一、虚拟机组成
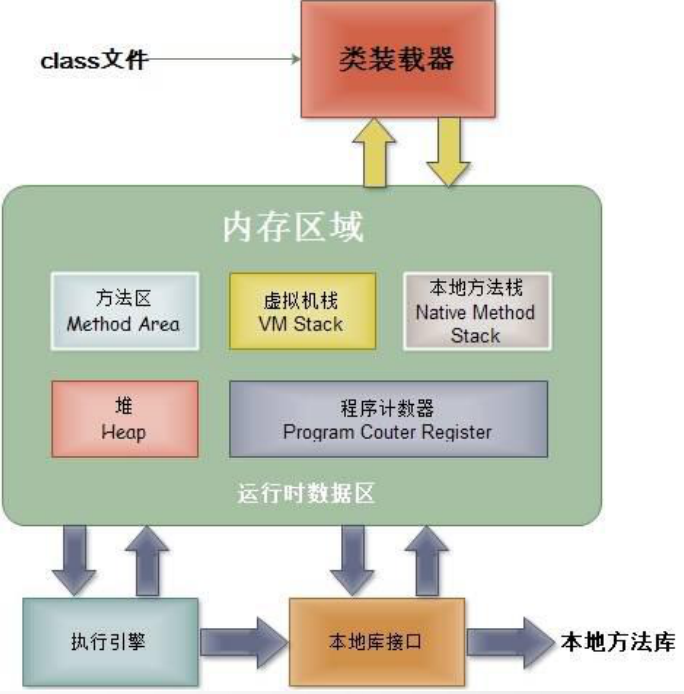
虚拟机主要由三部分组成:编译器(执行引擎),堆与栈。
1. 编译器
编译器分为即时编译器与解释器。
即时编译器将代码编译成本地代码存于code区。因此它快,但它有内存限制!
解释器逐行解释字节码,相当于脚本顺序执行,很慢,性能约为C语言的80%。优化的一部分是使代码尽早进入编译器。将部分代码内联(函数散开于代码中,与编译器无关)。
2. 栈
栈是JVM的函数栈。所有函数必分配于栈。栈中一个帧就是一个函数,因函数之间互相调用,栈帧中包含参数,返回地址,返回值等。第一个参数必然是this指针。递归函数会形成大量的栈帧,搞不好会溢出了。栈的大小可以配置,太大并不好。它是唯一可以配置的地方,其它就不可优化了。
3. 堆
堆是优化的重点,理解为所有对象在堆中。堆划分为年轻代,老年代,持久代(java8是metaspace-使用系统内存,而不是虚拟机堆内存,不再是perm,也就不是持久代了)。年轻代又分为幸存区两个或多个(其中一个必空)及eden(伊甸园区)。
初始的对象在伊甸园区,经过GC收集后,进入存活区,已被收集的对象当然哪也不去,被销毁了。存活区经过15次收集还存活,则进入老年代。存活区满了后交换存活区,并清空原存活区。
老年代最大,因它要放置大对象及长久不消失的对象。
从以上可以看出来堆的优化,就是合理的设置堆内存空间的大小,使之少发生GC,不浪费,不拥挤,不抖动。
JVM的参数分为-X,-XX,-D三种类型。虚拟机自身划分为客户端与server模式。我们当然要用server模式。server模式中编译器默认为混合模式,也就是即时编译器JIT与解释器混合使用。不需要改它。
二、运行原理
1. 执行引擎中的编译器,解释器执行流程
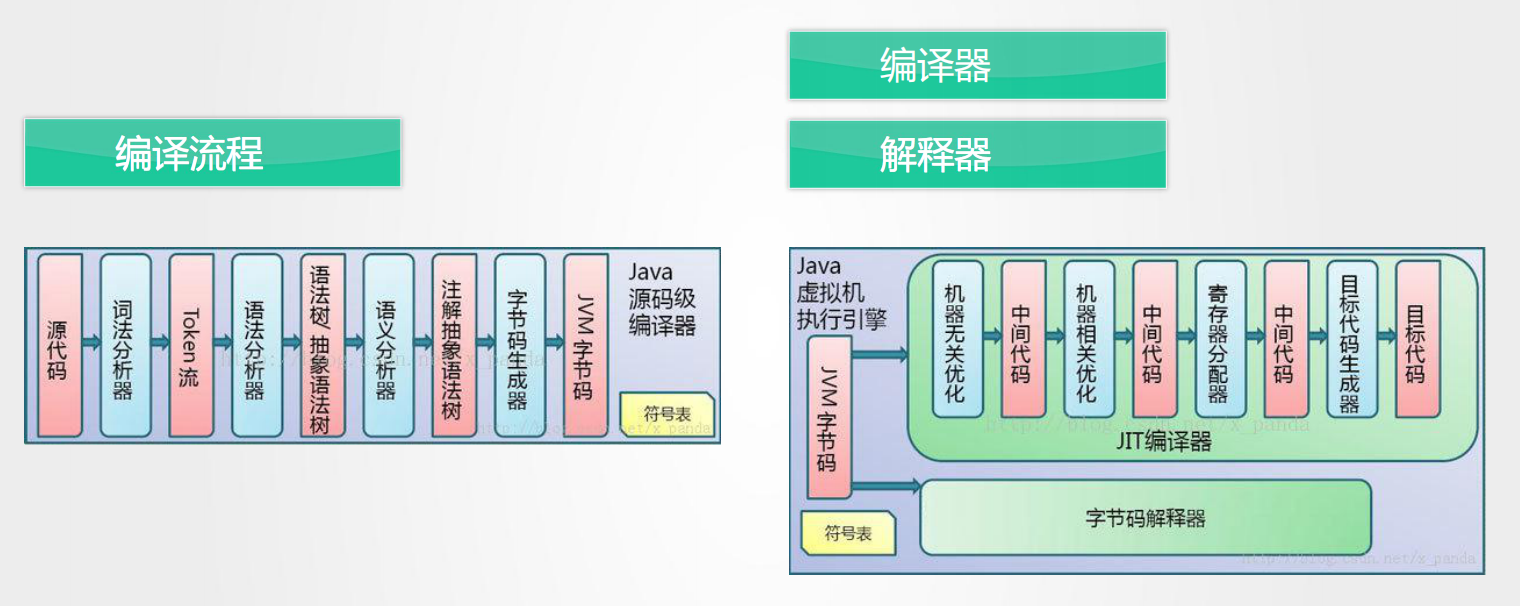
说明:
编译流程把我们编写的源代码经过词法分析器、语法分析器、语义分析器、字节码生成器处理后最终生成JVM的字节码
执行引擎的编译器和解释器获取到编译好的JVM字节码以后执行
编译器会对JVM的字节码进行机器无关的优化(如将字符串的拼接优化为append方式)、机器相关优化、寄存器分配器(将JVM字节码优化为计算机的逻辑门)存放于code区运行
解释器是一行一行的取出代码来执行,性能很慢
2. 内存分配-线程模型

说明:
在Java中一个线程就会相应有一个线程栈与之对应。
堆是所有线程共享的。
栈是运行单位,信息都是跟当前线程(或程序)相关信息的。包括局部变量、程序运行状态、方法返回值等等;
而堆只负责存储对象信息。
栈帧模型
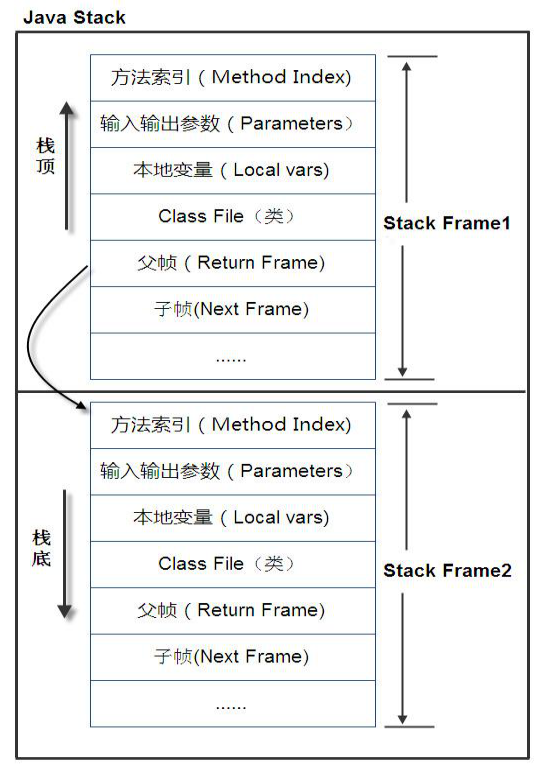
栈帧中包含方法索引、输入输出参数、本地变量、返回地址,返回值等。第一个参数必然是this指针。递归函数会形成大量的栈帧,搞不好会溢出了。栈的大小可以配置,太大并不好。它是唯一可以配置的地方,其它就不可优化了。
三、内存管理
1. 内存分配-堆区介绍

说明:
堆是优化的重点,理解为所有对象在堆中。堆划分为年轻代,老年代,持久代(java8是metaspace-使用系统内存,而不是虚拟机堆内存,不再是perm,也就不是持久代了)。年轻代又分为幸存区两个或多个(其中一个必空)及eden(伊甸园区)。
初始的对象在伊甸园区,经过GC收集后,进入存活区,已被收集的对象当然哪也不去,被销毁了。存活区经过15次收集还存活,则进入老年代。存活区满了后交换存活区,并清空原存活区。
老年代最大,因它要放置大对象及长久不消失的对象。
注意:
Eden区满了进行的是minor GC,老年代满了进行full GC,进行full GC时整个系统会出现卡顿现象,所以堆优化的重点是合理配置堆空间,减少GC,尤其是full GC
2. 堆内存分配

Perm 默认大小64M
NewRatio配比
SurvivorRatio配比
Xmx,Xms,Xmn
四、垃圾回收策略
1. 收集器
1.Serial GC。年轻代使用的收集器,单线程,所有的线程暂停(stop the world)。一般用于Client模式的JVM中。
2.ParNew GC。年轻代使用的收集器,是在SerialGC的基础上,增加了多线程机制。
3.Parrallel Scavenge GC。年轻代使用的收集器,吞吐量优先收集器,吞吐量=程序运行时间/(JVM执行回收的时间+程序运行时间), 运行100分钟,GC占用1分钟,吞吐量=99%。server模式JVM默认配置。
4.ParallelOld。老年代使用的收集器,使用了标记整理算法,是JDK1.6中引进的。
5.Serial Old。老年代使用的收集器,CMS收集器失败后的备用收集器。
6.CMS。老年代使用的收集器,又称响应时间优先回收器,使用标记清除算法。他的回收线程数为(CPU核心数+3)/4,所以当CPU核心数为2时比较高效些。CMS分为4个过程:初始标记、并发标记、重新标记、并发清除
7. G1收集器。年轻代和老年代都使用的收集器,属于现代收集器。面向服务器- server、多CPU,多核、并行与并发、建立可预测的停顿时间模型

2. 确定垃圾-可达性分析
在主流的商用程序语言中(Java和C#),都是使用可达性分析算法判断对象是否存活的。
这个算法的基本思路就是通过一系列名为GC Roots的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连时,则证明此对象是不可用的。
下图对象obj8, obj9, obj10它们到GC Roots是不可达的,所以它们将会判定为是可回收对象。

3. GC算法
3.1、标记-清除(Mark-Sweep)算法
标记-清除算法将垃圾回收分为两个阶段:
①.标记阶段:首先标记出所有需要回收的对象。
②.清除阶段:标记完成后,统一回收被标记的对象
缺点:
①.效率问题:标记清除过程效率都不高。
②.空间问题:标记清除之后会产生大量的不连续的内存碎片(空间碎片太多可能会导致以后在程序运行过程中需要分配较大的对象时,无法找到足够的连续的内存空间而不得不提前触发另一次垃圾收集动作。)

3.2 、标记-整理(Mark-Compact)算法
1).标记阶段:首先标记出所有需要回收的对象。与“标记-清除”一样
2).让存活的对象向内存的一段移动。而不跟“标记-清除”直接对可回收对象进行清理
3).再清理掉边界以外的内存。
由于老年代存活率高,没有额外内存对老年代进行空间担保,那么老年代只能采用标记-清理算法或者标记整理算法。
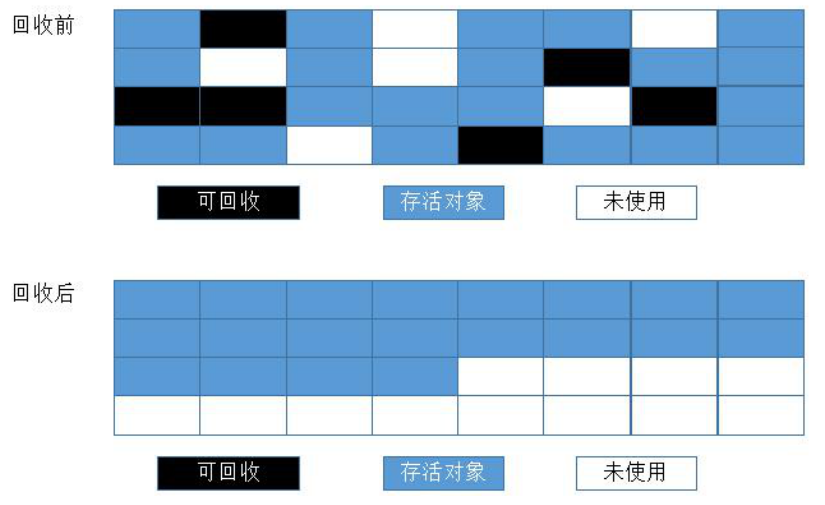
3.3 复制(Copying)算法
3.1.算法思想:
1).将现有的内存空间分为两块,每次只使用一块.
2).当其中一块用完的时候,就将还存活的对象复制到另外一块上去。
3).再把已使用过的内存空间一次清理掉。
3.2.优点:
1).由于是每次都对整个半区进行内存回收,内存分配时不必考虑内存碎片问题。
2).只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。
3.3.缺点:
1).内存减少为原来的一半,太浪费了。
2).对象存活率较高的时候就要执行较多的复制操作,效率变低。
3).如果不使用50%的对分策略,老年代需要考虑的空间担保策略。
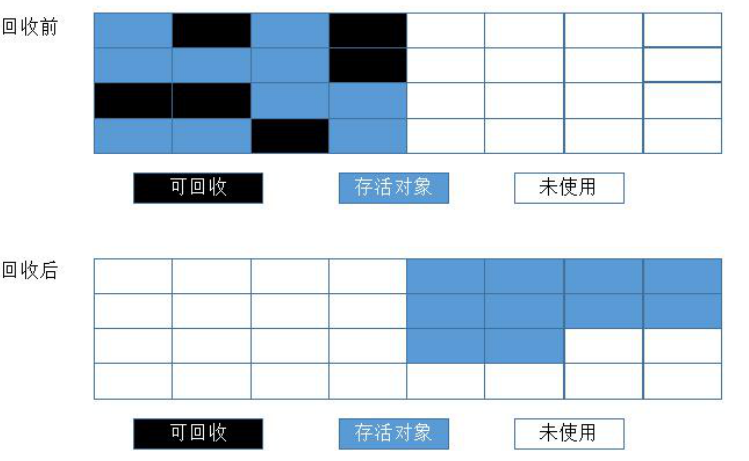
3. 4、分代收集算法
以上三种算法的综合:
在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,选用:复制算法
在老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清除”或者“标记-整理”算法来进行回收。
4. 工具
•jps
•jmap
•Jstat•Jvisualvm: window下启动远程监控,并在被监控服务端,启动jstatd服务。
4.1 jmap工具使用结果说明
命令格式:
jmap [option] <pid>
(to connect to running process)
jmap [option] <executable <core>
(to connect to a core file)
jmap [option] [server_id@]<remote server IP or hostname>
(to connect to remote debug server)
可选项:
where <option> is one of:
<none> to print same info as Solaris pmap
-heap to print java heap summary
-histo[:live] to print histogram of java object heap; if the "live"
suboption is specified, only count live objects
-clstats to print class loader statistics
-finalizerinfo to print information on objects awaiting finalization
-dump:<dump-options> to dump java heap in hprof binary format
dump-options:
live dump only live objects; if not specified,
all objects in the heap are dumped.
format=b binary format
file=<file> dump heap to <file>
Example: jmap -dump:live,format=b,file=heap.bin <pid>
-F force. Use with -dump:<dump-options> <pid> or -histo
to force a heap dump or histogram when <pid> does not
respond. The "live" suboption is not supported
in this mode.
-h | -help to print this help message
-J<flag> to pass <flag> directly to the runtime system
使用示例:
jmap -heap 11892 其中11892是java程序的进程id
运行结果:
Heap Configuration: #堆内存初始化配置 MinHeapFreeRatio = 40 #-XX:MinHeapFreeRatio设置JVM堆最小空闲比率 MaxHeapFreeRatio = 70 #-XX:MaxHeapFreeRatio设置JVM堆最大空闲比率 MaxHeapSize = 100663296 (96.0MB) #-XX:MaxHeapSize=设置JVM堆的最大大小 NewSize = 1048576 (1.0MB) #-XX:NewSize=设置JVM堆的‘新生代’的默认大小 MaxNewSize = 4294901760 (4095.9375MB) #-XX:MaxNewSize=设置JVM堆的‘新生代’的最大大小 OldSize = 4194304 (4.0MB) #-XX:OldSize=设置JVM堆的‘老生代’的大小 NewRatio = 2 #-XX:NewRatio=:‘新生代’和‘老生代’的大小比率 SurvivorRatio = 8 #-XX:SurvivorRatio=设置年轻代中Eden区与Survivor区的大小比值 PermSize = 12582912 (12.0MB) #-XX:PermSize=<value>:设置JVM堆的‘持久代’的初始大小 MaxPermSize = 67108864 (64.0MB) #-XX:MaxPermSize=<value>:设置JVM堆的‘持久代’的最大大小 Heap Usage: New Generation (Eden + 1 Survivor Space): #新生代区内存分布,包含伊甸园区+1个Survivor区 capacity = 30212096 (28.8125MB) used = 27103784 (25.848182678222656MB) free = 3108312 (2.9643173217773438MB) 89.71169693092462% used Eden Space: #Eden区内存分布 capacity = 26869760 (25.625MB) used = 26869760 (25.625MB) free = 0 (0.0MB) 100.0% used From Space: #其中一个Survivor区的内存分布 capacity = 3342336 (3.1875MB) used = 234024 (0.22318267822265625MB) free = 3108312 (2.9643173217773438MB) 7.001809512867647% used To Space: #另一个Survivor区的内存分布 capacity = 3342336 (3.1875MB) used = 0 (0.0MB) free = 3342336 (3.1875MB) 0.0% used tenured generation: #当前的Old区内存分布 capacity = 67108864 (64.0MB) used = 67108816 (63.99995422363281MB) free = 48 (4.57763671875E-5MB) 99.99992847442627% used Perm Generation: #当前的 “持久代” 内存分布(java8已经没有持久代的概念了) capacity = 14417920 (13.75MB) used = 14339216 (13.674942016601562MB) free = 78704 (0.0750579833984375MB) 99.45412375710227% used