最近在学习大数据相关的东西,开这篇专题来记录一下学习过程。今天主要记录一下MapReduce执行流程解析
引子(我们需要解决一个简单的单词计数(WordCount)问题)
- 1000个单词
嘿嘿,1000单词还不简单,我们直接一句shell搞定
cat file | tr ' ' '
' | sort | uniq -c | sort -rk1 | head -n 20
- 1000G
感觉良好,写个简单的程序也很好解决。 - 1000*1000G
有点懵逼了。 - 1000*1000*1000G
这时候就该请出我们的主角MapReduce了,MapReduce能解决海量数据的计算,海到什么程度呢,理论上来说是无限。那么它是怎么解决这么大量的数据的呢?
MapReduce思想(分治思想)
| 分治思想 | MapReduce |
|---|---|
| 分解-求解 | 分:map |
| 合并 | 合:reduce |
- 下面来看看MapReduce的与单点程序具体执行流程比较
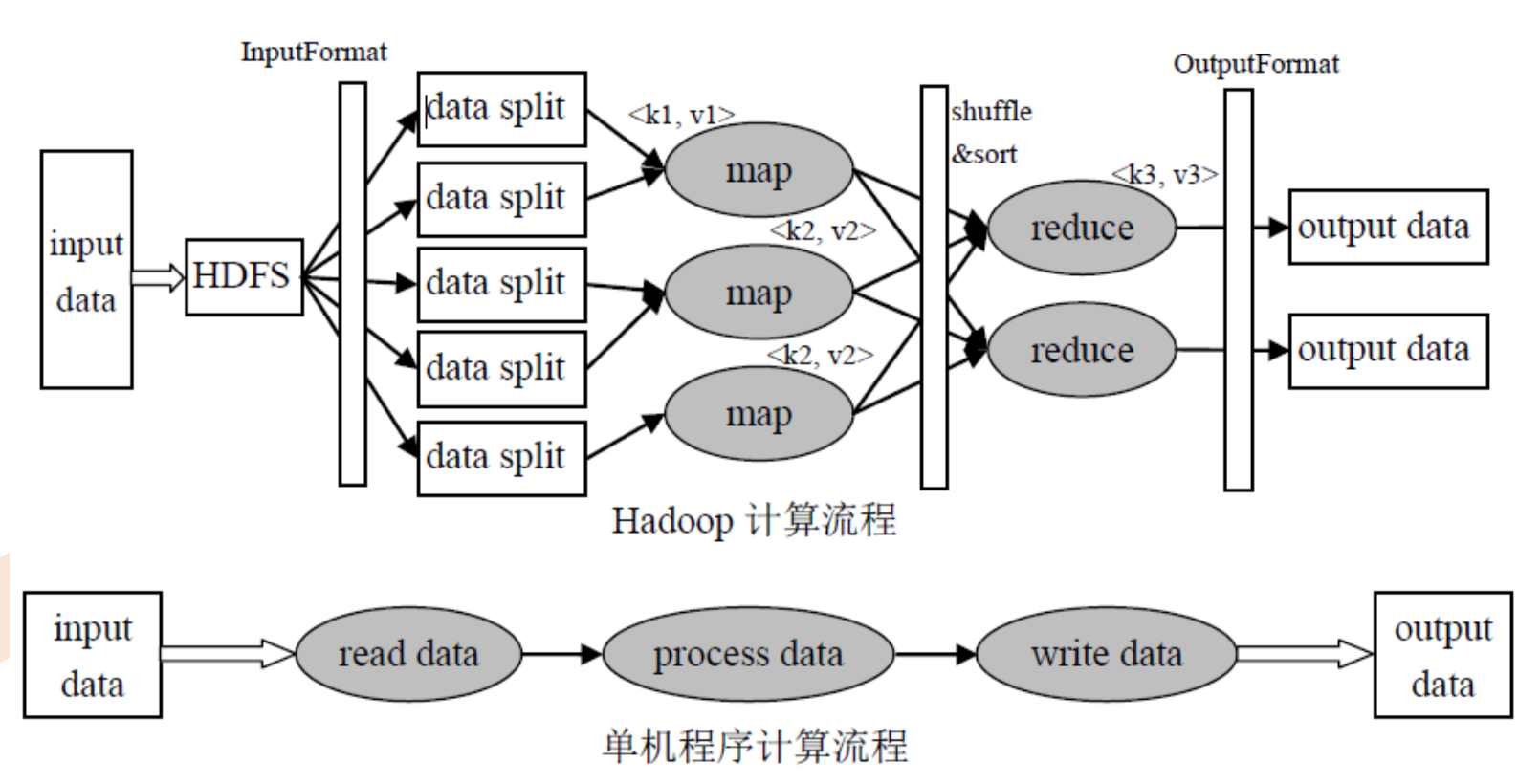
可以明显的看到和单点程序相比MapReduce数据来源于HDFS,在read data阶段作分片处理,把数据源按照不同的规模进行拆分;在process data阶段一样把任务分配给很多map来做;同样在write data阶段由一定数量的reduce来处理最终的结果。
- 上面流程是一个整体的架构图,让我们近一步看看单个MapReduce流程是怎么运行的
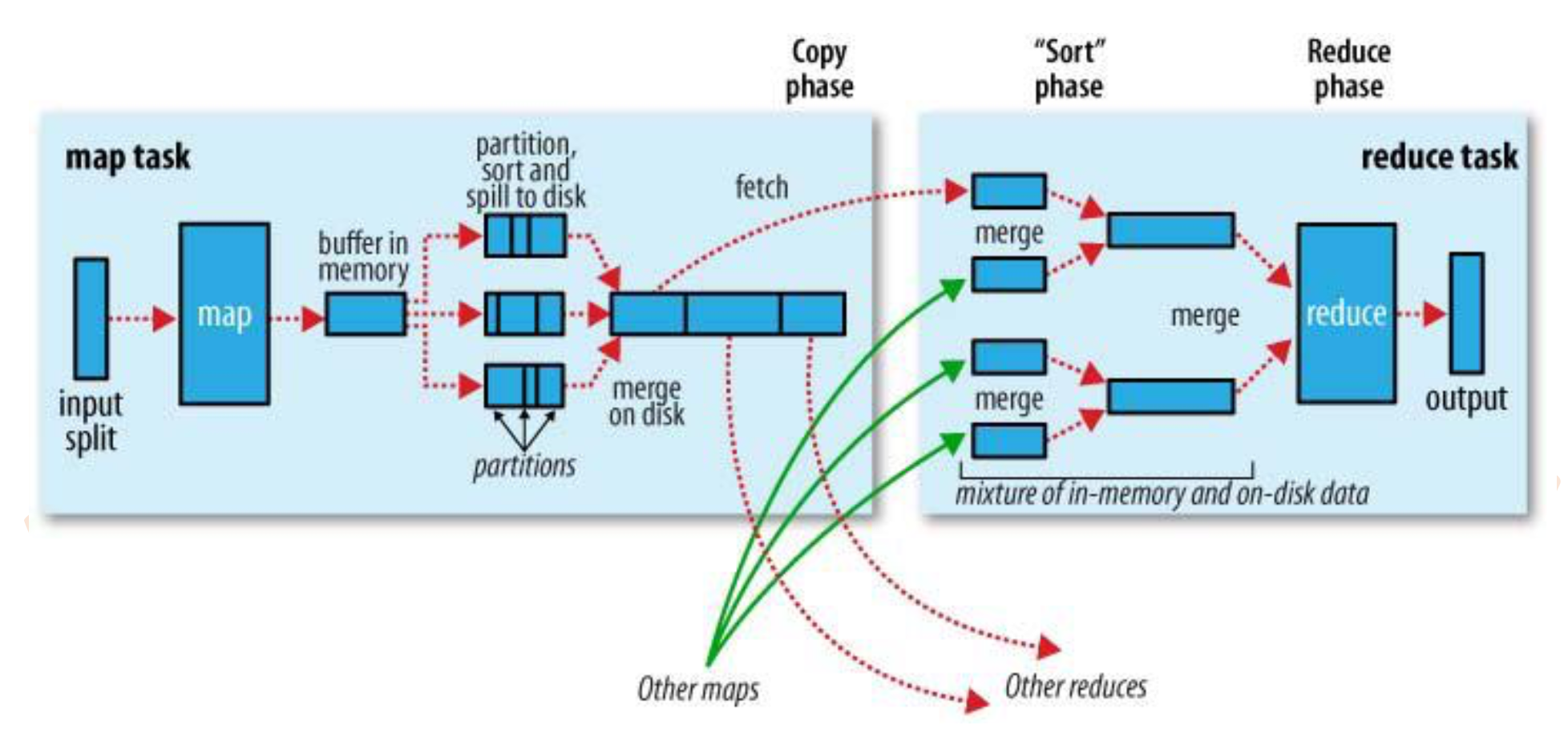
在这个阶段,一个map其实就是对应着一个split。map读取对应分片的数据,经过map函数(我们自己实现的)处理后并且经过partition到一个默认大小100M(可配置)的buffer上,当它写到80M(可配置)的时候,开始spill数据到文件,每次都会产生一个小文件,在spill的过程中写的时候会对数据进行sort(默认排序算法是快排)、Combiner。写到磁盘后每一个小文件都是有序的,那么这个多的小文件该怎么处理呢,不用想,肯定是merge,那么这么多有序的小文件,肯定是直接归并排序。每个map的数据merge完成以后,会根据不同的partition被fetch对应的reduce上面处理,reduce拿到这些数据先对数据进行merge,然后经过reduce函数(我们自己实现的)处理,并且合并多个reduce结果得到最终结果。
- 更进一步,继续深入
我们把上面的步骤进一步拆解,更详细的看看每一个步骤
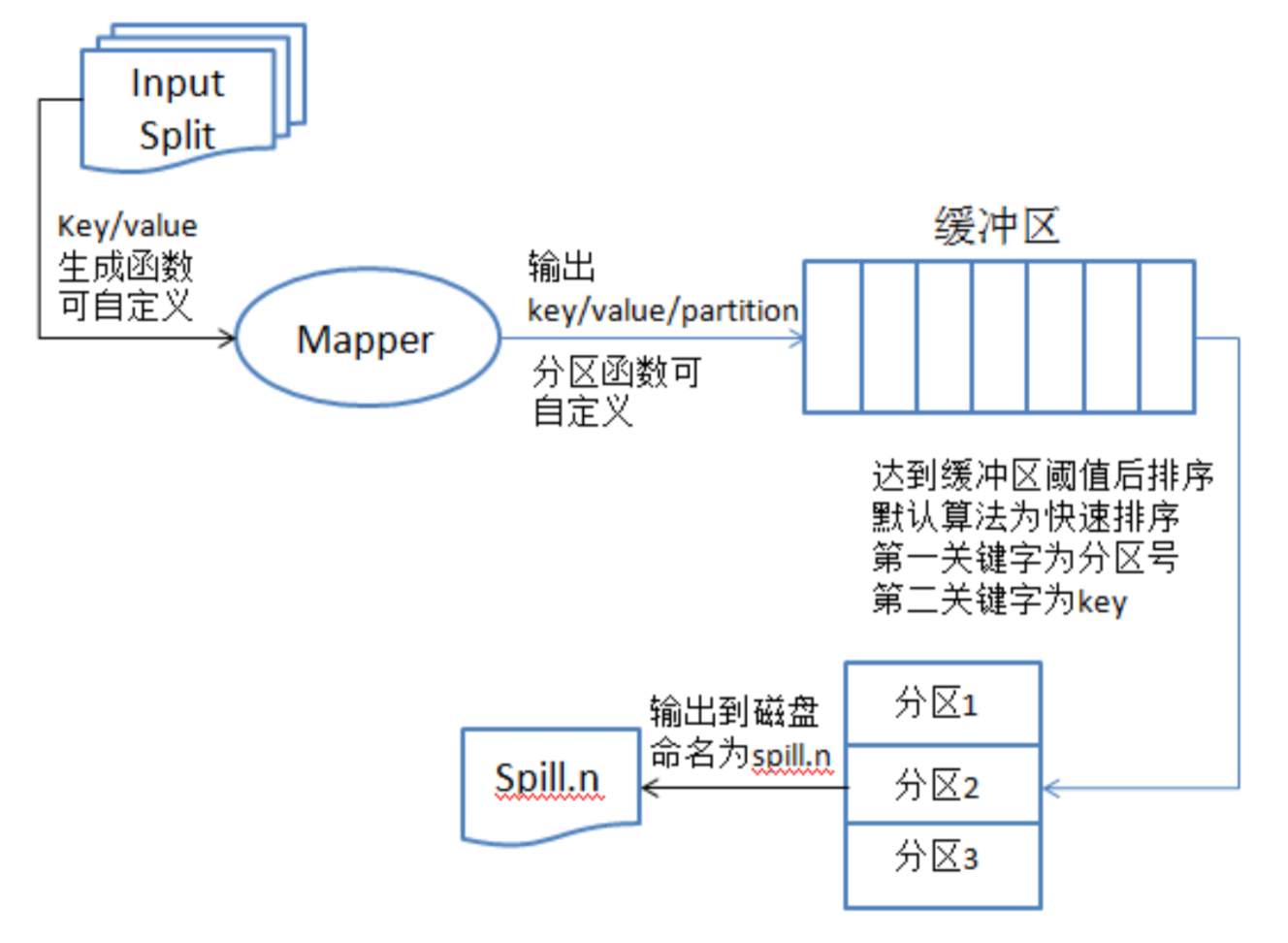
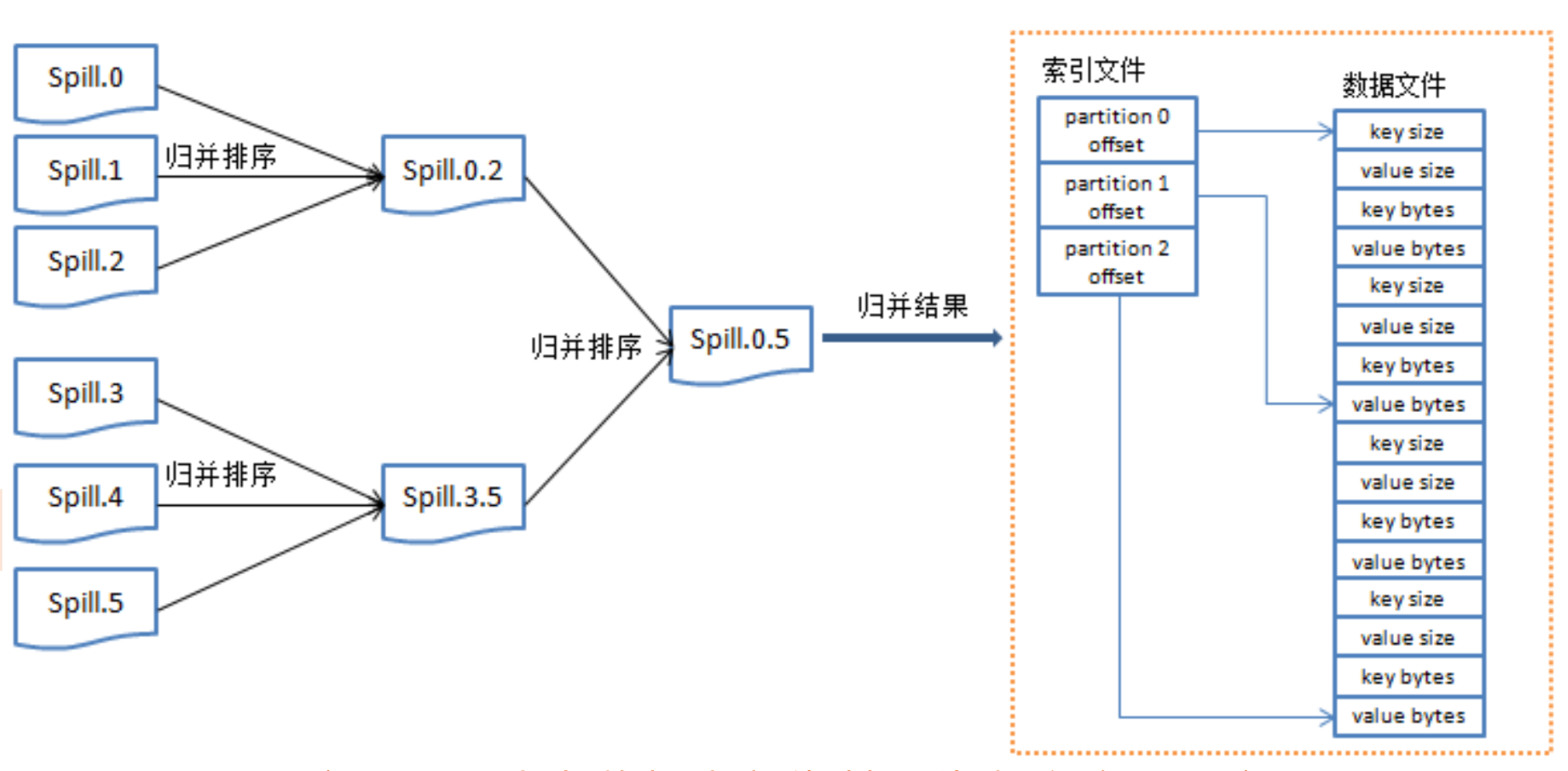

MapReduce原理
- JobTracker 主进程,负责接收客户端作业提交,调度任务到作业节点,并提供监控任务节点状态及任务进度等功能,一个MapReduce集群有一个JobTracker节点
- TaskTraceker 运行JobTracker指派的任务,并且定期的汇报状态,通过心跳实现,每一次心跳包含可用map和reduce任务数目、占用数目以及运行中的任务详情等。
附上具体任务提交流程:
