1 基本介绍
1.1 前言
HBase – Hadoop Database。是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样。HBase在Hadoop之上提供了相似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。
HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
还有一个不同的是HBase基于列的而不是基于行的模式。
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。利用HBase技术可在便宜PC Server上搭建起大规模结构化存储集群。
2 安装和使用
2.1 下载
HBase的官方站点http://www.apache.org/dyn/closer.cgi/hbase/上面能够下载到各种版本号。眼下用最新版本号是0.98.2,建议下载stable文件夹下的稳定版本号。
2.2 安装
安装依赖基础要求
1. Linux操作系统
依据HBase的官方介绍。HBase没有在windows下測试过,因而,我们都是将HBase安装在Linux操作系统上。
我本机安装的Ubuntu 12.04的虚拟机。
2. Jdk
HBase须要jdk支持其运行。jdk版本号要求是1.6及其以上。
这里暂且把Linux虚拟机的安装和虚拟机上jdk的安装过程跳过,能够參照网上其它相关资料运行。
HBase的安装方法比較简单,将我们下载的HBase的安装包hbase-0.94.20.tar.gz复制到Linux的根文件夹下。
接着运行下面命令和配置。之后启动HBase:
1. 解压缩安装包
root@ubuntu:/# tar xfz hbase-0.94.20.tar.gz
root@ubuntu:/# cd hbase-0.94.20
2. 配置数据存储文件夹
正如官方文档描写叙述的那样,这时我们能够直接启动HBase,这种话,使用的数据存储文件夹为 /tmp/hbase-${user.name},也就意味着,我们一旦重新启动Linux。我们先前存储的数据就将丢失。
Linux下运行下面命令:
root@ubuntu:/# cd /hbase-0.94.20/conf/
root@ubuntu:/hbase-0.94.20/conf# vi hbase-site.xml
之后,改动配置文件内容为:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl"href="configuration.xsl"?
>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///hbase_data/hbase</value>
</property>
</configuration>
3. 启动HBase
root@ubuntu:/hbase-0.94.20/conf# ../bin/start-hbase.sh
starting master, logging to/hbase-0.94.20/bin/../logs/hbase-root-master-ubuntu.out
至此。单机模式启动HBase已经完毕了。HBase的停止脚本是同样文件夹下的stop-hbase.sh。
2.3 HBase安装模式
在上一节中我们提到,我们安装的是单机模式。单机模式表示,我们全部的服务都运行在一个JVM上,包含HBase和Zookeeper。
另外,HBase还有两种安装模式:伪分布式模式和分布式模式。
伪分布式模式是把进程运行在一台机器上。但不是一个JVM。
全然分布式模式就是把整个服务被分布在各个节点上了 。
伪分布式模式和分布式模式依赖安装较多其它组件和服务。安装过程较为复杂。将会在还有一篇文章中专门介绍。
3 開始一个样例
大多数技术人员happy的时候開始了。
我们開始一个简单的Helloworld。
3.1 使用HBase shell连接HBase
使用HBase自带的client连接工具。连接到HBase:
3.2 创建User表
输入下面命令并运行:

3.3 对User表简单地增删改查
往User表中插入一条信息:

查询刚才插入的信息:

3.4 检查数据存储文件夹
我们看一下之前我们配置的数据存储文件夹的变化:

我们能够看到,在之前配置的数据存储文件夹下。已经新加入了一些用于存储我们刚才存入的数据的文件了。
4 HBase基础定义和概念
4.1 表
HBase是一个数据库,数据以表的形式存储在Hbase中。
正如我们在hello world中定义中的User表相似,HBase的表的结构例如以下所看到的:
|
Row Key |
Time Stamp |
ColumnFamily contents |
ColumnFamily anchor |
|
"com.cnn.www" |
t9 |
|
anchor:cnnsi.com = "CNN" |
|
"com.cnn.www" |
t8 |
|
anchor:my.look.ca = "CNN.com" |
|
"com.cnn.www" |
t6 |
contents:html = "<html>..." |
|
|
"com.cnn.www" |
t5 |
contents:html = "<html>..." |
|
|
"com.cnn.www" |
t3 |
contents:html = "<html>..." |
|
4.2 行、列族、列
行以rowkey作为唯一标示。Rowkey是一段字节数组,这意味着,不论什么东西都能够保存进去,比如字符串、或者数字。行是按字典的排序由低到高存储在表中。
列族是列的集合。要准确表示一个列。须要“列族:列名”的方式。比如Hello world中的name列,应该被表示为“personalinfo:name”。
值得注意的是,列族被要求在创建表时指定,但列不须要,能够随时使用的时候创建。另外,一个列族的成员在文件系统上都存储在一起,因而列族中的全部列的存取方式都是一致的。
HBase的存储优化就都针对列族级别,比如,我们能够考虑将经常须要一起取出来分析的信息。都存储在一个列族上。
5 HBase经常使用的操作
为了方便大家开发过程中高速查询,这里分类介绍最常见的HBase命令。HBase shell中支持的全部命令,能够通过help命令来列举出来。例如以下所看到的:
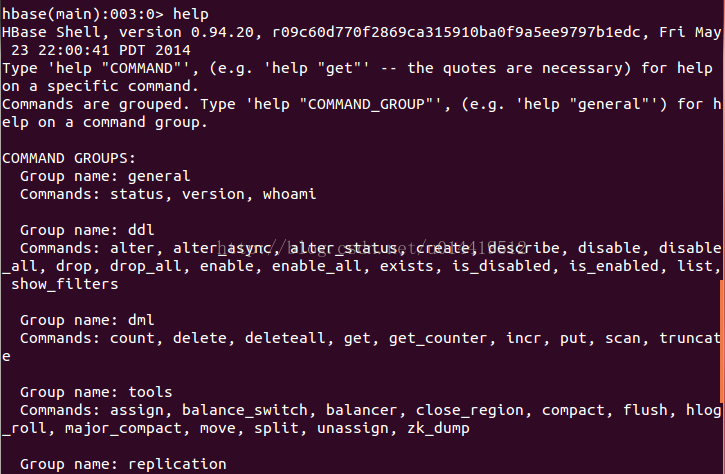
这里仅仅是截取了前部分命令。尚有部分命令不能再上图中显示。
5.1 一般命令
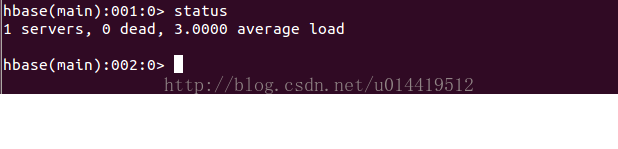
5.1.1 status
功能:查询server状态
使用:
5.1.2 version
功能:查询HBase版本号信息
使用:

5.1.3 whoami
功能:查看连接的用户
使用:

5.2 DDL命令
5.2.1 Create创建表
功能:创建一个表。正如之前提到的,创建一个表时,不指定详细的列名,但要指定列族名。
使用:create ‘表名’,’列族名1’,’列族名2’

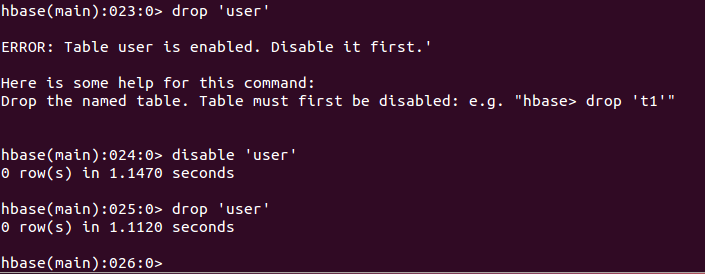
5.2.2 disable失效表
功能:失效一个表。当须要改动表结构、删除表时,须要先运行此命令。
使用:

5.2.3 enable使失效表有效
功能:使表有效。
在失效表以后,须要运行此命令,以使得表可用。
使用:

5.2.4 alter改动表结构
功能:改动表结构。包含新增列族、删除列族等
使用:
新增列族(记得在运行alter之前。要先disable表)
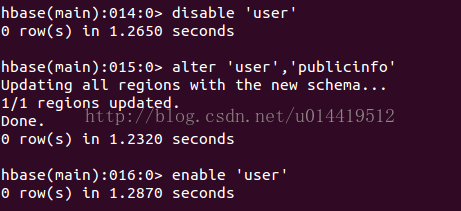
删除列族
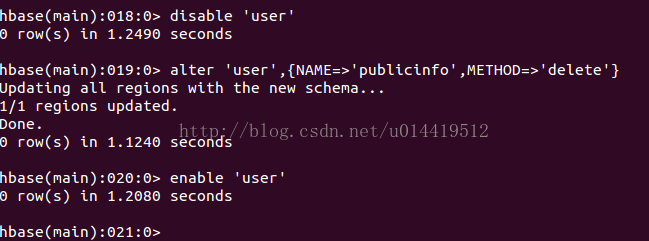
重命名列族
列族不能被重命名。重命名一个列族的通常途径是使用API创建一个有着期望名称的新的列族,然后将数据复制过去,最后再删除旧的列族。
5.2.5 describe查看表结构
功能:查看表结构
使用:
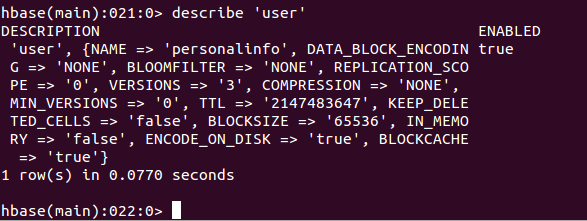
5.2.6 list列举数据库中的全部表
功能:查看数据库中全部的表
使用:
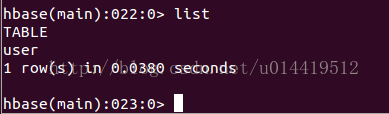
5.2.7 drop删除表
功能:删除指定的表
使用:
5.3 DML命令
5.3.1 put插入数据
功能:插入一条数据到指定的表中。对于同一个rowkey,假设运行两次put,则第二次被觉得是更新操作。
使用:put ‘表名’,’列族名1:列名1’,’值’

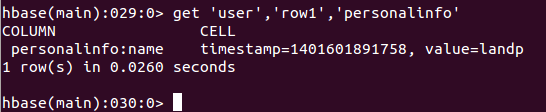
5.3.2 get获取数据
功能:获取数据
使用:
获取指定rowkey的指定列族指定列的数据

获取指定rowkey的指定列族全部的数据
获取指定rowkey的全部数据

获取指定时间戳的数据

5.3.3 Count计算表的行数
功能:计算表的行数
使用:

5.3.4 put更新数据
详见5.3.1
5.3.5 scan全表扫描数据
功能:扫描全表全部数据
使用:

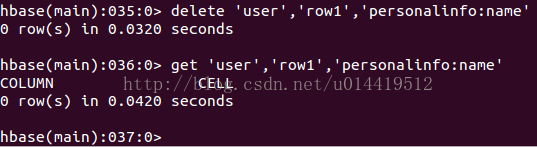
5.3.6 delete删除数据
功能:删除表中的数据
使用:
删除指定rowkey的指定列族的列名的数据
删除指定rowkey的指定列族的数据

5.3.7 deleteall删除整行数据
功能:删除整行数据
使用:

5.3.8 truncate删除全表数据
功能:删除表中全部的数据。正如你看到的,在HBase的help命令里并没有
使用: