProjects\20172306\text2.txt");
BufferedReader bufferedReader1 = new BufferedReader(fileReader);
String secretline = bufferedReader1.readLine();
//将读出的密文存在secretText列表中
List<String> secretText = new ArrayList<String>();
for (int i = 0; i < secretline.length(); i++) {
secretText.add(secretline.charAt(i) + "");
}
//解密
String result2 = "";
String current="";
while(secretText.size()>0) {
current = current + "" + secretText.get(0);
secretText.remove(0);
for (int p = 0; p < newlist1.size(); p++) {
if (current.equals(newlist1.get(p))) {
result2 = result2 + "" + newlist.get(p);
current="";
}
}
}
System.out.println("解码后的结果:"+result2);
File file3 = new File("C:\Users\DELL\IdeaProjects\20172306\text3.txt");
Writer writer1 = new FileWriter(file3);
writer1.write(result2);
writer.close();
}
- 最后的测试结果就是


码云链接
https://gitee.com/CS-IMIS-23/20172306/tree/master/src/wek10/Haffman