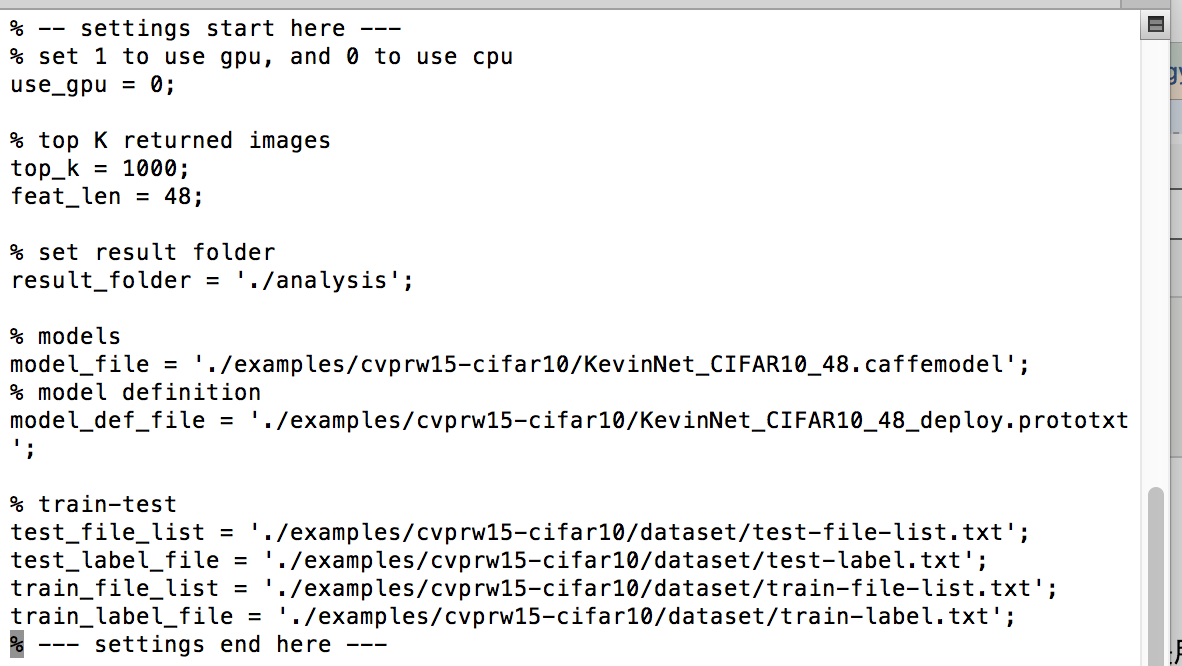
1.图片的处理
输入:将自己的图像转换成caffe需要的格式要求:lmdb 或者 leveldb 格式
这里caffe有自己提供的脚本:create_minst.sh
转换训练图片和验证图片的格式,运行脚本以后生成对应的:***_train_Imdb 文件夹,***_val_Imdb文件夹

在此注意的是 数据的标注:
create_minst.sh里的输入是train.txt 和val.txt (这两个文件分别保存的是:训练train图片的路径以及标签,还有验证val图片的路径和标签 )
格式如下:
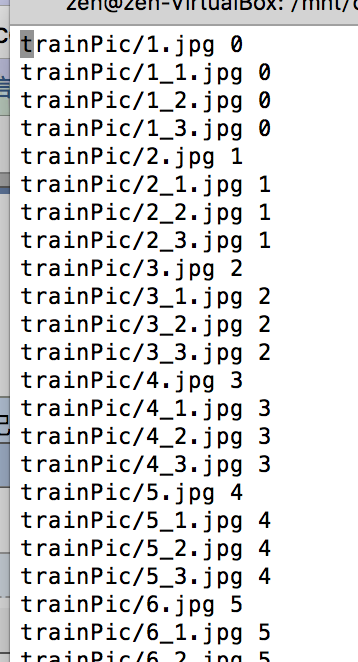
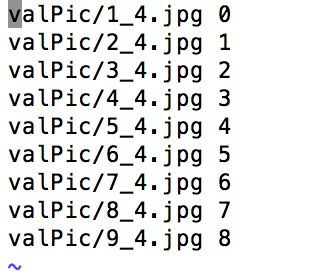
在create_imagenet.sh注意要写好train.txt与val.txt的文件路径
2. 编写配置文件并训练模型
配置文件有两个:1.参数的配置文件solver_**.prototxt(这里可以修改迭代的次数,步率以及其他内容,我只修改了迭代次数)
2.训练网络的配置文件:train_CIFAR10_48.prototxt,test_CIFAR10_48.prototxt
在train_CIFAR10_48.prototxt这里的source 就是我们之前转换好的caffe对应的训练图片的leveldb文件夹,同理test_CIFAR10_48.prototx
在这里需要注意的是meanfile是均值文件,他可以提高你的训练准确率。我这里没有自己生成均值文件,而是用的ilsvrc12库的均值文件~
solver_**.prototxt参数列表的意思分别如下:
- net:训练的网络模型所在的位置,这里我们是将train(训练)和val(验证)作为一个文件,所以时net,如果分为两个文件,则键值对为tarin_net:训练配置文件的位置,test_net:测试配置文件的位置。
- test_iter:测试迭代次数,我们每完成一次全部数据的训练,需要进行一次验证,例如这里我们测试迭代次数设为2,是因为我们有100个测试数据,batch_size为50,则test_iter设为100/50=2,就能全cover了。
- test_interval:测试间隔
- base_lr:基础学习率
- lr_policy:学习率的变化规律
- gamma:学习率的变化指数
- stepsize:学习率变化频率,结合上面三个可以理解,我们的学习率初始为0.001,每迭代100次,学习率乘以变化指数0.1。
- display:屏幕日志显示间隔,这是指多久打印依次日志,我们设为每20此迭代打印一次。
- max_iter:最大迭代次数
- momentum:动量
- weight_decay:权值衰减
- snapshot:保存训练模型的间隔,这里设为每迭代50次保存一个模型文件。
- snapshot_prefix:保存的模型文件的前缀,例如这里为/examples/myfile/文件夹下面,前缀名为myfile_train,则该模型迭代50次后生成一个myfile_train_iter_50.caffemodel文件,其他同理,这个模型文件保存了我们训练的模型得到的各种参数信息,例如w,b。
- solver_mode:计算方式,这里博主设置为CPU,如果你们的计算机支持GPU并且已经配置好caffe相关,则可设置为GPU,GPU的计算速度比CPU快好多。
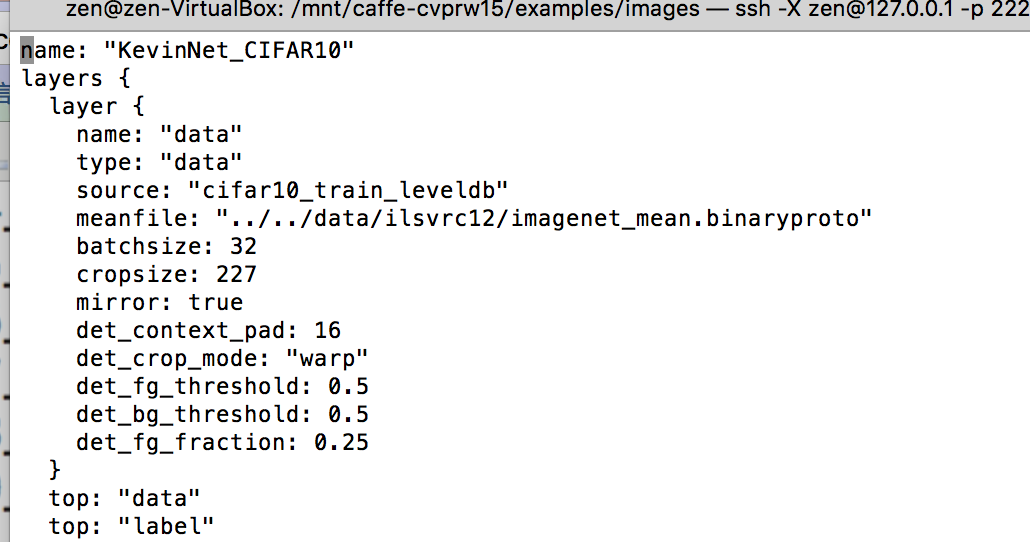
接下来运行训练的脚本:train.sh
脚本内容如下: 这里指定了了参数配置文件solver_CIFAR10_48.prototxt
还有一个值得提一句的是:bvlc_reference_caffenet.caffemodel这是一个与训练模型,需要提前下载好。 gpu -1是用cpu,
../../build/tools/caffe train -solver solver_CIFAR10_48.prototxt -weights ../../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel -gpu -1 2>&1 | tee log.txt
运行完以后会生成model文件:例子中我训练500次。

3.利用model来测试
这里有脚本文件:run_*.m
top_K代表匹配出几个相似图片 如果只想要匹配出最最相似的top_k=1
接下来的路径按照自己的路径填写。
强调的是:test_file_list存储的是要进行预测的图片路径,
test_label_list存储的是预测图片的正确答案(因为如果要求准确率,需要这个文件,如果不需要的话就忽略吧注释掉,然后把算精确率的代码注释掉就ok了)
train_file_list就是你的图片集,预测图片在这个图片集里寻找与 它最最匹配的picture