1、集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包)
本集群搭建案例,以5节点为例进行搭建,角色分配如下:
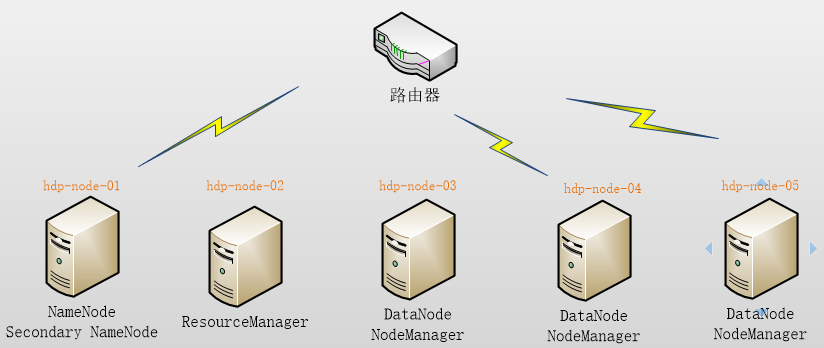
2、服务器准备
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
A.Vmware 11.0
B.Centos 6.5 64bit
3、网络环境准备
A 、采用NAT方式联网
B、网关地址:192.168.137.1
C、3个服务器节点IP地址:192.168.137.31、192.168.137.32、192.168.137.33
D 、子网掩码:255.255.255.0
4、服务器系统设置
A. 添加HADOOP用户
B. 为HADOOP用户分配sudoer权限
C. 同步时间
D. 设置主机名
hdp-node-01
hdp-node-02
hdp-node-03
E. 配置内网域名映射:
192.168.137.31 hdp-node-01
192.168.137.32 hdp-node-02
192.168.137.33 hdp-node-03
F. 配置ssh免密登陆
G. 配置防火墙
5、Jdk环境安装
上传jdk安装包
规划安装目录 /home/hadoop/apps/jdk_1.7.65
解压安装包
配置环境变量 /etc/profile
6、HADOOP安装部署
ü 上传HADOOP安装包
ü 规划安装目录 /home/hadoop/apps/hadoop-2.6.1
ü 解压安装包
ü 修改配置文件 $HADOOP_HOME/etc/hadoop/
最简化配置如下:(默认是后面有.template文件。)
vi hadoop-env.sh
|
# The java implementation to use. export JAVA_HOME=/home/hadoop/apps/jdk1.7.0_51 |
vi core-site.xml
|
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hdp-node-01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/HADOOP/apps/hadoop-2.6.1/tmp</value> </property> </configuration> |
vi hdfs-site.xml
|
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/data/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/data/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.secondary.http.address</name> <value>hdp-node-01:50090</value> </property> </configuration> |
vi mapred-site.xml
|
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
vi yarn-site.xml
|
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> |
vi salves
|
hdp-node-01 hdp-node-02 hdp-node-03 |
7、启动集群
初始化HDFS
bin/hadoop namenode -format
启动HDFS
sbin/start-dfs.sh
启动YARN
sbin/start-yarn.sh
单个启动
hadoop-de
8、测试
A、上传文件到HDFS
从本地上传一个文本文件到hdfs的/wordcount/input目录下
[HADOOP@hdp-node-01 ~]$ HADOOP fs -mkdir -p /wordcount/input
[HADOOP@hdp-node-01 ~]$ HADOOP fs -put /home/HADOOP/somewords.txt /wordcount/input
B、运行一个mapreduce程序
在HADOOP安装目录下,运行一个示例mr程序
cd $HADOOP_HOME/share/hadoop/mapreduce/
hadoop jar mapredcue-example-2.6.1.jar wordcount /wordcount/input /wordcount/output