HTTP请求
1.首先需要了解一下http请求,当用户在地址栏中输入网址,发送网络请求的过程是什么?
可以参考我之前学习的时候转载的一篇文章一次完整的HTTP事务过程–超详细
2.还需要了解一下http的请求方式
有兴趣的同学可以去查一下http的八种请求方法,这里呢主要说下get请求和post请求,这两种在以后学习中会用到的比较多。
get请求:GET方法用于使用给定的URI从给定服务器中检索信息,即从指定资源中请求数据。我们输入网址访问网站一般就是get请求。[做运维的小年轻]使用GET方法的请求应该只是检索数据,并且不应对数据产生其他影响。
优点:比较便捷
缺点:由于是明文传输,所以安全性比较低,另外参数长度有限制。
post请求:POST请求通常是使用来提交HTML的表单,表单中的数据传输到服务器,由服务器对这些数据处理。我们平常执行登录操作的那一下基本上都是post请求。
关于get请求和post请求区别优缺点这里推荐一篇博文:http GET 和 POST 请求的优缺点、区别以及误区
下面说一下Headers中的Request Headers(请求头信息),

Accept:指定客户端能够接收的内容类型,图中text/html表示要请求返回文本格式的数据
Accept-Encoding:指定浏览器可以支持的web服务器返回内容压缩编码类型,图中gzip表示支持gzip格式的压缩文件
Accept-Language:浏览器可接受的语言 图中 zh-CN表示接受中文
Connection:表示是否需要持久连接。(HTTP 1.1默认进行持久连接)图中keep-alive意为保持长链接
Cookie:是服务器发送到浏览器并保存在本地的一小块数据,存储在header中,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上,通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。
Host:指定请求的服务器的域名和端口号,图中是www.baidu.com也就是我在地址栏中请求的网址
User-Agent:包含的是发出请求的用户信息,客户机的软件环境浏览器类型等
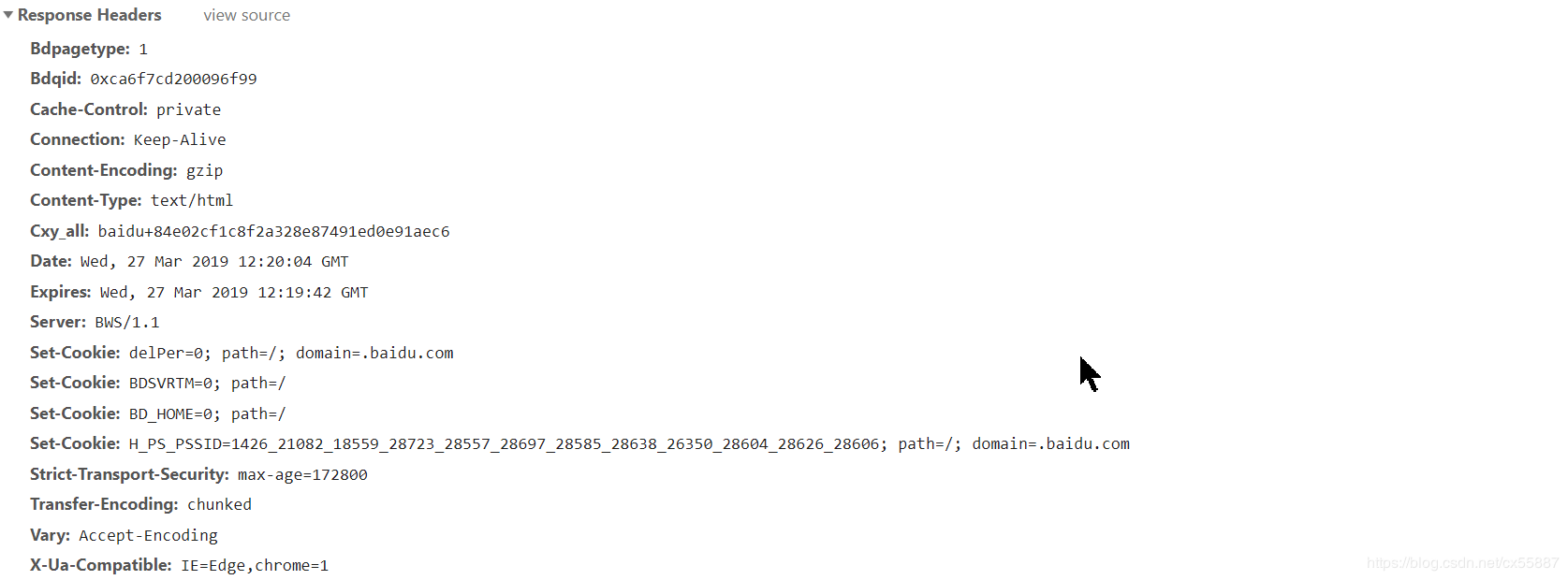
Response Header 和Request Headers对应,如下图
了解完这些呢,就来看下爬虫吧
关于爬虫
爬虫通俗来说,就是使用代码模拟用户,批量发送网络请求,批量的获取数据
爬虫的的分类
1.通用爬虫:搜索引擎的爬虫
优势:开放性很好,速度比较快
劣势:目标不明确,举个例子哈,例如我在百度搜索图片,搜索结果如下图,我想要的是图片,但是看下图红色方框所圈的内容并不是我们所要找的图片资源,这就是我所说[做运维的小年轻]的目标不明确,导致的结果呢就是返回的很多内容并不是用户所需要的。

2.聚焦爬虫:全称聚焦网络爬虫,又称为主题网络爬虫
优点:目标明确,对用户的需求非常精准,返回内容很固定,比如我就请求一张图片,那么就返回一张图片。
关于爬虫的分类其实在以后越来越深入的学习中,会自然而然的理解,现在只需有个大概了解就行了关于网络爬虫分类日百度百科中讲的比较详细,点击传送门去了解。