Redis集群的概念:
RedisCluster是redis的分布式解决方案,在3.0版本后推出的方案,有效地解决了Redis分布式的需求,当一个服务挂了可以快速的切换到另外一个服务,当遇到单机内存、并发等瓶颈时,可使用此方案来解决这些问题
一、分布式数据库概念
1. 分布式数据库把整个数据按分区规则映射到多个节点,即把数据划分到多个节点上,每个节点负责整体数据的一个子集。比如我们库有900条用户数据,有3个redis节点,将900条分成3份,分别存入到3个redis节点
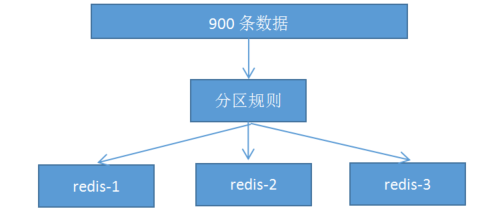
2. 分区规则:
常见的分区规则哈希分区和顺序分区,redis集群使用了哈希分区,顺序分区暂用不到,不做具体说明;
rediscluster采用了哈希分区的“虚拟槽分区”方式(哈希分区分节点取余、一致性哈希分区和虚拟槽分区),其它两种也不做介绍,有兴趣可以百度了解一下
3. 虚拟槽分区(槽:slot)
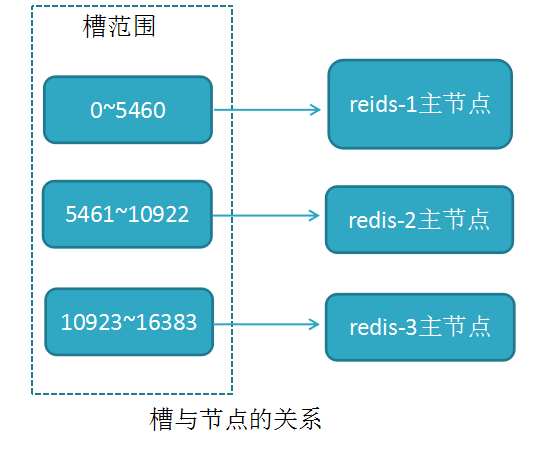
RedisCluster采用此分区,所有的键根据哈希函数(CRC16[key]&16383)映射到0-16383槽内,共16384个槽位,每个节点维护部分槽及槽所映射的键值数据
哈希函数: Hash()=CRC16[key]&16383 按位与
槽与节点的关系如下
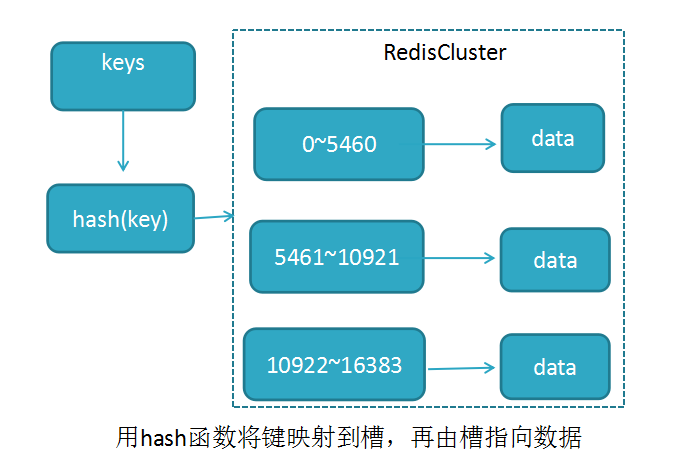
redis用虚拟槽分区原因:解耦数据与节点关系,节点自身维护槽映射关系,分布式存储
4. redisCluster的缺陷:
a,键的批量操作支持有限,比如mset, mget,如果多个键映射在不同的槽,就不支持了
b,键事务支持有限,当多个key分布在不同节点时无法使用事务,同一节点是支持事务
c,键是数据分区的最小粒度,不能将一个很大的键值对映射到不同的节点
d,不支持多数据库,只有0,select 0
e,复制结构只支持单层结构,不支持树型结构。
二、集群环境搭建-手动篇
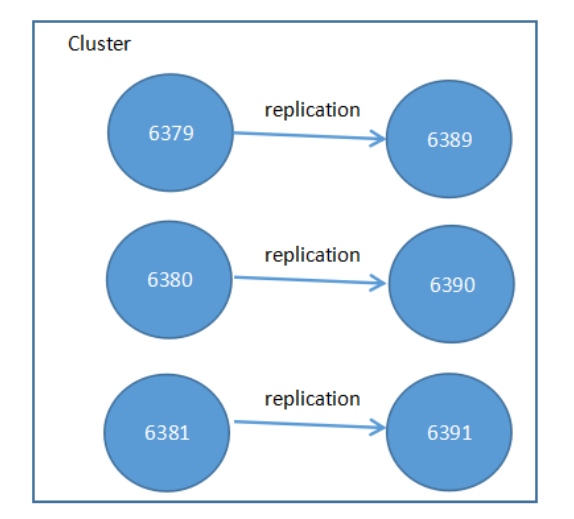
部署结构图:6389为6379的从节点,6390为6380的从节点,6391为6381的从节点
1.在/usr/local/bin/目录下新建一个文件夹clusterconf,用来存放集群的配置文件
2. 分别修改6379、 6380、 7381、 6389、 6390、 6391配置文件
以6379的配置为例:
port 6379 //节点端口
cluster-enabled yes //开启集群模式
cluster-node-timeout 15000 //节点超时时间(接收pong消息回复的时间)
cluster-config-file /usr/localbin/cluster/data/nodes-6379.conf 集群内部配置文件
其它节点的配置和这个一致,改端口即可
3. 配置完后,启动6个redis服务
./redis-server clusterconf/redis6379.conf &
./redis-server clusterconf/redis6380.conf &
./redis-server clusterconf/redis6381.conf &
./redis-server clusterconf/redis6389.conf &
./redis-server clusterconf/redis6390.conf &
./redis-server clusterconf/redis6391.conf &

4. 各节点启动后,使用cluster meet ip port与各节点握手,是集群通信的第一步(关键步骤1:集群搭建-与各节点握手)
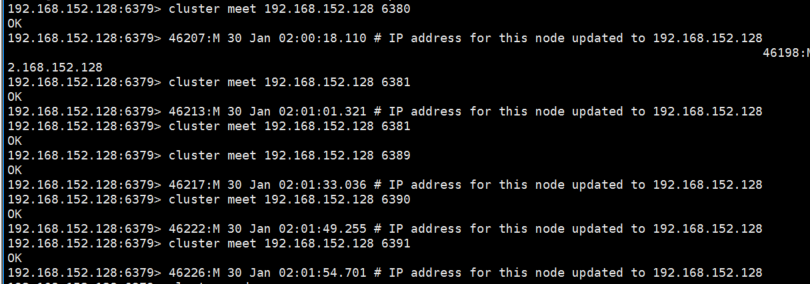
5. 握手成功后,使用cluster nodes可以看到各节点都可以互相查询到

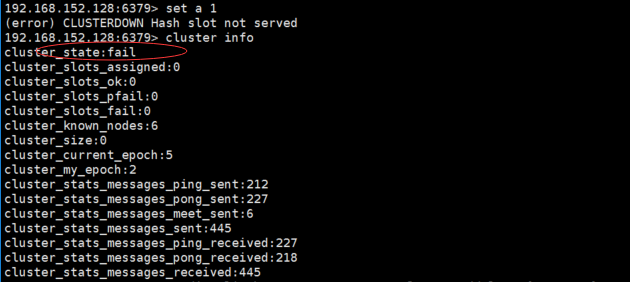
6. 节点握手成功后,此时集群处理下线状态,所有读写都被禁止

7. 使用cluster info命令获取集群当前状态
8. redis集群有16384个哈希槽,要把所有数据映射到16384槽,需要批量设置槽(关键步骤2:集群搭建-分配槽)
redis-cli -h 192.168.152.128 -p 6379 cluster addslots {0...5461}
redis-cli -h 192.168.152.128 -p 6380 cluster addslots {5641...10922}
redis-cli -h 192.168.152.128 -p 6381 cluster addslots {10923...16383}
9. 分配完槽后,可查看集群状态cluster info
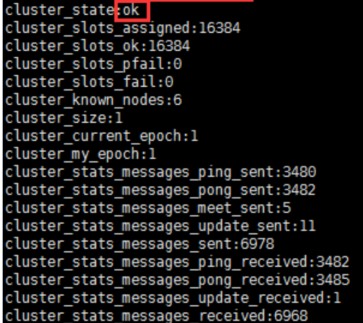
11. 然后再查看cluster nodes,查看每个节点的ID

12. 将6389,6390,6391与 6379,6380,6381做主从映射(关键步骤3:集群搭建-集群映射),到此redis集群手动搭建完成
192.168.152.128:6389> cluster replicate 9b7b0c22f95eb01fb9935ad4b04d396c7f99e881
192.168.152.128:6390> cluster replicate 5351c088472467ae485ed519cea271efda646bfa
92.168.152.128:6391> cluster replicate e718f126278072e1e180c3e518d73e0bc877b3dc
三、集群环境搭建-自动篇
使用ruby来自动分配槽与主从分配,见redis安装文档,建议用此方式完成
1.首先下载ruby-2.3.1.tar.gz 和 redis-3.3.0.gem,然后把这两个工具通过winscp传入linux虚拟机

2. 在/usr/local新建目录:ruby
开始安装第一步中下载的两个软件
tar -zxvf ruby-2.3.1.tar.gz
a) cd /software/rubysoft/ruby-2.3.1
b) ./configure -prefix=/usr/local/ruby
c) make && make install //过程会有点慢,大概5-10分钟
d) 然后gem install -l redis-3.3.0.gem //没有gem需要安装yum install gem或者yum install rubygems
e) 准备好6个节点,(注意不要设置requirepass),将/usr/local/bin/clusterconf/data之前手动配置的config-file文件删除;依次启动6个节点:
./redis-server clusterconf/redis6379.conf
....
如果之前redis有数据存在,flushall清空;(坑:不需要cluster meet ..)
f) 进入cd /usr/local/bin, 执行以下:1代表从节点的个数(最关键的一步:通过这个命令可以自动完成之前手动配置集群的握手、分配槽位、主从映射)
./redis-trib.rb create --replicas 1 192.168.152.128:6379 192.168.152.128:6380 192.168.152.128:6381 192.168.152.128:6389 192.168.152.128:6390 192.168.152.128:6391
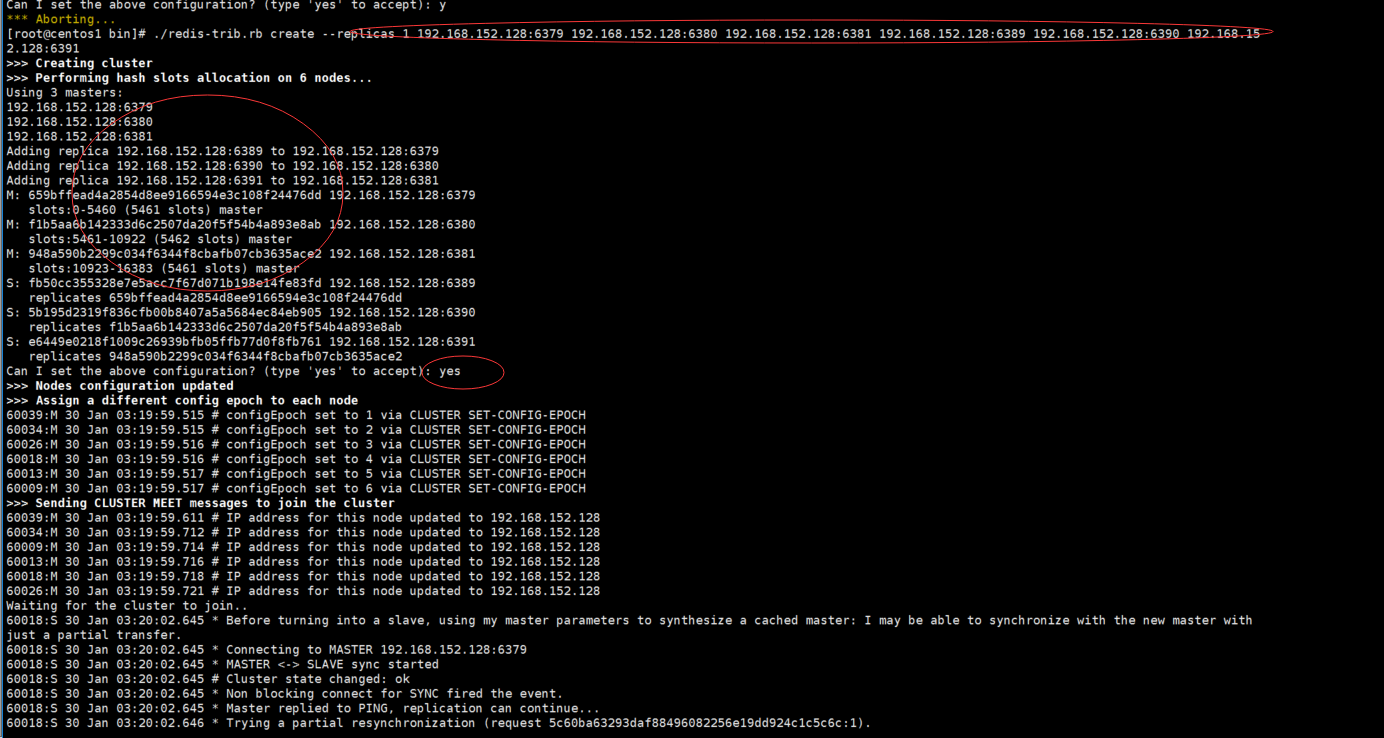
主从分配,6379是6389的主节点,6380是6390的主节点,6381是6391的主节点,

貌似只有主节点可读写,从节点只能读
主节点死后,从节点变成主节点
3.集群搭建好以后开始测试
a) 连入redis集群并设置值./redis-cli -h 192.168.152.128 -p 6379 -c

可以看到设置name以后,重定向到了6380的这个redis,这时因为键name经过CRC16[k]&16284虚拟槽分区算法以后落到了6380这个节点,所以数据就存到了6380这个redis节点
切回6379获取name的值也会通过同样的算法重定向到6380

4.集群健康检查
./redis-trib.rb check 192.168.152.128:6379 (注:redis先去注释掉requirepass,不然连不上)
正常的
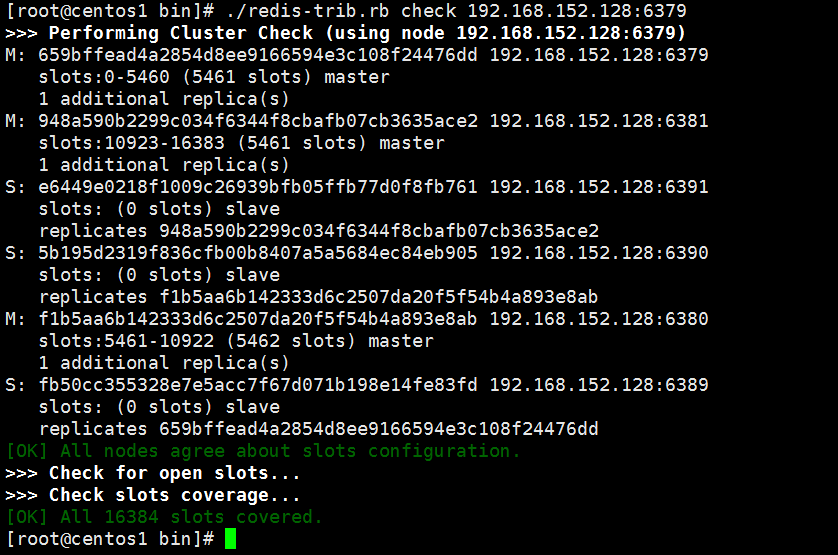
不正常的(来源于网络资源)
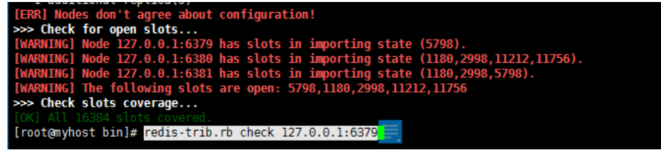
如此出现了这个问题,6379的5798槽位号被打开了
解决如下:

6379,6380,6381的有部分槽位被打开了,分别进入这几个节点,执行
6380:>cluster setslot 1180 stable
cluster setslot 2998 stable
cluster setslot 11212 stable
其它也一样,分别执行修复完后:
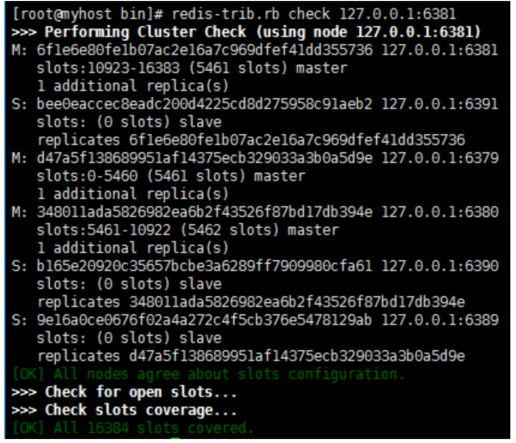
当停掉6379后,过会6389变成主节点
集群正常启动后,在每个redis.conf里加上
masterauth “12345678”
requiredpass “12345678”
当主节点下线时,从节点会变成主节点,用户和密码是很有必要的,设置成一致
5.集群的多主多从

配置如下:
./redis-trib.rb create --replicas 2
192.168.1.111:6379 192.168.1.111:6380 192.168.1.111:6381
192.168.1.111:6479 192.168.1.111:6480 192.168.1.111:6481
192.168.1.111:6579 192.168.1.111:6580 192.168.1.111:6581
6.集群节点之间的通信
1. 节点之间采用Gossip协议进行通信,Gossip协议就是指节点彼此之间不断通信交换信息
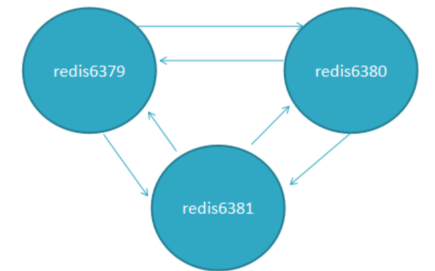
当主从角色变化或新增节点,彼此通过ping/pong进行通信知道全部节点的最新状态并达到集群同步
2. Gossip协议
Gossip协议的主要职责就是信息交换,信息交换的载体就是节点之间彼此发送的Gossip消息,常用的Gossip消息有ping消息、pong消息、meet消息、fail消息

meet消息:用于通知新节点加入,消息发送者通知接收者加入到当前集群,meet消息通信完后,接收节点会加入到集群中,并进行周期性ping pong交换
ping消息:集群内交换最频繁的消息,集群内每个节点每秒向其它节点发ping消息,用于检测节点是在在线和状态信息,ping消息发送封装自身节点和其他节点的状态数据;
pong消息,当接收到ping meet消息时,作为响应消息返回给发送方,用来确认正常通信,pong消息也封闭了自身状态数据;
fail消息:当节点判定集群内的另一节点下线时,会向集群内广播一个fail消息,
3. 消息解析流程
所有消息格式为:消息头、消息体,消息头包含发送节点自身状态数据(比如节点ID、槽映射、节点角色、是否下线等),接收节点根据消息头可以获取到发送节点的相关数据。
消息解析流程:
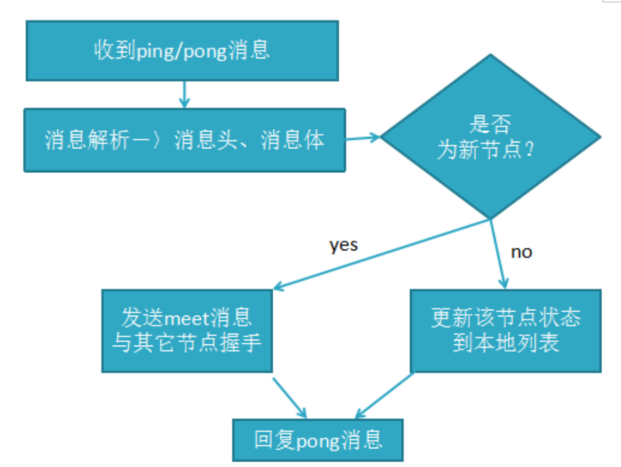
4. 选择节点并发送ping消息:
Gossip协议信息的交换机制具有天然的分布式特性,但ping pong发送的频率很高,可以实时得到其它节点的状态数据,但频率高会加重带宽和计算能力,因此每次都会有目的性地选择一些节点; 但是节点选择过少又会影响故障判断的速度,redis集群的Gossip协议兼顾了这两者的优缺点,看下图:
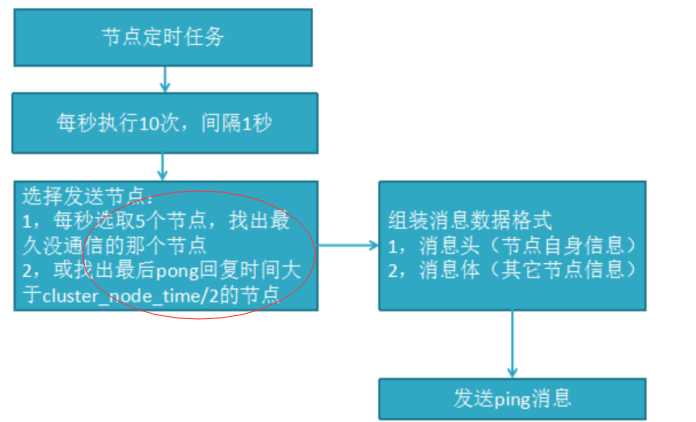
不难看出:节点选择的流程可以看出消息交换成本主要体现在发送消息的节点数量和每个消息携带的数据量
流程说明:
A,选择发送消息的节点数量:集群内每个节点维护定时任务默认为每秒执行10次,每秒会随机选取5个节点,找出最久没有通信的节点发送ping消息,用来保证信息交换的随机性,每100毫秒都会扫描本地节点列表,如果发现节点最近一次接受pong消息的时间大于cluster-node-timeout/2 则立刻发送ping消息,这样做目的是防止该节点信息太长时间没更新,当我们宽带资源紧张时,在可redis.conf将cluster-node-timeout 15000 改成30秒,但不能过度加大
B,消息数据:节点自身信息和其他节点信息
四、redis集群扩容
这也是分布式存储最常见的需求,当我们存储不够用时,要考虑扩容
扩容步骤如下:
A. 准备好新节点
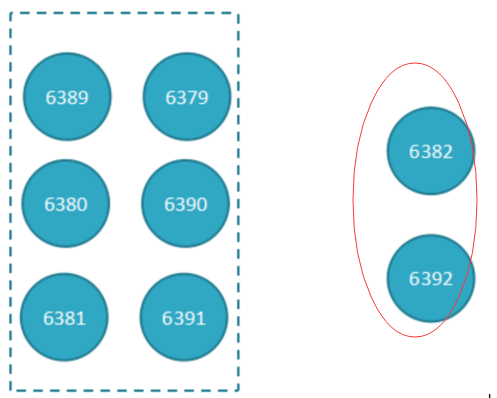
B. 加入集群,迁移槽和数据
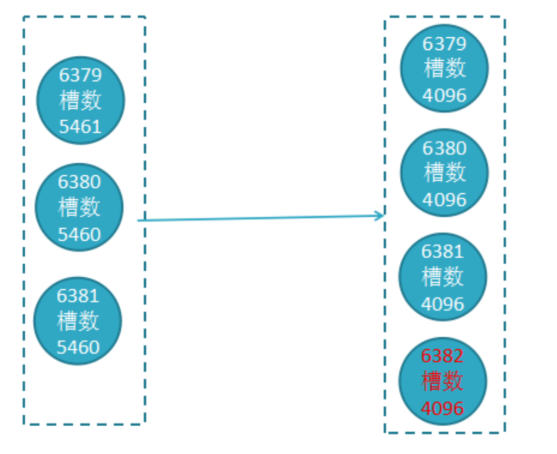
1) 同目录下新增redis6382.conf、redis6392.conf两个redis节点
启动两个新redis节点
./redis-server clusterconf/redis6382.conf & (新主节点)
./redis-server clusterconf/redis6392.conf & (新从节点)
2) 新增主节点
./redis-trib.rb add-node 192.168.152.128:6382 192.168.152.128:6379
6379是原存在的主节点,6382是新的主节点
3),添加从节点
redis-trib.rb add-node --slave --master-id 03ccad2ba5dd1e062464bc7590400441fafb63f2 192.168.152.128:6392 192.168.152.128:6379
--slave,表示添加的是从节点
--master-id 03ccad2ba5dd1e062464bc7590400441fafb63f2表示主节点6382的master_id
192.168.152.128:6392,新从节点
192.168.152.128:6379集群原存在的旧节点
4) redis-trib.rb reshard 192.168.152.128:6382 //为新主节点重新分配solt
How many slots do you want to move (from 1 to 16384)? 1000 //设置slot数1000
What is the receiving node ID? 464bc7590400441fafb63f2 //新节点node id
Source node #1:all //表示全部节点重新洗牌
新增完毕!
五、集群减缩节点
集群同时也支持节点下线掉,下线的流程如下:
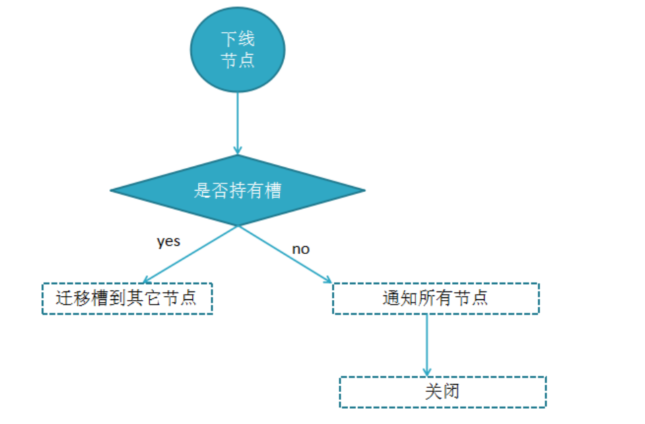
流程说明:
A,确定下线节点是否存在槽slot,如果有,需要先把槽迁移到其他节点,保证整个集群槽节点映射的完整性;
B,当下线的节点没有槽或本身是从节点时,就可以通知集群内其它节点(或者叫忘记节点),当下线节点被忘记后正常关闭。
删除节点也分两种:
一种是主节点6382,一种是从节点6392。
在从节点6392中,没有分配哈希槽,执行
./redis-trib.rb del-node 192.168.1.111:6392 7668541151b4c37d2d9 有两个参数ip:port 和节点的id。 从节点6392从集群中删除了。
主节点6382删除步骤:
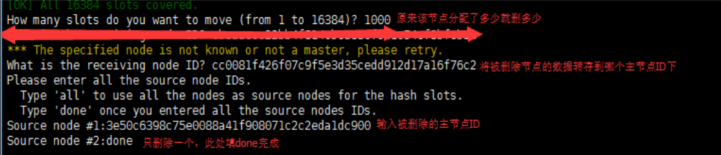
1,./redis-trib.rb reshard 192.168.1.111:6382
问我们有多少个哈希槽要移走,因为我们这个节点上刚分配了1000 个所以我们这里输入1000
2,最后
./redis-trib.rb del-node 192.168.1.111:6382 3e50c6398c75e0088a41f908071c2c2eda1dc900
此时节点下线完成……
六、故障转移
redis集群实现了高可用,当集群内少量节点出现故障时,通过故障转移可以保证集群正常对外提供服务。
当集群里某个节点出现了问题,redis集群内的节点通过ping pong消息发现节点是否健康,是否有故障,其实主要环节也包括了 主观下线和客观下线;
主观下线:指某个节点认为另一个节点不可用,即下线状态,当然这个状态不是最终的故障判定,只能代表这个节点自身的意见,也有可能存在误判;

下线流程:
A,节点a发送ping消息给节点b ,如果通信正常将接收到pong消息,节点a更新最近一次与节点b的通信时间;
B,如果节点a与节点b通信出现问题则断开连接,下次会进行重连,如果一直通信失败,则它们的最后通信时间将无法更新;
节点a内的定时任务检测到与节点b最后通信时间超过cluster_note-timeout时,更新本地对节点b的状态为主观下线(pfail)
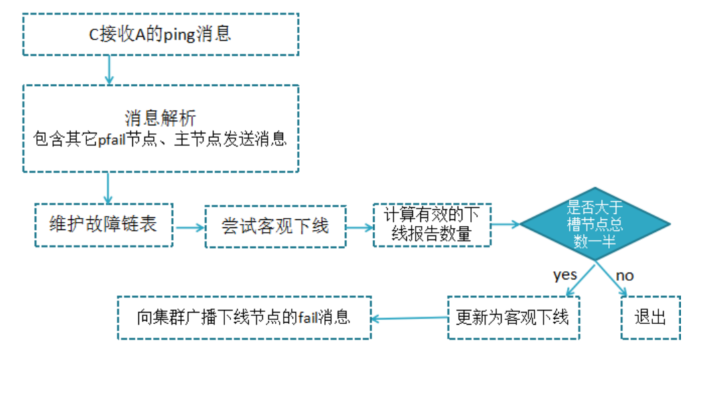
客观下线:指真正的下线,集群内多个节点都认为该节点不可用,达成共识,将它下线,如果下线的节点为主节点,还要对它进行故障转移
假如节点a标记节点b为主观下线,一段时间后节点a通过消息把节点b的状态发到其它节点,当节点c接受到消息并解析出消息体时,会发现节点b的pfail状态时,会触发客观下线流程;
当下线为主节点时,此时redis集群为统计持有槽的主节点投票数是否达到一半,当下线报告统计数大于一半时,被标记为客观下线状态。
故障恢复:
故障主节点下线后,如果下线节点的是主节点,则需要在它的从节点中选一个替换它,保证集群的高可用;转移过程如下:
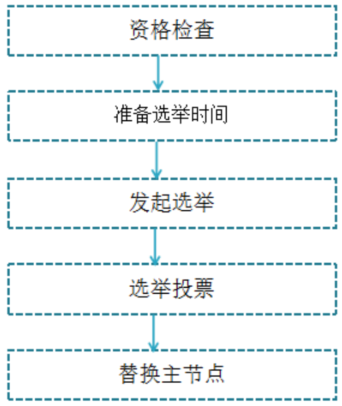
1,资格检查:检查该从节点是否有资格替换故障主节点,如果此从节点与主节点断开过通信,那么当前从节点不具体故障转移;
2,准备选举时间:当从节点符合故障转移资格后,更新触发故障选举时间,只有到达该时间后才能执行后续流程;
3,发起选举:当到达故障选举时间时,进行选举;
4,选举投票:只有持有槽的主节点才有票,会处理故障选举消息,投票过程其实是一个领导者选举(选举从节点为领导者)的过程,每个主节点只能投一张票给从节点,当从节点收集到足够的选票(大于N/2+1)后,触发替换主节点操作,撤销原故障主节点的槽,委派给自己,并广播自己的委派消息,通知集群内所有节点。