之前的章节,我们利用一个仅包含一层隐藏层的简单神经网络就在MNIST识别问题上获得了98%左右的准确率。我们于是本能会想到用更多的隐藏层,构建更复杂的神经网络将会为我们带来更好的结果。
就如同在进行图像模式识别的时候
,第一层的神经层可以学到边缘特征
,第二层的可以学到更复杂的图形特征,例如三角形,长方形等,第三层又会识别更加复杂的图案。
这样看来,多层的结构就会带来更强大的模型,进行更复杂的识别。
那么在这一章,就试着训练这样的神经网络来看看对结果有没有什么提升。不过我们发现,训练的过程将会出现问题,我们的神经网络的效果并没有什么提升。
为什么会出现这样的情况呢,这一章就是主要围绕着这个问题展开的。
我们将会发现,不同层的学习速率是不一样的。
例如,在后面的网络层训练正在顺利学习的时候,前面网络层的学习却卡住几乎不动了。
而且我们会发现这并不是偶然的,
而是在理论上由梯度下降算法导致的。随着我们对问题的深入了解,我们会发现相反的情况也是可能发生的,就是前面网络层学习正常,而后面网络层学习停止。
这虽然看上去都是坏消息,不过深入探索这些问题也是帮助我们设计更好的更高效的深度神经网络的训练方法。
一. 梯度消失问题
先回到之前的程序上,当我们选择一个隐藏层的时候得到准确率为96.48%。
接着增加一个隐藏层得到96.90%的结果。
看上去结果不错,毕竟提升了。接着再加上一个隐藏层,却只得到了96.57%的结果。这个结果虽说下降了没多少,
但是我们模型变复杂了,我们期望得到一个更好的结果,但是却事与愿违了。
这个结果看上去是奇怪的,而外的隐藏层理应使得模型可以处理更复杂的分类函数,不说结果提升多少,但是至少不能下降吧。为了搞清楚这期间到底是出了什么问题,我们回到两个隐藏层的情况,下面的图中,神经元上的柱形的长度表现的是其参数的更新速率,是当参数初始化完成后得到的结果:
大致看上去,
第二层整体的更新速率要比第一层的快很多
。但是由于权重的初始化也是随机的,我们很难判断这是不是一种巧合。
为了验证这是巧合还是事实,我们先定义,
然后可以看作是一个向量,其中每个分量表示第层中该神经元上参数更新的速率。
于是就可以将看作是层整体的学习速率,利用该速率的大小就可以比较不同层学习速率间的差别。
根据这些定义,我们发现和,这的确印证了一开始观察到的结果,第二层整体比第一层快。
三层隐藏层的时候呢?结果为0.012, 0.060和0.283,也是一样的结果:
后面的层比前面的层快。四层的时候为0.003,0.017,0.070和0.285,也是一样。
我们已经验证了参数刚初始完时的情形,也就是训练刚刚开始的情形,那么随着训练的进行,它们之间速率会发生什么变化呢?
先看两层的情形:
也是一样的结果,速率都是前面的层要慢于后面的层。
我们于是可以得到一个重要的观察现象:
在某些神经网络中,通过隐藏层从后向前看,梯度会变的越来越小。这也意味着,前面层的学习会显著慢于后面层的学习。这就是梯度消失问题。
那么是什么导致了梯度消失呢?是否可以避免这样的问题呢?事实上,的确存在替代方案,
但是会导致另外一个问题:前面层的梯度会变的很大而不是消失。
这就是梯度爆炸问题。
也就是说深度神经网络上的梯度要么倾向于爆炸要么倾向于消失,这都是不稳定的。
而这个不稳定性也是基于梯度的学习算法都要面临的一个基本问题。
不过我们也许会有疑问,为什么梯度消失就是问题,梯度是不是说明学习已经够了,这个神经元的参数已经被正确学习到了呢?
事实当然不是这样的,我们一开始初始化产生的参数肯定不可能那么巧合是最优的参数。
前层的学习速率慢,证明已经到了最优参数?no因为最开始的初始化肯定不能是最好的参数啊)
然而从三层隐藏层的那个例子看到,随机初始化意味着第一层会错过很多的重要信息(会错过好多信息),
即使后面的层训练的再好(前面和后面试分开的?)
,也很难识别输入图像。(前面的层次无法识别输入的图像)
并不是第一层已经训练好了,而是它们无法得到足够的训练。
如果我们想要训练这样的神经网络,就必须解决梯度消失问题。
二. 是什么导致了梯度消失问题?
看一个简单的例子,一个每层只有一个神经元的神经网络:
不过注意到这里的其实表示的是损失函数,其输出分别为:。
根据求导的链式法则有:
为什么会发生梯度消失:
其实看到这样一个式子:
如果还记得前面章节神经元saturated发生的原因的话也能知道这里究竟是什么导致了梯度消失。
注意到其间有一系列的项,先看一下sigmoid函数的导数图像:
最大值也才0.25,然后由于参数的初始化使用的高斯分布,常常会导致,这样就会导致。然后一系列这些小值的积也会变得更小。
当然这并不是一个严格的数学证明,我们很容易就会举出很多反例。
比如在训练过程中权重是可能变大的,如果大到使得不再满足,
或者说大于1,梯度就不会消失了,
它将指数增长,从而导致另外一个问题:
梯度爆炸问题。
梯度爆炸问题:
再来看一个梯度爆炸发生的例子。
我们选择大的权重:
然后选择偏差使得不太小。
这个并不难做到,例如我们可以选择使得时的bias,于是得到,这样就会导致梯度爆炸了。
梯度的不稳定性问题:
经过这些讨论我们就会发现,梯度消失也好,梯度爆炸也好,归根结底是由于层数的增加,多个项相乘,势必就会导致不稳定的情况。
除非这些积能恰到好处的相等,才可以让不同层之间的学习速率相近。不过实际上,这几乎是不可能发生的。总之,只要我们使用基于梯度的学习算法,不同层的学习速率势必是有很大差距的。
练习:
问题:
之前我们基于的事实讨论了梯度消失的问题,那么是否可以使用另外一个激活函数,使得其导数足够大,来帮助我们解决梯度不稳定的问题呢?
答案:
这个当然是不可以的,不管一开始的值是怎么样的,因为多个项相乘,这就会导致积是指数增长或者指数下降,可能浅层时不明显,但是随着层数的增加,都会导致这个问题出现。
梯度消失问题很难消除的原因:
之前已经发现了在深层网络的前几层会出现梯度或者消失或者爆炸的问题。
事实上,当使用sigmoid函数作为激活函数的时候,梯度消失几乎是总会出现的。
考虑到避免梯度消失
,要满足条件。
我们也许会觉得这还不简单,只要大不就可以了,但是注意到大,也会导致也大,然后就会很小。唯一的方法就是还需要保证只出现在一个很小的范围内,这在实际情况下显然是很难发生的。所以说就总是会导致梯度消失的问题。
拓展:
拓展一:
考虑,假设
(1) 证明这只可能在时成立
之前已经知道在0处取最大值0.25,所以成立的话势必需要 。
(2)假设,考虑到,证明此时的的变化区间被限制在宽度 内
这个就是纯数学问题解方程了,利用一元二次方程的求根公式可以求得和,然后求对数后相减,稍微变换一下形式就可以得到这个结果。
(3)证明上面的范围的最大值大约为0.45,在处得到。于是可以看到即使所有这些条件都满足,激活函数的符合要求的输入范围还是非常窄,还是很难避免梯度消失的问题。
求导算导数为0的点求得。
拓展二:identity神经元
考虑一个单输入的神经元,中间层参数为和,然后输出层参数为,证明通过选择适当的权重和偏差,可以使得对任意成立。这个神经元可以被认为是一种identity神经元,其输出和输入一样(只差一个权重因子的放缩)。提示:可以将写为, 假设很小,使用处的泰勒展开。
之前讨论sigmoid函数形状的时候知道,当增大的时候,函数会变得越来越窄,逼近解约函数。当非常小的时候,函数越来越宽,在某个区间内会逼近线性函数,但是既然是sigmoid函数,当时,函数都是会趋向于1或0的。
这里的证明我没有用泰勒展开,我想的是既然要证明该函数在某个区间的线性,只要证明它导数在该区间趋近于常数即可。
求的导数为。
不妨令则上式变为:
,由于, 而是很小的数,于是可将上式展开为为常数,通过适当调整就可以使其输出恰好为。
三. 复杂神经网络中的梯度不稳定问题

Deep Residual Learning
(2)初始化:
我们设深度网络中某隐含层为
H(x)-x→F(x),
如果可以假设多个非线性层组合可以近似于一个复杂函数
,那么也同样可以
假设
隐含层的残差
近似于某个复杂函数[6]
。即那么我们可以将隐含层表示为H(x)=F(x)+ x。
这样一来,我们就可以得到一种全新的残差结构单元
,如图3所示。可以看到,
残差单元的输出
由多个卷积层级联的
输出和输入元素间相加(保证卷积层输出和输入元素维度相同),
再经过ReLU激活后得到。
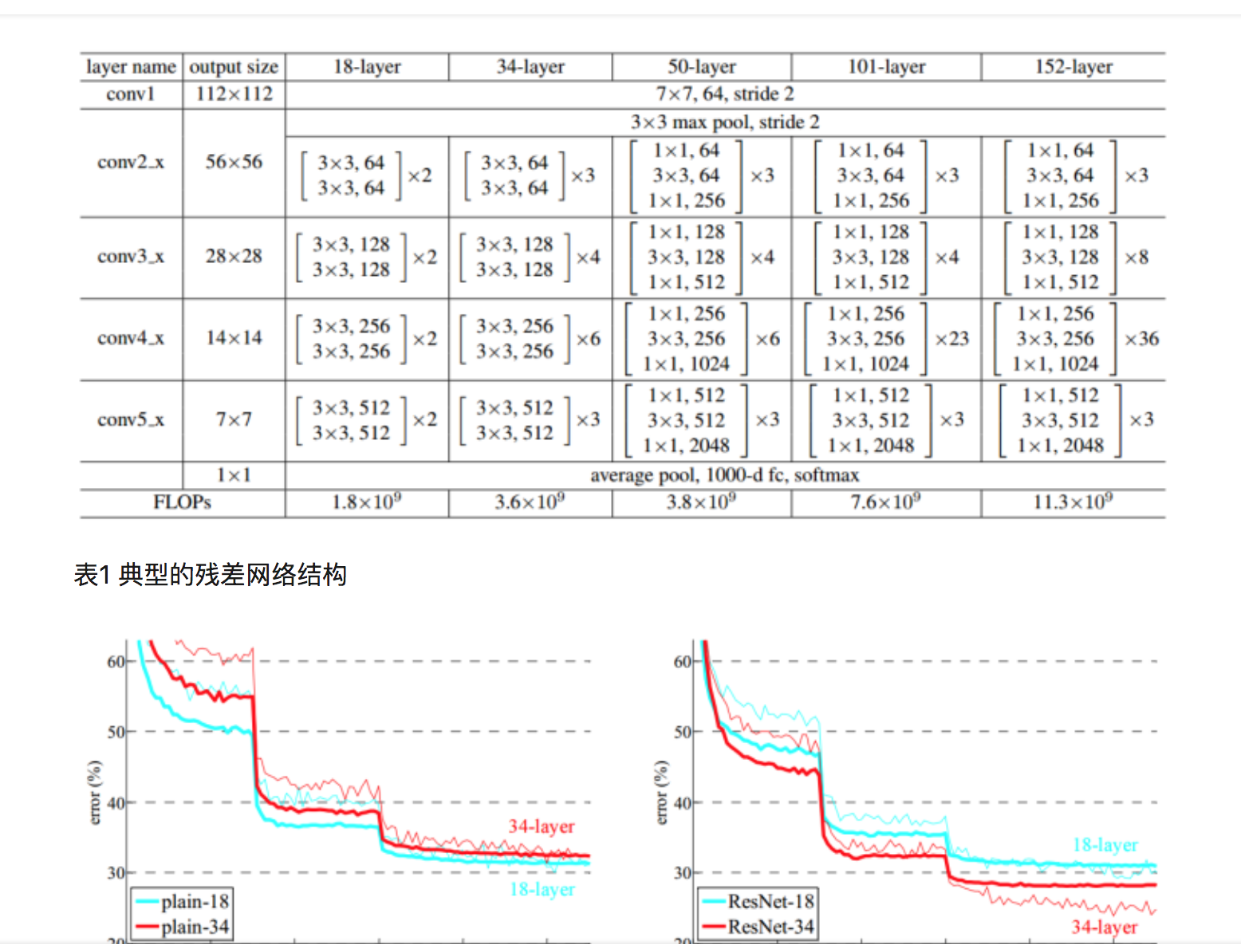
将这种结构级联起来,就得到了残差网络。典型网络结构表1所示。
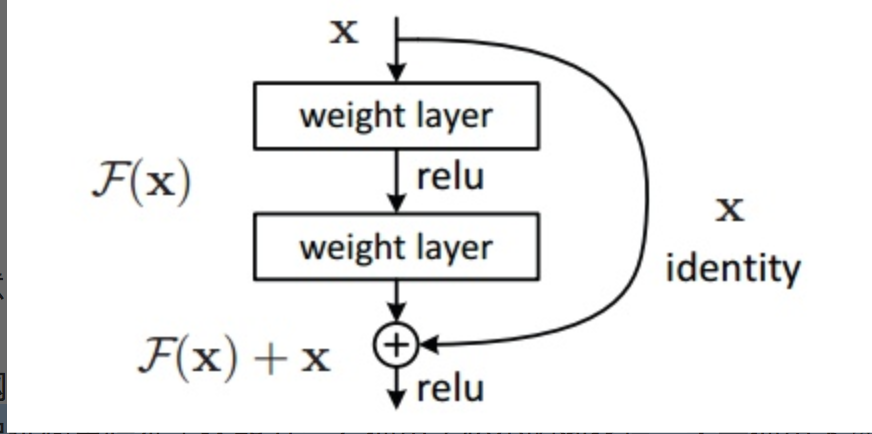
图3 残差单元示意图
可以注意到残差网络有这样几个特点:
1. 网络较瘦,控制了参数数量;
2. 存在明显层级,特征图个数逐层递进,保证输出特征表达能力
3. 使用了较少的池化层,大量使用下采样,提高传播效率;
4. 没有使用Dropout,利用BN和全局平均池化进行正则化,加快了训练速度;
5. 层数较高时减少了3x3卷积个数,并用1x1卷积控制了3x3卷积的输入输出特征图数量,称这种结构为“瓶颈”(bottleneck)。
网络响应:图7中可以看出,
残差网络中大部分层的响应方差都处在较低水平,
这一定程度上印证了我们的假设:
这些响应方差较低的层响应较为固定,
很有可能权重近似于零,
这也就是说
其所对应的残差结构可能近似于单位映射,
网络的实际有效层数是要比全部层数要少一些的
,产生了跳过连接(Skip-connection)的作用。
这样也就是网络为什么在较深的深度下仍可以保持并提升性能,
且没有过多增加训练难度的原因。
ResDeeper more
何恺明等人基于深度残差结构,进一步设计了一些其他的残差网络模型,用于Cifar-10数据集上的分类任务,分类错误率如图8所示。可以看到,110层以下的残差网络中均表现出了较强的分类性能。但在使用1202层残差网络模型时,分类性能出现了退化,甚至不如32层残差网络的表现。由于Cifar-10数据集尺寸和规模相对较小,此处1202层模型也并未使用Dropout等强正则化手段,1202层的网络有可能已经产生过拟合,但也不能排除和之前“平整”网络情况类似的原因导致的性能退化。
图8 Cifar-10数据集上残差网络和其他网络分类测试错误率对比
何恺明等人经过一段时间的研究,认为极其深的深度网络可能深受梯度消失问题的困扰,BN、ReLU等手段对于这种程度的梯度消失缓解能力有限,并提出了
单位映射的残差结构[7]。
这种结构从本源上杜绝了梯度消失的问题:
基于反向传播法计算梯度优化的神经网络,
由于反向传播求隐藏层梯度时利用了链式法则,
梯度值会进行一系列的连乘,导致浅层隐藏层的梯度会出现剧烈的衰减,这也就是梯度消失问题的本源,这种问题对于Sigmoid激活尤为严重,故后来深度网络均使用ReLU激活来缓解这个问题,但即使是ReLU激活也无法避免由于网络单元本身输出的尺度关系,在极深度条件下成百上千次的连乘带来的梯度消失。