Redis详解(五)——主从复制
面临问题
- 机器故障。我们部署到一台 Redis 服务器,当发生机器故障时,需要迁移到另外一台服务器并且要保证数据是同步的。而数据是最重要的,如果你不在乎,基本上也就不会使用 Redis 了。
- 容量瓶颈。当我们有需求需要扩容 Redis 内存时,从 16G 的内存升到 64G,单机肯定是满足不了。当然,你可以重新买个 128G 的新机器。
解决办法
要实现分布式数据库的更大的存储容量和承受高并发访问量,我们会将原来集中式数据库的数据分别存储到其他多个网络节点上。
Redis 为了解决这个单一节点的问题,也会把数据复制多个副本部署到其他节点上进行复制,实现 Redis的高可用,实现对数据的冗余备份,从而保证数据和服务的高可用。
主从复制
什么是主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 读写分离:可以用于实现读写分离,主库写、从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库的数量;
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
主从复制启用
从节点开启主从复制,有3种方式:
- 配置文件: 在从服务器的配置文件中加入:slaveof <masterip> <masterport>
- 启动命令: redis-server启动命令后加入 --slaveof <masterip> <masterport>
- 客户端命令: Redis服务器启动后,直接通过客户端执行命令:slaveof <masterip> <masterport>,则该Redis实例成为从节点。
主从复制原理
主从复制过程大体可以分为3个阶段:连接建立阶段(即准备阶段)、数据同步阶段、命令传播阶段。
建立连接阶段
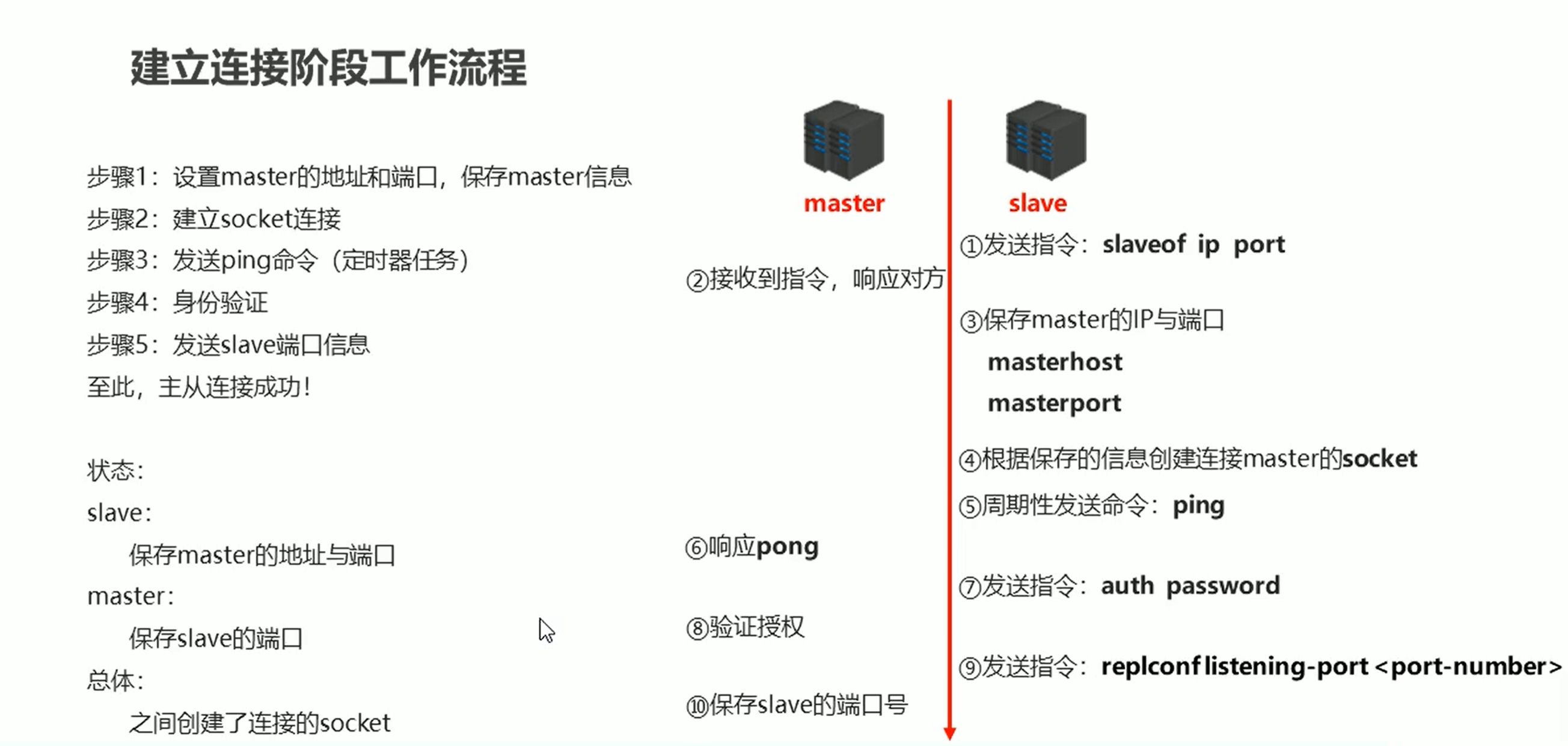
数据同步阶段

注意:
master
- 如果master数据量巨大,数据同步阶段应避开流量高峰期,避免造成master阻塞,影响业务正常进行。
- 复制缓冲区大小设定不合理,会导致数据益处。如进行全量复制周期太长,进行部分复制时发现数据已经存在丢失情况,必须进行第二次全量复制,知识slave陷入死循环。
- master单机内存占用主机内存的比例不应过大,建议使用50%-70%,留下30%-50%的内存用于执行bgsave命令和创建复制缓冲区
slave
- 为了避免slave进行全量复制、部分复制时服务器响应阻塞或数据不同步,建议关闭此期间对外服务
- 多个slave同时对master请求数据同步,master发送的RDB文件会增多,会对带宽造成巨大冲击,如果master带宽不足,因此数据同步需要根据业务需求,适量错峰
- slave过多时,建议调整拓扑结构,由一主多从结构变为树状结构,中间的节点即时master,也是slave。注意使用树状结构时,由于层级深度,导致深度越高的slave与最顶层master间数据同步延迟较大,数据一致性变差,应谨慎选择
命令传播阶段
服务器运行ID(runid)
- 概念:服务器运行ID是每一台服务器每次运行的身份识别码,一台服务器多次运行可以生成多个运行ID
- 组成:运行ID由40位字符组成,是一个随机的16进制字符
- 作用:运行ID被用于在服务器间进行传输,识别身份。如果想两次操作均对同一台服务器进行,必须每次操作携带对应的运行ID,用于对方识别
- 实现方式:运行ID在每台服务器启动时自动生成,master首次连接slave时,会将自己的运行id发送给slave,slave保存 此ID。
设置复制缓冲区的大小
- 测算从master到slave的重连平均时长second
- 获取master平均每秒产生写命令数据总量write_size_per_second
- 最优复制缓冲区大小 = 2 * write_size_per_second


心跳机制
