算法中,递归是一种非常重要的概念,它在处理很多问题中都具有非常简洁优雅的程序实现,同时,使用递归解决一些问题解决方案依赖于同样方法步骤的过程非常简单快速(当然,前提是理解了递归的整个过程)。
然而,刚刚接触递归这个概念时,很多人都会觉得有点难以理解:自己调用自己,不断循环,直到某个条件终结递归?这尼玛什么意思啊?确实,本人刚接触递归时也是难以适应,会感觉非常难以理解和接收,怎么重复调用自己,就将所需要解决的问题解决了呢?感觉自己调用自己,不是在原地踏步吗?本质并没有变啊?怎么问题就解决了呢?
ok,废话不多说,现在将自己学习递归的过程简单记录下,也顺便复习下递归。
一、递归的概念
下面,本人从几个方面阐述个人对递归的一些理解。
1、从解决什么问题角度理解递归。
学习递归,我们先需要了解,什么时候可以用递归解决。其实,递归的过程,是自己调用自己,归根到底就是:重复上一个步骤,直到满足停止条件。所以,如果我们遇到这样一种情况:我需要解决一个问题,这个问题解决的方案又依赖于同样步骤的解决方案,但是被依赖的方案的条件变了。好吧,有点绕,举个例子:阶乘的递归算法代码如下:
//递归例子:阶乘
public static int factoral(int n){
if(n==1){
//停止递归的条件
return 1;
}
return n * factoral(n-1);
}
可以这样理解:现在我要解决n!的运算问题,但是呢,我如果要算n!的阶乘,我依赖于算出(n-1)!的结果,而(n-1)!的结果计算方法其实和n!的结果的计算方法具有一样的计算步骤,只是,方案的传入条件(方法的传入参数发生了改变),这时,我们就可以利用递归了。当然,我们使用递归的前提是:我们必须有个终止条件,而这个终止条件体现出这样一种概念:递归中,必须知道递归调用的传入条件(这里是传入的参数n)达到某个参数(这里是1)时,对应的结果(这里是对应地知道了1!=1),这样,递归便能根据根据这个临界条件(对应if+return)进行重复工作(对应递归运算过程的出栈过程),求出对应结果。
OK,这个第一种方法理解不了没关系,还可以利用下面第二种方法理解(貌似感觉下面的几种方法自己都是在说同样的东西,只是换种说法罢了)
2、利用内存和栈理解递归。
如果有学过java的人,相信对引用与对象之间的关系是很熟悉的,某个引用指向某个对象,而对象就是一大块堆内存。统一的类似的方式其实也可以放在递归调用这里理解:某个方法,调用另外一块内存的方法,该方法继续调用另外一块内存的方法,以此类推,知道,某个方法快有停止条件。看下面丑图:
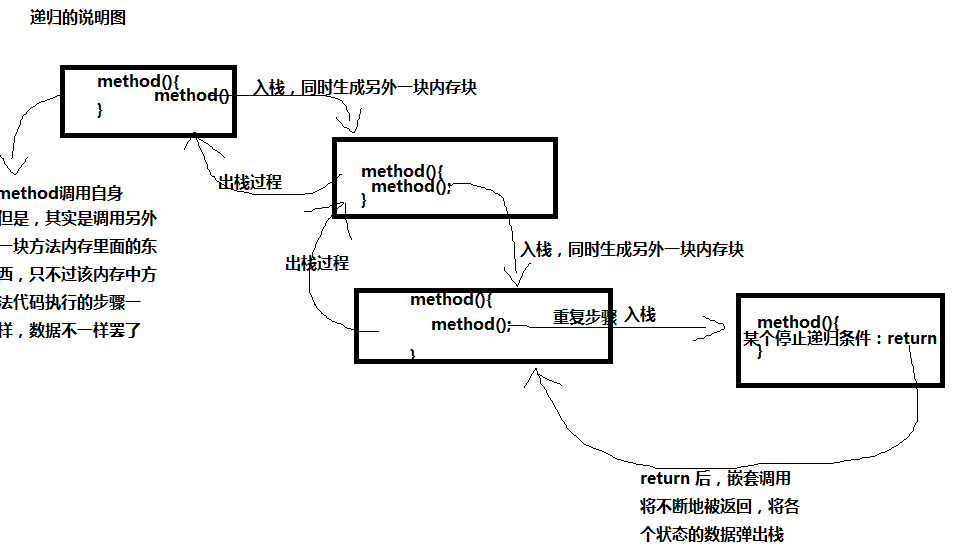
大概,上面的图也比较清晰地说明递归的内存本质了:不断生成新的内存块,在该内存块中执行同样的重复步骤,直到某个终止条件,和一个引用(对应方法本身)指向一个对象(对应嵌套调用自己),而同时,这个过程用到了基本的数据结构:栈,方法的状态依赖于栈进行储存,方法递归调用对应入栈,递归终止其实就是入栈元素已经最大化了,这时候,开始内存的出栈行为:不断地沿着入栈的顺序(先入后出),重复执行某个操作(对应pop的出栈)
3、利用循环理解递归。
递归,其实就是循环嘛,只不过,循环是利用一块内存做同样的事情,而递归则是利用多块内存做同样的事情罢了(所以各位也知道递归是很耗内存的);其实可用递归解决的问题,用循环大体也能解决,反之亦然。
就例如前面说的求阶乘,写出的循环估计很好理解:
public static int factoralLoops(int n){
int rtn = 1;
for(int i=1;i<=n;i++){
rtn = rtn * i;
}
return rtn;
}
这时候,对比下循环与递归,估计你就会对递归的本质有些理解了:
A、循环、递归都是做同样的事情,这里求阶乘就是不断的累乘;
B、循环、递归在解决问题时都是在重复步骤,每个步骤对应条件都要改变而且有停止条件(循环是在for(int i=1;i<=n;i++)这里改变,改变的是i,同时有停止循环条件,i>n;递归如出一辙:调用自身(对应循环的内部代码),但是参数改变(对应循环的i++),同时有递归的停止条件(对应循环中的i<=n))),以达到步骤重复但是计算结果不重复(陷入死循环、无限递归)的目的;所以其实循环递归本质没多大区别的,只是可以这样认为:循环看起来是从前面开始计算,以一种顺序的方式进行问题的解决,所以理解起来比较直观;而递归则是看起来从最后的结果来倒退回去(其实实际也是先计算前面的,不过直观看起来是倒回去罢了)进行计算。
C、循环:在同快内存中做同样的事情,递归却转义到多块内存做同样的事情。
D、递归是描述问题是什么(然后转化为计算机语言,问题是什么,其实就蕴含了问题的解决方案,当然,这个解决方法是计算机帮我们做的过程,也就是递归的过程);循环是描述问题如何解决。
二、递归的优劣
前面也说了挺多了,递归和循环的关系让我们可以一目了然地知道:递归比循环更消耗内存。所以,一般对内存性能要求高的算法不会使用递归而是使用循环。
但是,循环确实很多问题的很好解决方法:它提供了一种极其简洁的解决思路来解决复杂的问题,从数学上将,我只需要知道某个待解决问题的递推关系,我就能借助递归进行算法设计,而且所需要的代码量非常少(这时,递归的代码往往比循环的代码简洁得多,也好理解得多)。所以,在现在计算机内存资源这么丰富的年代,递归损耗一点内存而到达开发速度提高、代码易懂优雅在大多数情况感觉还是值得的。
ok,递归的基本理解大概就这么多了,说得不对的地方,大佬们指正下,谢谢。