20172306 2018-2019-2 《Java程序设计与数据结构》第九周学习总结
教材学习内容总结
- 无向图
-
图是由结点和这些结点之间的连接构成

-
就图来说,结点叫做顶点,结点之间的连接是边,一般用名字或标签来表示顶点。
-
无序图是一种边为无序结点对的图,如果图中的两个顶点之间有一条连通边,则称为这两个顶点是邻接的,邻接顶点有时也称为邻居,连通一个顶点及其自身的边称为自循环或环。
-
路径是图中的一系列边,每条边连通两个顶点。路径的长度是该路径中边的条数(或者是顶点数减去1)
-
树是图的一种。
-
如果无向图中任意两个顶点之间都存在一条路径,则认为这个无向图是连通的。
-

-
如果无向图拥有最大数目的连通顶点的边,则认为这个无向图是完全的。对有n个顶点的无向图,要使该图为完全的,要求有n(n-1)/2条边(假设其中没有边是自循环的)
- 对于这个n(n-1)/2这个值的由来:
- 对于图来说,第一个顶点最多有(n-1)条边和其他结点相连,第二个顶点最多有(n-2)条边和其他结点相连,以此类推,那最后如果要是图是完全的,就需要(n-1)+(n-2)+(n-3)+...+3+2+1,最后它们求和结果就是n(n-1)/2。
- 对于这个n(n-1)/2这个值的由来:
-
环路是一种首项点和末项点相同且没有重边的路径。没有环路的图称为无环的。
-
无向树是一种连通的无环无向图,其中一个元素被指定为树根。
-
有向图
- 有向图有时也称为双向图,它是一种边为有序顶点对的图
- 有向图连通的例子:
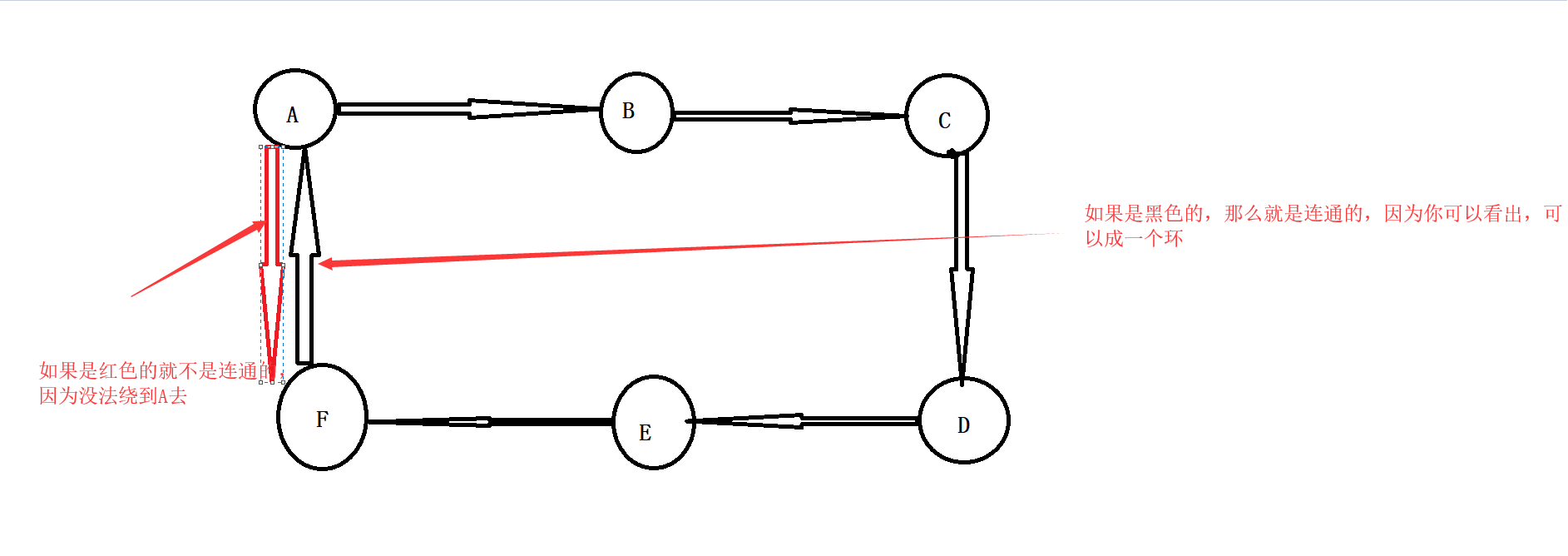
- 如果有向图中没有环路,且有一条从A到B的边,则可以把顶点A安排在顶点B之前,这种排列得到的顶点次序称为拓扑序
- 有向树是一种指定了一个元素作为树根的有向图,该图还有如下属性:
- 不存在其他顶点到树根的连接
- 每个非树根元素恰好有一个连接
- 树根到每个其他顶点都有一条路径
-
网络
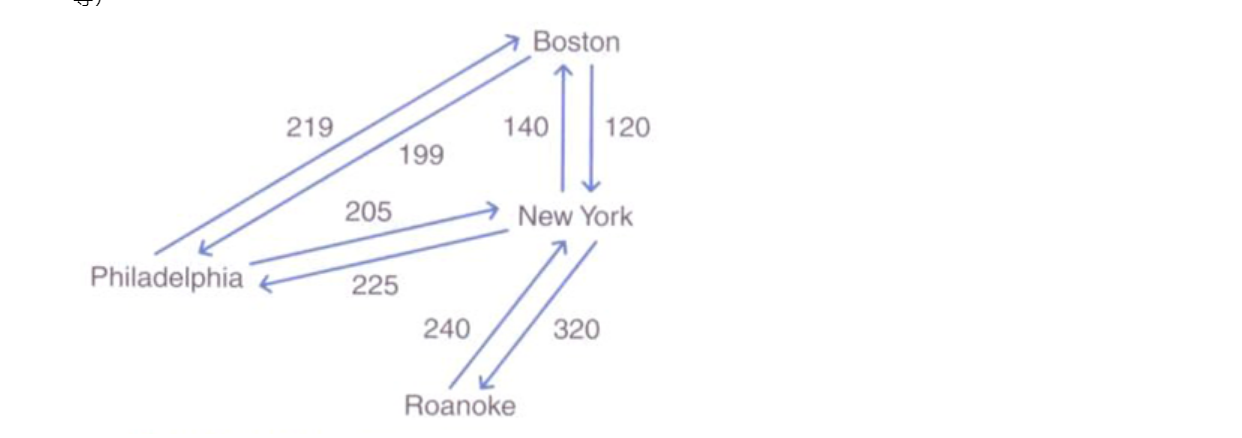
- 网络或称为加权图,是一种每条边都带有权重或代价的图,加权图中的路径权重是该路径中各条边权重的和。
- 对于网络,我们将用一个三元组来表示每条边,这个三元组中包括起始顶点、终止顶点和权重。对于无向网络来说,起始顶点与终止顶点可以互换。
-
常用的图算法
-
我们在进行图的存储结构的时候有两种方式:
-
一种是利用基于二维数组的邻接矩阵表示法

-
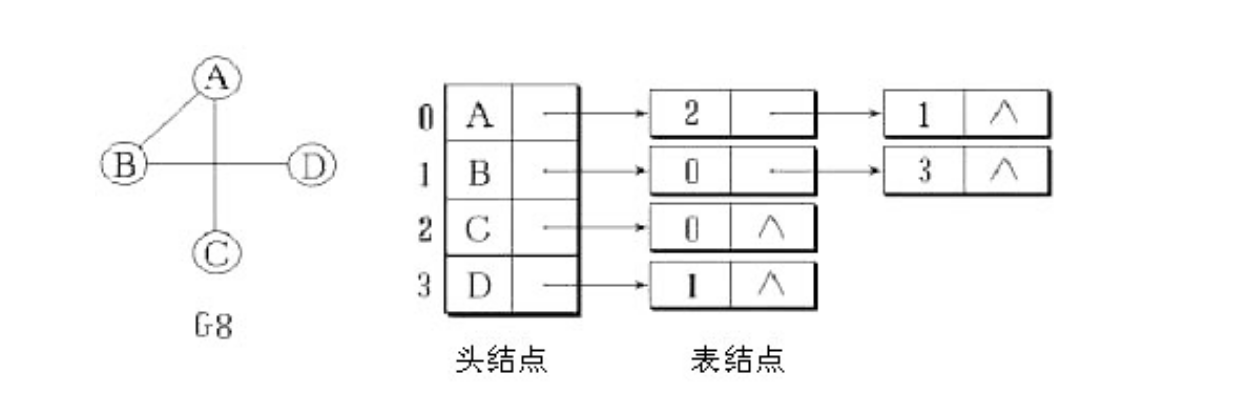
一种就是基于链表的的邻接表
-
-
遍历有两种:广度优先遍历和深度优先遍历(图的遍历和树的遍历有一点不同是:图中不存在根结点,所以图的遍历可以从其中的任一顶点开始)
-
广度优先遍历(类似于树的层次遍历)这是一个对于广度优先遍历的一个很详细很详细的过程
- (1)利用队列管理遍历;利用无序列表构造出结果。
- (2)起始顶点进入队列,同时标记该顶点为已访问的
- (3)在循环中,从队列中取出首顶点然后添加到列表的末端
- (4)所有与当前顶点邻接的尚未被标记的依次进入队列并被标记,然后再进入列表中
- (5)重复上面的循环,直到队列为空
-
就广度优先遍历,举一个例子:
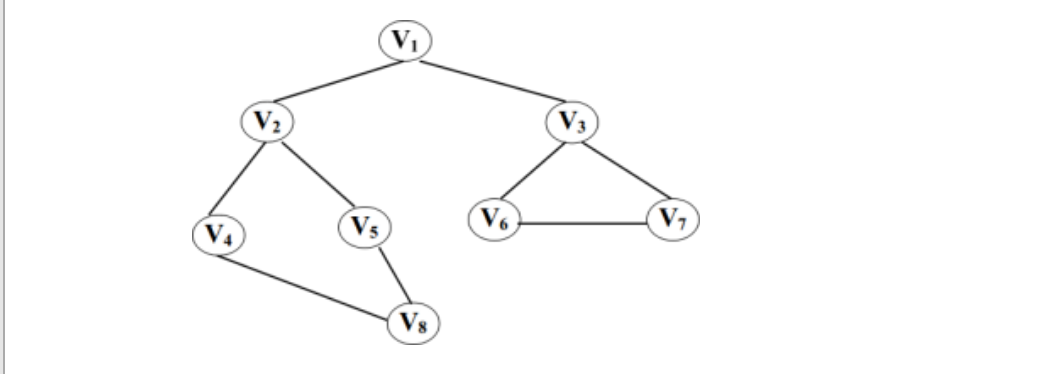
- 就该图而言,走一下广度优先遍历的过程:
- a.将V1加入队列,取出V1,并标记为true(即已经访问),然后从队列中将V1取出,放进列表的末端。
- b. 将其邻接点加进入队列,则 <—[V2 V3],并标记为true(即已经访问),从队列取出V2,放进列表中。
- c.将其未访问过的邻接点加进入队列,则 <—[V4 V5],并标记为true(即已经访问),取出V3,放进列表中。
- d.将其未访问过的邻接点加进入队列,则 <—[V6 V7],并标记为true(即已经访问),取出V4,放进列表中。
- e.将其未访问过的邻接点加进入队列,则 <—[V8],并标记为true(即已经访问),取出V5,放进列表中,
- f.因为其邻接点已经加入队列,则 <—[ ],取出V6,放进列表中。
- g.取出V7,放进列表中。
- h.取出V8,放进列表中。
- i.遍历结束
- 就该图而言,走一下广度优先遍历的过程:
-
-
该例子是无向图而言的,但和有向图是很像的
-
深度优先遍历(类似于树的前序遍历)
- (1)利用栈管理遍历,利用无序列表构造出结果
- (2)起始顶点进入栈,同时标记该顶点为已访问的
- (3)在循环中,从栈中取出首顶点添加到列表的末端
- (4)所有与当前顶点邻接的尚未被标记的依次进入栈中,然后再从栈中取出进入列表,之后被标记
- (5)重复上面的循环,直到队列为空
-
就深度优先遍历,举一个例子:
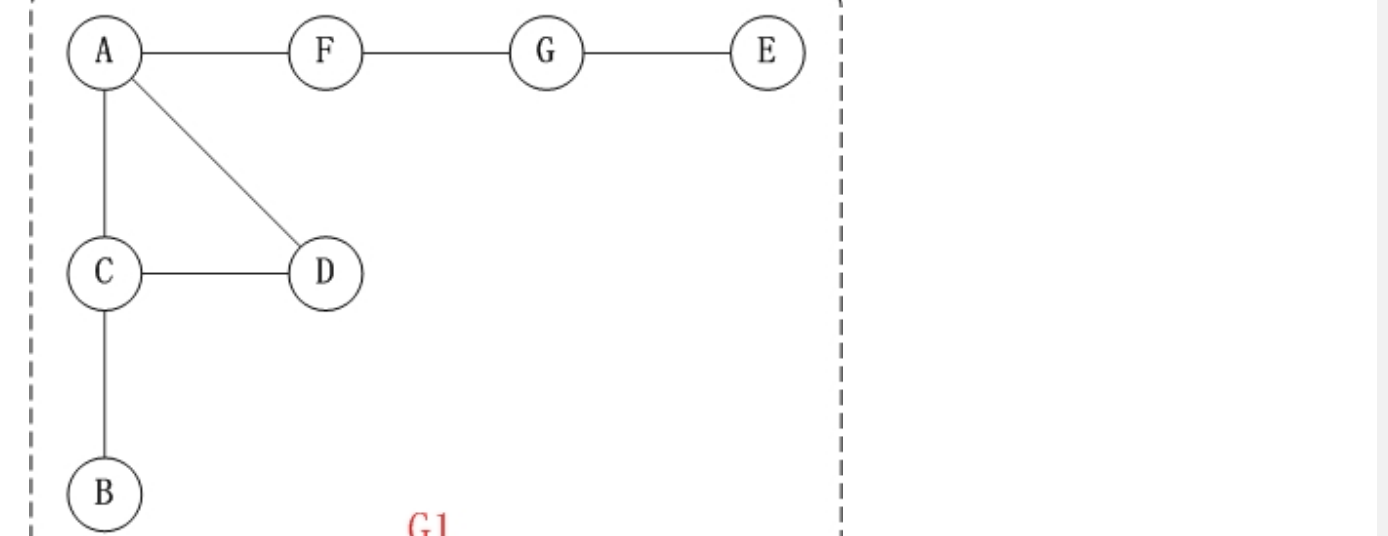
- 就该图而言,走一遍深度优先遍历的过程:
- a.以A为起始顶点,进入栈,标记为已访问的,然后从栈中取出,放进列表中
- b.接着访问邻接点C,进入栈,然后放进列表,标记为已访问
- c.接着访问邻接点B,进入栈,然后放进列表,标记为已访问
- d.接着B已经没有邻接点了,而之前的C还有,所以访问邻接点D,进入栈,然后放进列表,标记为已访问
- e.D没有邻接点了,但是之前的A还有,所以访问邻接点F,进入栈,然后放进列表,标记为已访问
- f.接着访问邻接点G,进入栈,然后放进列表,标记为已访问
- g.最后是邻接点E,进入栈,然后放进列表,标记为已访问
- h.遍历结束
- 就该图而言,走一遍深度优先遍历的过程:
-
-
该例子是无向图而言的,有向图是很像的
-
测试连通性:无论哪个为起始顶点,当且仅当广度优先遍历中的顶点数目等于图中的顶点数目时,该图才是连通的
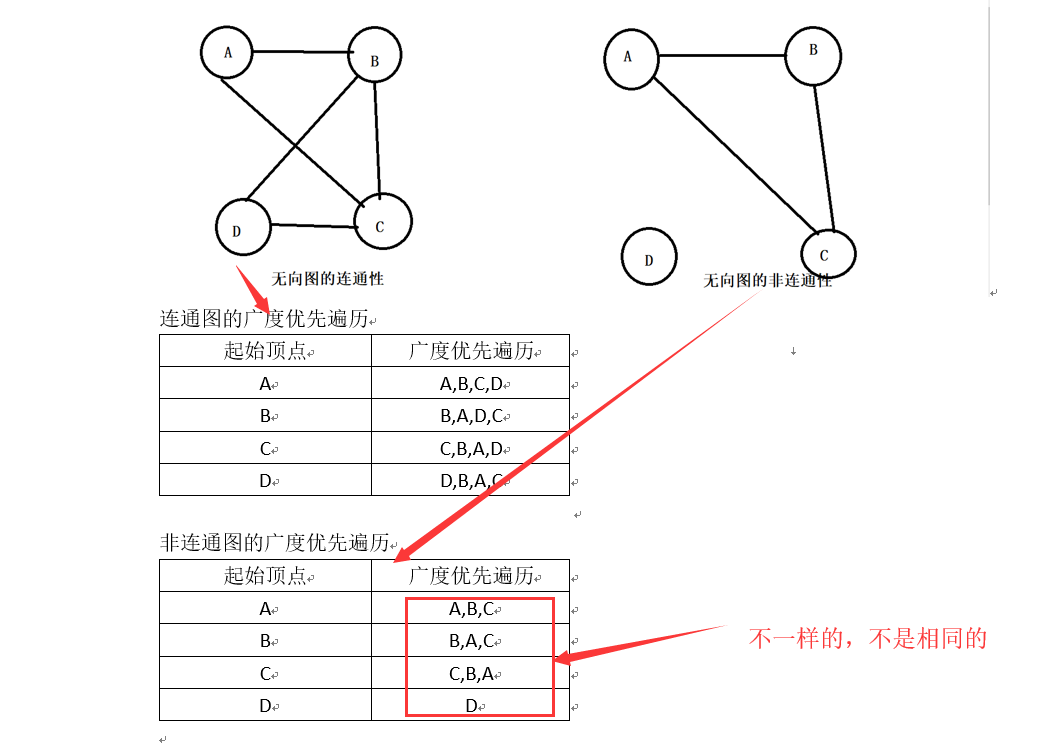
-
最小生成树
- 生成树是一棵含有图中所有顶点和部分变(但可能不是所有边)的树
- 最小生成树其边的权重总和小于或等于同一图中其他任何一颗生成树的权重总和
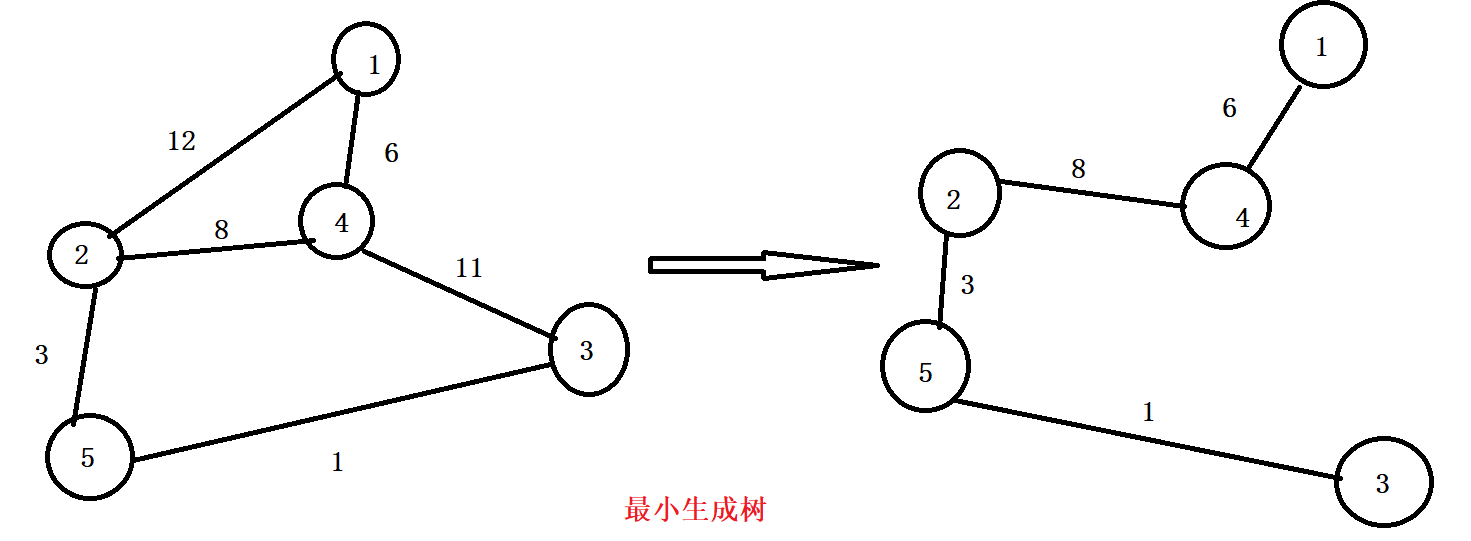
- 计算最小生成树一般有两种算法:Kruskal和Prim算法
-
第一种:Prim算法
-
算法描述:
- 1.在一个加权连通图中,顶点集合V。边集合为E
-
- 随意选出一个点作为初始顶点,标记为visit,计算全部与之相连接的点的距离,选择距离最短的,标记visit.
-
- 反复以下操作,直到全部点都被标记为visit:
- 4.在剩下的点中。计算与已标记visit点距离最小的点,标记visit,证明增加了最小生成树

-
第二种:Kruskal算法
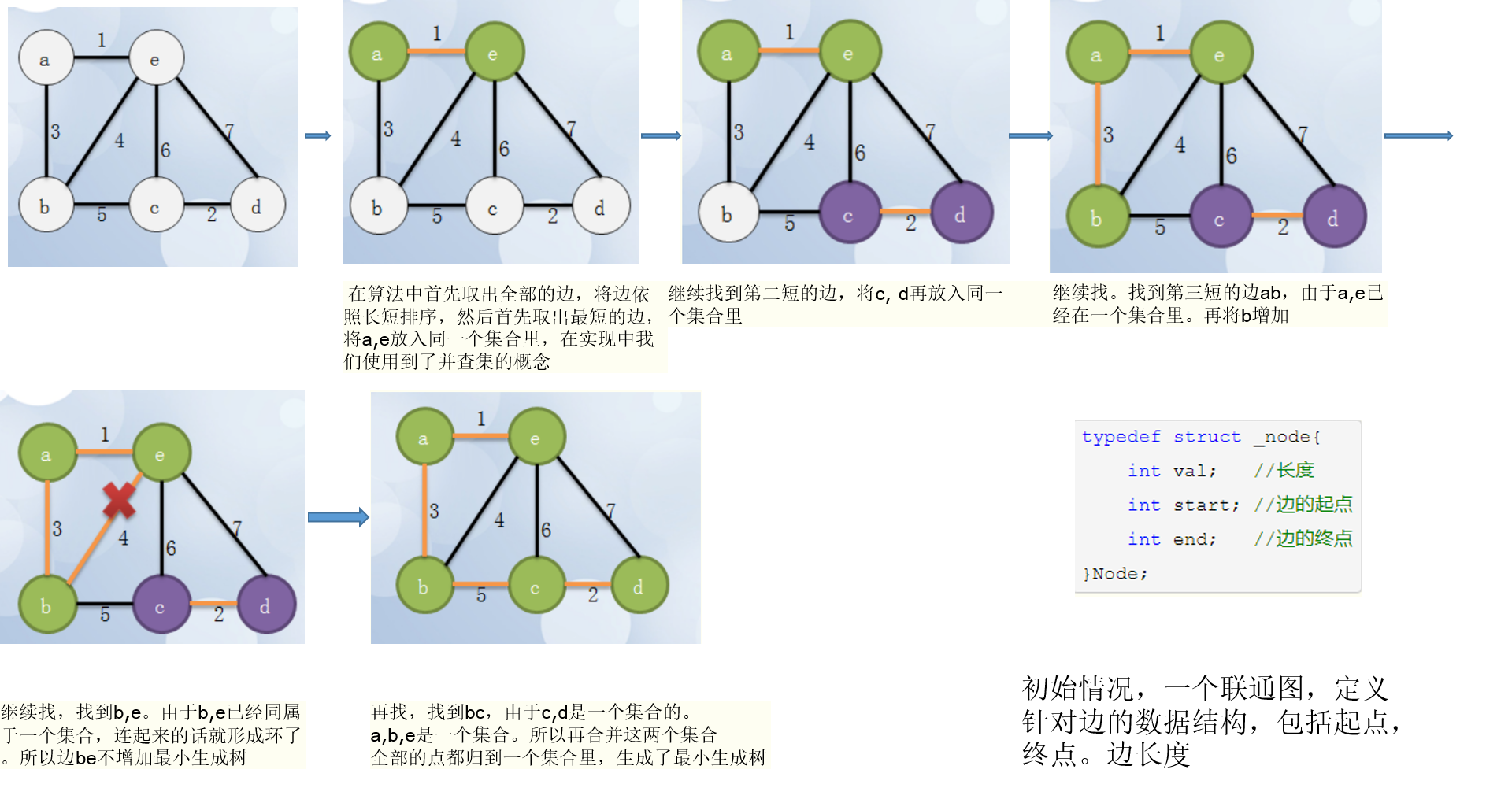
-
-
判断最短路径
- 第一种方法:判定起始顶点与目标顶点之间的字面意义上的最短路径,也就是两个顶点间的最小边数
- 第二种方法:Dijkstra算法
-
基本思路:Dijkstra算法采用的是一种贪心的策略,声明一个数组dis来保存源点到各个顶点的最短距离和一个保存已经找到了最短路径的顶点的集合:T,初始时,原点 s 的路径权重被赋为 0 (dis[s] = 0)。若对于顶点 s 存在能直接到达的边(s,m),则把dis[m]设为w(s, m),同时把所有其他(s不能直接到达的)顶点的路径长度设为无穷大。初始时,集合T只有顶点s。 然后,从dis数组选择最小值,则该值就是源点s到该值对应的顶点的最短路径,并且把该点加入到T中,OK,此时完成一个顶点, 然后,我们需要看看新加入的顶点是否可以到达其他顶点并且看看通过该顶点到达其他点的路径长度是否比源点直接到达短,如果是,那么就替换这些顶点在dis中的值。 然后,又从dis中找出最小值,重复上述动作,直到T中包含了图的所有顶点。
-
例子:

-
过程:
-
我们先声明一个dis数组,该数组初始化的值为:

-
(1)我们的顶点集T的初始化为:T={v1}。既然是求 v1顶点到其余各个顶点的最短路程,那就先找一个离V1最近的顶点。通过数组 dis 可知当前离v1顶点最近是 v3顶点。当选择了V2顶点后,dis[2](下标从0开始)的值就已经从“估计值”变为了“确定值”,即 v1顶点到 v3顶点的最短路程就是当前 dis[2]值。将V3加入到T中。因为目前离 v1顶点最近的是 v3顶点,并且这个图所有的边都是正数,那么肯定不可能通过第三个顶点中转,使得 v1顶点到 v3顶点的路程进一步缩短了。因为 v1顶点到其它顶点的路程肯定没有 v1到 v3顶点短。
既然确定了一个顶点的最短路径,下面我们就要根据这个新入的顶点V3会有出度,发现以v3 为弧尾的有: < v3,v4 >,那么我们看看路径:v1–v3–v4的长度是否比v1–v4短,其实这个已经是很明显的了,因为dis[3]代表的就是v1–v4的长度为无穷大,而v1–v3–v4的长度为:10+50=60,所以更新dis[3]的值,得到如下结果:
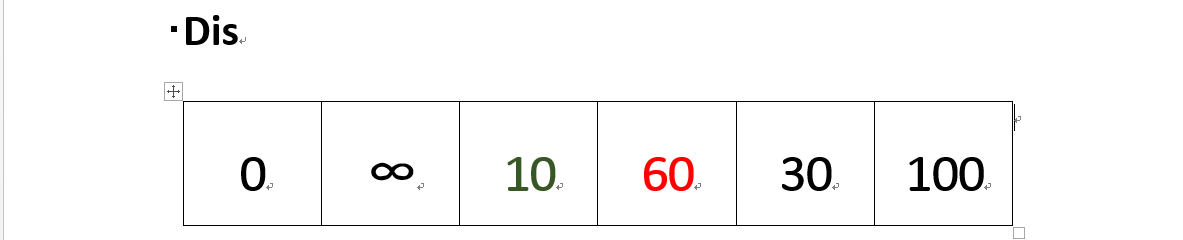
-
(2)dis[3]要更新为 60。即 v1顶点到 v4顶点的路程即 dis[3]。然后,我们又从除dis[2]和dis[0]外的其他值中寻找最小值,发现dis[4]的值最小,通过之前的内容,可以知道v1到v5的最短距离就是dis[4]的值,然后,我们把v5加入到集合T中,然后,考虑v5的出度是否会影响我们的数组dis的值,v5有两条出度:< v5,v4>和 < v5,v6>,然后我们发现:v1–v5–v4的长度为:50,而dis[3]的值为60,所以我们要更新dis[3]的值.另外,v1-v5-v6的长度为:90,而dis[5]为100,所以我们需要更新dis[5]的值。更新后的dis数组如下图:

-
(3)然后,继续从dis中选择未确定的顶点的值中选择一个最小的值,发现dis[3]的值是最小的,所以把v4加入到集合T中,此时集合T={v1,v3,v5,v4},然后,考虑v4的出度是否会影响我们的数组dis的值,v4有一条出度:< v4,v6>,然后我们发现:v1–v5–v4–v6的长度为:60,而dis[5]的值为90,所以我们要更新dis[5]的值,更新后的dis数组如下图:

-
(4)然后,我们使用同样原理,分别确定了v6和v2的最短路径,最后dis的数组的值如下:

-
-
-
图的实现策略
- 图的方法和树中的很类似。会有size、isEmpty、toString、find、最短路径的操作、判定两顶点间是否邻接的操作、构造最小生成树的操作、测试连通性的操作、两种遍历方法的操作
- 对图结点来说,由于每个结点可以有多达n-1条边与其他结点相连,因此最好用一种类似于链表的动态结点来存储每个结点带有的边,这种链表称为邻接列表
- 邻接矩阵:一种二维数组,其中每个单元都表示了图中两个顶点的交接情况,对于无向图,数组中的每个单元是一个布尔值,对于加权图,在数组中还存储了权重
- 对于无向图来说,它是双方向的,所以我们在做邻接矩阵的时候,其实只需要矩阵对角线的一侧即可
- 对于有向图来说,就和无向图不同,就根据箭头之间的邻接来确定布尔值。

-
教材学习中的问题和解决过程
-
问题1:在看到有向图时,书中有一个叫拓扑序,我没有看懂它对它的描写,不知道什么意思
-
问题1解决方案:我上网找了有关的知识,发现拓扑排序是指由某个集合上的一个偏序得到该集合上的一个全序的操作。拓扑排序常用来确定一个依赖关系集中,事物发生的顺序。拓扑排序是对有向无环图的顶点的一种排序,它使得如果存在一条从顶点A到顶点B的路径,那么在排序中B出现在A的后面。
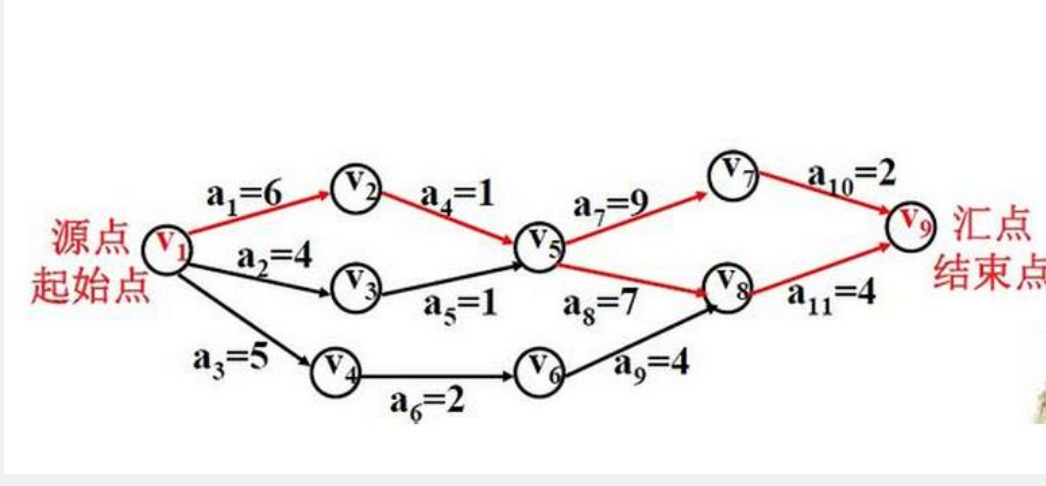
-
问题1解决方案补充:这个问题我是在老师讲课之前写的,老师在上课的时候也讲了这个,而且我发现他讲的和我查到的有不同的知识,我觉得他的PPT的知识对这个也是一个补充。还有我后来又看了郭恺的教材问题,他也对拓扑序进行了解答,我觉得他的也很清楚。
郭恺的博客 -
问题2:我在看代码的时候有一处我有点看不懂,在广序优先遍历和深度优先遍历的开头都有这几行代码,我不懂,为什么就返回迭代的了呢?
if (!indexIsValid(startIndex)) {
return rls.iterator();
}
-
问题2解决方案:后来在后续的看书中发现,indexIsValid是一个方法,用来判断这个起始顶点startIndex是否有效,如果有效,才会进行下面的操作,如果无效,其实就是返回空,所以其实return可以为null,但是由于我们是要用迭代器进行输出的,所以我们返回的是迭代器而不是null。
-
问题3:最开始看书的时候,我对于最小生成树的那段算法,因为全是文字描写,我不懂
-
问题3解决方案:我在马原课下课问了谭鑫,他简单的给我讲了一下,后来我又上网看了看具体的画图的过程,懂得了,具体总结在课本总结中了。还有,我觉得这种东西,画图来表示过程比较容易懂。
代码调试中的问题和解决过程
- 问题1:在做PP15.7时候,我很懵,我不知道要干什么。
- 问题1解决方案:后来因为很多人都有疑惑,所以一起讨论一下,就知道其实和之前的区别也不是特别大,只不过这里我们需要加上权重,即每条边都不是泛指了,开始有它自己的作用了,所以会有加边的时候把weight加上,还有就是之前我的总结中写到了要算最短路径有两种方法,我觉得我有一个问题就是我懂怎么做这个流程,也知道原理但是就是一写就蒙圈,就不知道怎么写,我就又再一次的问了谭鑫(没办法,行策坐我旁边,他也很苦恼),他跟我说他让我学习侯泽洋的,他说侯泽洋写的好,所以我就学习了侯泽洋的代码,确实很强啊!下面是我对这段代码的理解:
private double dijkstra(int index1,int index2) {
int[] previous = new int[numVertices];//定义一个顶点数量的一个数组
Double[] distance = new Double[numVertices];//定义一个距离的数组
boolean[] flag = new boolean[numVertices];
for (int i = 0; i < numVertices; i++) {
flag[i] = false;//i的最短路径没找到
previous[i] = 0;//i的前驱顶点是0
distance[i] = adjMatrix[index1][i];//index1到i的权重值
}
//对顶点先初始化
flag[index1] = true;
distance[index1] = 0.0;
int k = 0;
StackADT<Integer> stack = new LinkedStack<Integer>();
//在未找到最短时找最近的顶点
for (int i = 1; i < numVertices; i++) {
Double min = Double.POSITIVE_INFINITY;
for (int j = 0; j < numVertices; j++) {
if (flag[j]==false && distance[j]<min) {
min = distance[j];
k = j;
}
}
//顶点k被标记为true
flag[k] = true;
//对得到的进行新的更新
for (int j = 0; j < numVertices; j++) {
double temp = (adjMatrix[k][j]==Double.POSITIVE_INFINITY ?Double.POSITIVE_INFINITY : (min + adjMatrix[k][j]));
if (flag[j]==false && (temp<distance[j]) ) {
distance[j] = temp;
previous[j] = k;
}
}
}
//输出最短路径的结果
int index = index2;
stack.push(index);
do
{
index = previous[index];
stack.push(index);
}
while (index != index1);
if(distance[index2]<Double.POSITIVE_INFINITY)
{
String result = "";
while (!stack.isEmpty())
result+=vertices[stack.pop()]+"-";
System.out.println("最便宜的路径为:"+result.subSequence(0,result.length()-1));
}
return distance[index2];
}
代码托管

上周考试错题总结
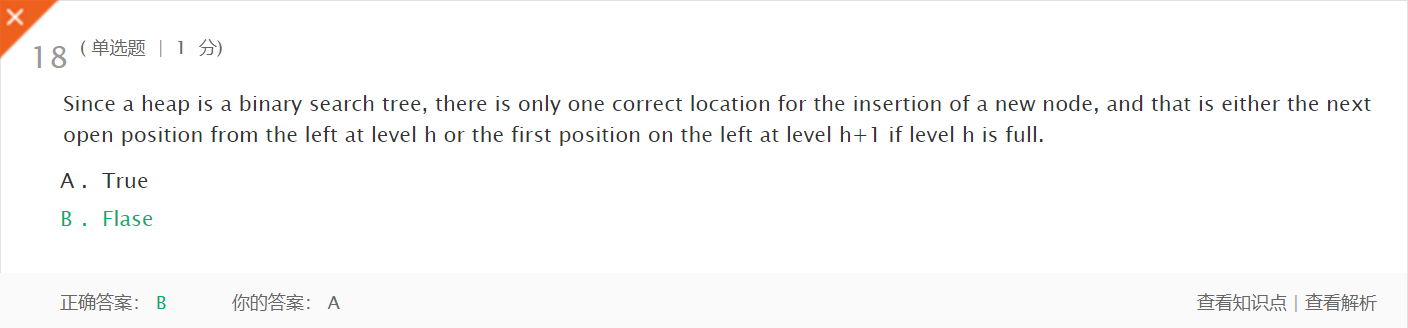
- 翻译:因为堆是二进制搜索树,所以只有一个正确的位置来插入一个新节点,如果h级是满的,则是左侧h级的下一个打开位置,或者是左侧h+1层的第一个位置。
- 正确:原因其实是堆是具有完整性的
结对及互评
结对
-
博客中值得学习的或问题:
- 我觉得他的问题提的很好,而且最近的博客中,都可以看出他有认真的找问题的答案
-
代码中值得学习的或问题:
- 他的代码我们一起学习的,我觉得他还是要继续提升的,和我一起!
点评过的同学博客和代码
- 本周结对学习情况
- 20172325
- 结对学习内容
- 一起学习了第十五章的内容
- 一起琢磨书中代码的含义
- 一起编写课后的作业
其他(感悟、思考等,可选)
这一章我看了书,是我们学习的最后一章了,这一章是老师说了很久的图,我觉得其实和树有很大的联系,而且这章我虽然在做课后作业时还是有很多困难,不知道怎么做或者不知道下步该做些什么,但是这一章书中的代码我大部分都了解了,还是很开心滴。希望在接下来的结对编程中,自己能够努力和别人学习,自己不拖后腿,加油!!!
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 6/6 | |
| 第二周 | 985/985 | 1/1 | 18/24 | |
| 第三周 | 663/1648 | 1/1 | 16/40 | |
| 第四周 | 1742 /3390 | 2/2 | 44/84 | |
| 第五周 | 933/4323 | 1/1 | 23/107 | |
| 第六周 | 1110/5433 | 2/2 | 44/151 | |
| 第七周 | 1536/6969 | 1/1 | 56/207 | |
| 第八周 | 1403/8372 | 2/2 | 60/267 | |
| 第九周 | 1979/10351 | 1/1 | 50/317 |