输入输出
Bounding Box Regressor 训练过程的输入由两部分组成:
- data:原图或其feature
- label: ground truth bounding box.
regression输出为一组可以确定个bounding box的数值. 数值涵义由label决定.
本文讨论的情况, 即Single box regression: 一张图片回归一个bounding box.
典型的应用出现在RCNN: Proposal太大时, 需要缩小范围以更精确的框出目标物体. 它的regressor的输入为一个proposal region, 输出为一个bounding box.
一个region由一个四维向量表示: , 其中, 为中心点的位置(RCNN)或左上角的位置(Fast RCNN), 为它的宽和高. 它对应的bbox ground truth由表示, 各参数的涵义与类似.
L2 Loss
用表示regressor的输出, 最简单粗暴的loss可以表示为:
其中, 代表, 整个loss : .
也就是说直接预测bbox的绝对坐标与绝对长度. 但是这样会出现一个问题: loss的大小会受到图片大小的影响, 不大合理. 例如, 当ground truth 分别为, 时, 假如分别得到, 的bbox预测值. 那么前者对应的loss会远大于后者, 但是从实际情况上来看, , 前者的相对误差要小于后者. 所以需要一个规范化(normalization)处理. 若在loss上规范化:
其中, 分别为输入图片的宽与高.
这样loss是不受绝对大小的影响了, 但是还有一个问题: 直接输出了绝对距离, 这种输出值是没有上下限的. 目测会让训练过程的收敛变得困难甚至不可能.(个人推测, 未验证/考证.). 另外, 学习速率的选择也会变得困难. 所以, 规范化操作要在label上进行. 即, 将回归目标规范化, 例如RCNN中使用的target为:
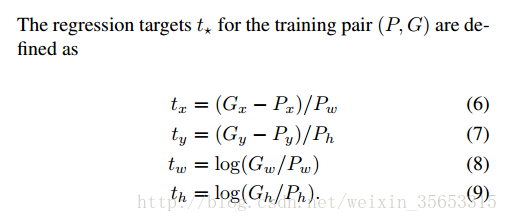
这样回归出来的就是bbox在图片上的相对位置, 各个位置参数的值都是在0到1之间. 比较特殊的是的regression targets使用了log space. 师兄指点说这是为了降低产生的loss的数量级, 让它在loss里占的比重小些, 不至于因为的loss太大而让产生的loss无用. 因为若是没预测准确, 再准确也没有用.
若使用MLP进行回归, 那输出层的激活函数是identity, 即, 其中, 为权重矩阵, 为proposal P的特征向量.
Smooth L1 Loss
当预测值与目标值相差很大时, 梯度容易爆炸, 因为梯度里包含了. 所以rgb在Fast RCNN里提出了SmoothL1Loss.
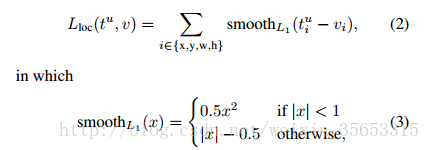
当差值太大时, 原先L2梯度里的被替换成了, 这样就避免了梯度爆炸, 也就是它更加健壮.
Fast-RCNN为了使用SmoothL1Loss定义了一个新的layer, 它的实现更general:
- 可用于指定哪些regression结果参与loss的计算(Fast RCNN里的λ[u ≥ 1], Faster RCNN里的).
- 可用于normalization.