Spark SQL简述
Spark SQL在Spark全家桶中扮演着很重要的角色,本文主要从参考的书籍和自己的理解尝试着总结下Spark SQL(2.3.2),也算是个笔记。先来个网上的图片,看看Spark SQL的架构是怎么样的。
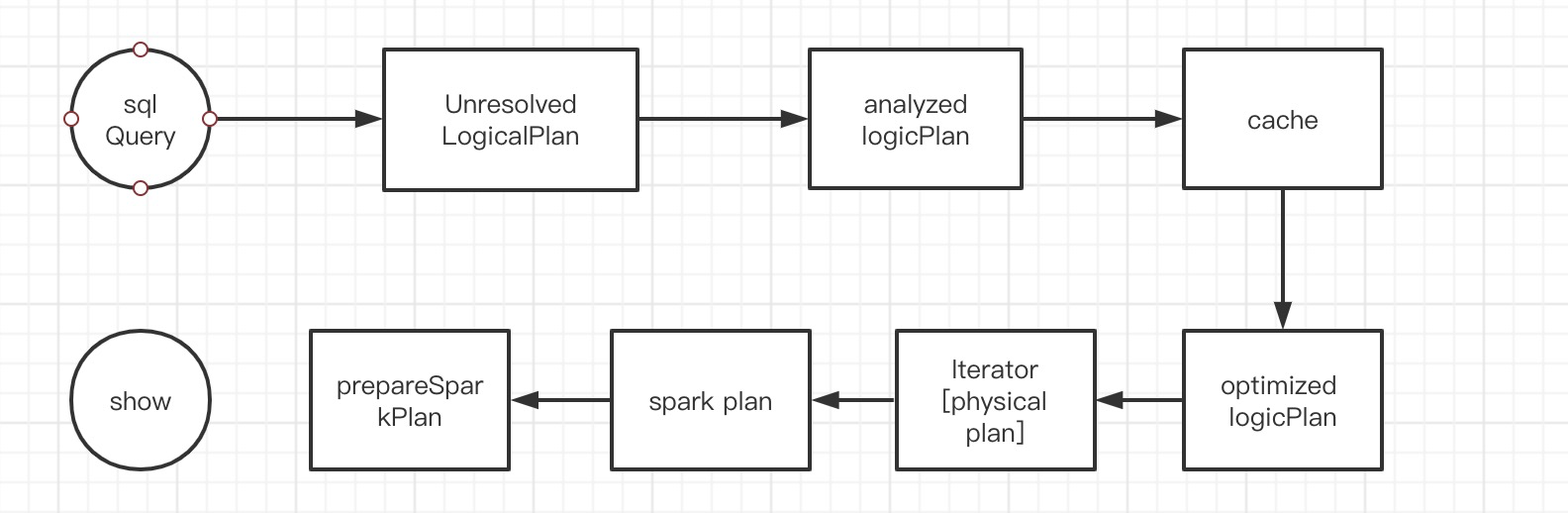
Spark sql主要步骤设计逻辑计划,然后物理计划之后会将物理计划转化为对应的RDD操作。
1、逻辑计划
上图中关于逻辑计划:
1、sqlQuery 就是一条sql语句,经过antrl4解析之后会转换成一个树型结构-逻辑算子树(未解析)对应图中Unresolved LogicalPlan;
一般触发的解析的代码位置为sparkSession.sql ->sessionState.sqlParser.parsePlan -> AbstractSqlParser.parsePlan:
/** Creates LogicalPlan for a given SQL string. */ override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser => val tmp = astBuilder.visitSingleStatement(parser.singleStatement()) tmp match { case plan: LogicalPlan => plan case _ => val position = Origin(None, None) throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position) } }
2、之后会经过解析绑定SessionCatalog数据信息形成解析后的逻辑算子树对应图中analyzed LogicalPlan;
从这步开始往后一直到提交代码前主要步骤都在QueryExecution中:
lazy val analyzed: LogicalPlan = {
SparkSession.setActiveSession(sparkSession)
sparkSession.sessionState.analyzer.executeAndCheck(logical)
}
3、之后会在cacheMange中匹配已经缓存的LogicalPlan plan,替换相关树节点对应图中cache;
lazy val withCachedData: LogicalPlan = {
assertAnalyzed()
assertSupported()
sparkSession.sharedState.cacheManager.useCachedData(analyzed)
}
4、之后会到优化的步骤,主要应用一些基于规则的优化(RBO),形成优化后的逻辑算子树optimized LogicalPlan;
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
2、物理计划
之后就是物理计划部分:
1、经过QueryPlan会解析整棵树将逻辑计划转化为物理计划,在这一步可能会生成多个物理计划,但是只会取生成的物理计划中的第一个。
lazy val sparkPlan: SparkPlan = { SparkSession.setActiveSession(sparkSession) // TODO: We use next(), i.e. take the first plan returned by the planner, here for now, // but we will implement to choose the best plan. planner.plan(ReturnAnswer(optimizedPlan)).next() }
2、进入prepareForExecution,这一步会对物理计划应用多种策略进行优化,之后生成的物理计划会转为RDD的操作。然后就是提交作业运行。
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
3、触发执行
触发一般都是通过一系列的调用会落在 QueryExecution.toRdd方法上。
lazy val toRdd: RDD[InternalRow] = executedPlan.execute()
上面从sql一直到物理计划提交前都是在spark集群的的driver节点上进行的。
参考: 《Spark SQL内核剖析》