scrapy-redis使用的爬虫策略:
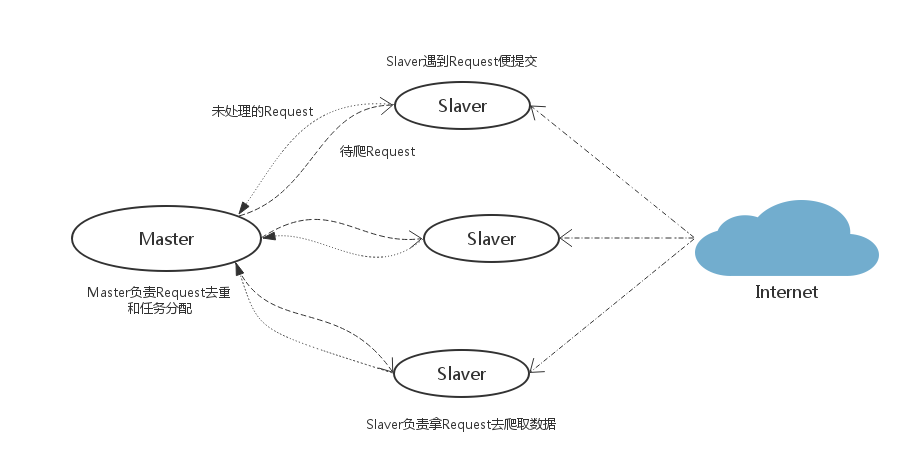
Slaver端从Master端拿任务进行数据抓取,在抓取数据的同时也生成新任务,并将任务抛给Master。Master端负责对Slaver提交的任务进行去重、加入待爬队列。
scrapy-redis在处理分布式时,会在redis中创建两个key,一个是(spider.name):requests作为队列使用,另一个是(spider.name): dupefilter作用是去重
队列任务分配
Slaver端解析到新的URL任务,先判断在key: dupefilter中是否已经存在,如果没有则将其push记录到key:requests的任务队列中,保存的格式如:
{'body': '', '_encoding': 'utf-8', 'cookies': {}, 'meta': {}, 'headers': {}, 'url': u'http://www.test.com/test', 'dont_filter': False, 'priority': 0, 'callback': 'parse_item', 'method': 'GET', 'errback': None}
key:requests作为一个任务分配,将一个任务pop分配后即在队列中删除
去重
将分配过的任务保存其sha1值到key: dupefilter中,格式如:
1babbfde30b0030559373ebe3e2a7a0955527e5f
每次往队列中添加任务前先判断下key: dupefilter中是否已经存在,去重
断点重爬
当爬虫停止,key:requests队列中的任务依然存在,下次启动继续