涉及到的知识点补充:
FasterRCNN:https://www.cnblogs.com/wangyong/p/8513563.html
RoIPooling、RoIAlign:https://www.cnblogs.com/wangyong/p/8523814.html
FPN:https://www.cnblogs.com/wangyong/p/8535044.html
首先,先看两张图(第一张图来源于论文,第二张图来源于网络),如下:
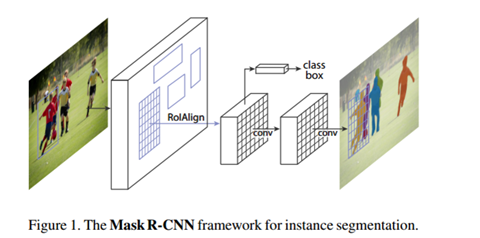
(图1)
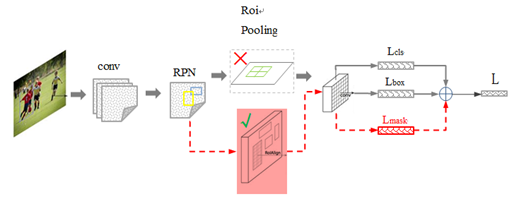
(图2)
图1:可以看出MaskRCNN在有效检测目标的同时输出高质量的实例分割mask
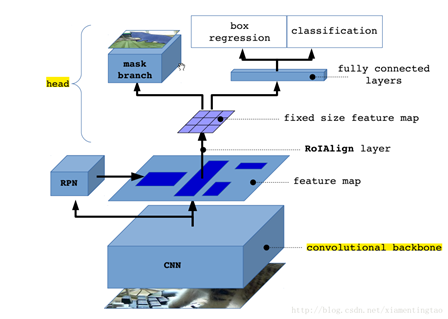
图2:可以看出MaskRCNN的网络结构,作为FasterRCNN的扩展
1):用RolAlign代替了RoIPooling,RoIPooling使用取整量化,导致特征图RoI映射回原图RoI时空间不对齐明显,造成误差;RolAlign不使用取整量化而是采用双线性插值,完成像素级的对齐;
2):FasterRcnn为每个候选对象ROI提供两个输出,一个类标签,一个边界框偏移量,为此,MaskRCNN并行添加了第三个分割mask的分支,mask分支是应用到每一个ROI上的一个小的FCN(Fully Convolutional Network),以pix2pix的方式预测分割mask。
MaskRCNN具有很好的泛化适应能力,可以和多种RCNN框架结合,比较常见的如:
1)FasterRCNN/ResNet;
2)FasterRCNN/FPN
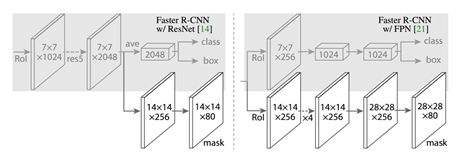
在接下来的文章介绍中则主要结合FPN网络记录MaskRCNN的工作原理
如果要说清楚MaskRCNN的工作原理,先从数据标注开始,知道如何制作数据集,对理解网络有帮助
一)、数据标注
利用labelImg和labelme的源码,整合成一套新的标注工具,同时支持矩形和多边形的绘制,界面如下图(从上到下,从左到右依次是:菜单栏、工具箱、文件列表展示区、主图绘制区、标签展示区、状态栏):
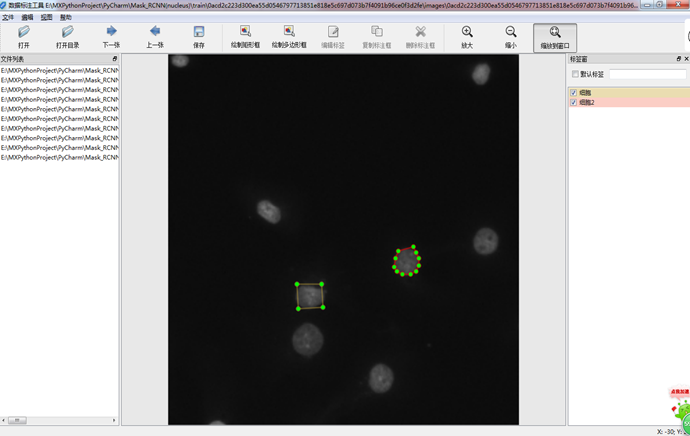
绘制完成,点击保存后,会将图中绘制的点坐标信息保存到JSON文件中,JSON文件的格式如下:
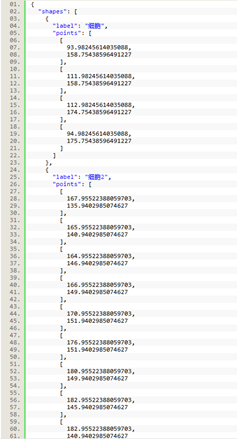

每一张图片会产生一个与其同名的JSON文件,文件夹中的格式如下图所示:
注:一张图片只需对应一张JSON文件即可,而网络在训练的时候需要一个‘mask图片’,这个会在代码中利用JSON中坐标点临时生成
二)、网络原理
MaskRCNN作为FasterRCNN的扩展,产生RoI的RPN网络和FasterRCNN网络一样,如想详细了解这个过程,可以参看文章上述给出的FasterRCNN的博文,这里不太叙述RPN网络的原理,重点看下MaskRCNN其余部分的理解;
源码:https://github.com/matterport/Mask_RCNN
结构:ResNet101+FPN
代码:TensorFlow+ Keras(Python)
代码中将Resnet101网络,分成5个stage,记为[C1,C2,C3,C4,C5];如果了解FPN网络(也可以参看上面提供的FPN网络博文链接),知道这里的5个阶段分别对应着5中不同尺度的feature map输出,用来建立FPN网络的特征金字塔(feature pyramid).
先通过两张MaskRCNN整体网络结构图,再附带一张绘制了stage1和stage2的层次结构图(stage3到stage5的结构层次比较多,未绘制),来整体了解下MaskRCNN网络。
MaskRCNN网络结构泛化图:
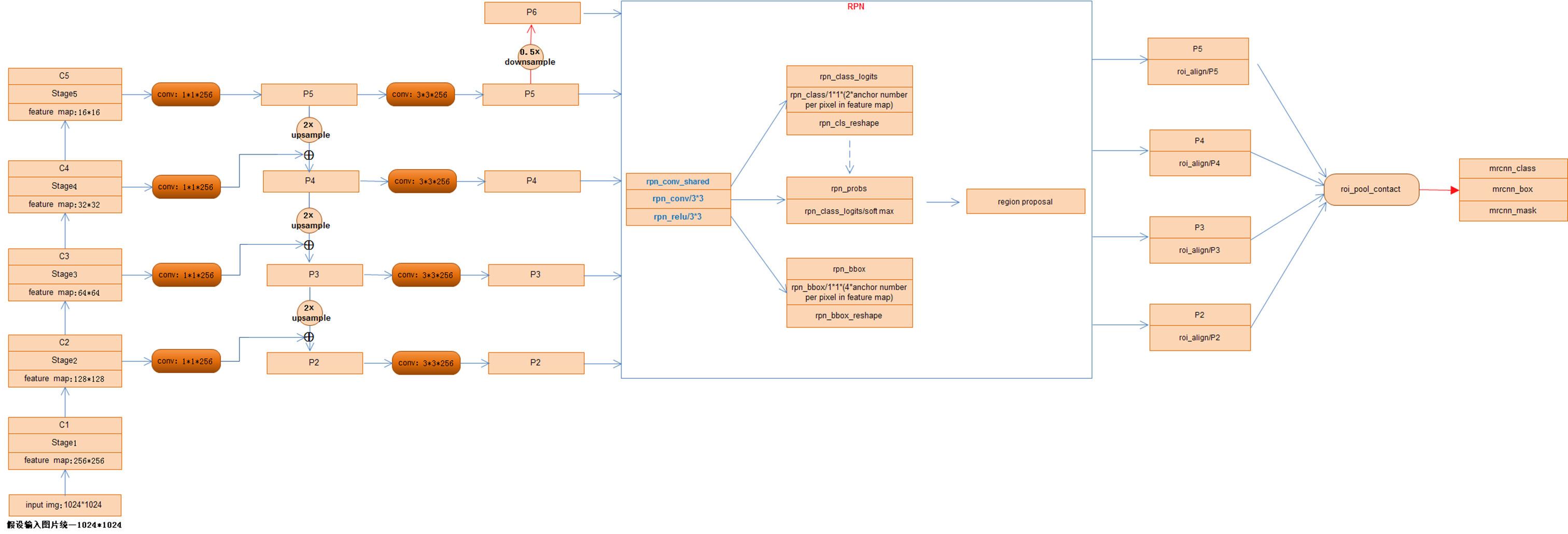
MaskRCNN网络结构细化图(可放大看):
stage1和stage2层次结构图:
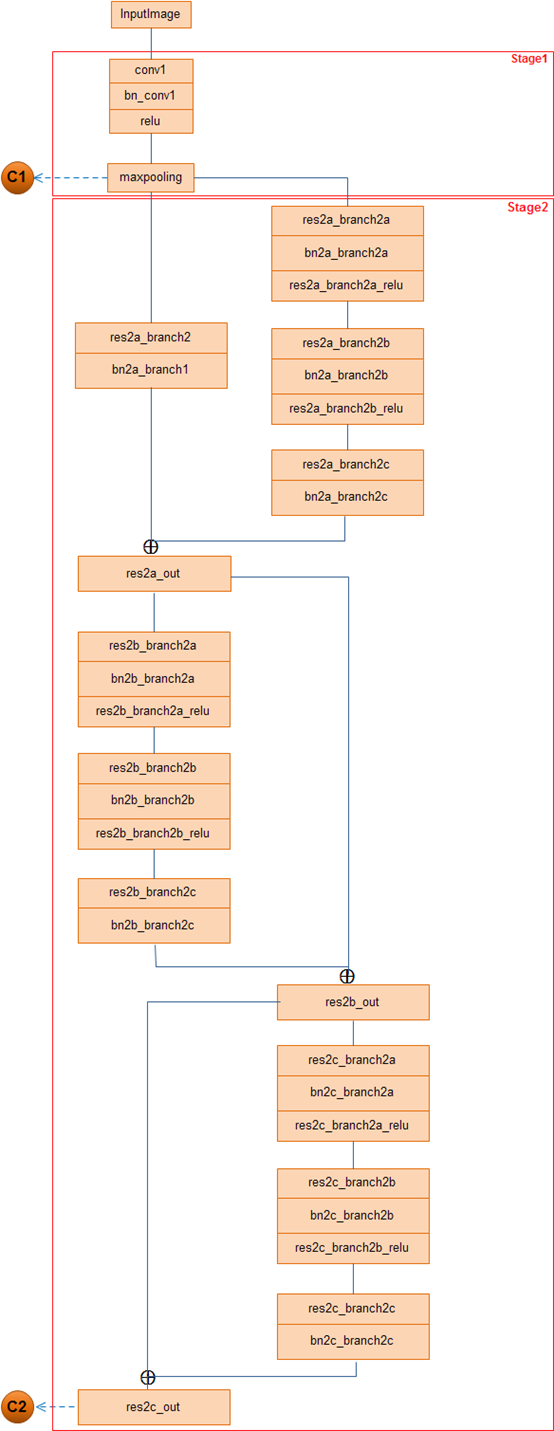
结合MaskRCNN网络结构图,注重点出以下几点:
1) 虽然事先将ResNet网络分为5个stage,但是,并没有利用其中的Stage1即P1的特征,官方的说法是因为P1对应的feature map比较大计算耗时所以弃用;相反,在Stage5即P5的基础上进行了下采样得到P6,故,利用了[P2 P3 P4 P5 P6]五个不同尺度的特征图输入到RPN网络,分别生成RoI.
2)[P2 P3 P4 P5 P6]五个不同尺度的特征图由RPN网络生成若干个anchor box,经过NMS非最大值抑制操作后保留将近共2000个RoI(2000为可更改参数),由于步长stride的不同,分开分别对[P2 P3 P4 P5]四个不同尺度的feature map对应的stride进行RoIAlign操作,将经过此操作产生的RoI进行Concat连接,随即网络分为三部分:全连接预测类别class、全连接预测矩形框box、 全卷积预测像素分割mask
3)损失函数:分类误差+检测误差+分割误差,即L=Lcls+Lbox+Lmask
Lcls、Lbox:利用全连接预测出每个RoI的所属类别及其矩形框坐标值,可以参看FasterRCNN网络中的介绍。
Lmask:
① mask分支采用FCN对每个RoI的分割输出维数为K*m*m(其中:m表示RoI Align特征图的大小),即K个类别的m*m的二值mask;保持m*m的空间布局,pixel-to-pixel操作需要保证RoI特征 映射到原图的对齐性,这也是使用RoIAlign解决对齐问题原因,减少像素级别对齐的误差。
K*m*m二值mask结构解释:最终的FCN输出一个K层的mask,每一层为一类,Log输出,用0.5作为阈值进行二值化,产生背景和前景的分割Mask
这样,Lmask 使得网络能够输出每一类的 mask,且不会有不同类别 mask 间的竞争. 分类网络分支预测 object 类别标签,以选择输出 mask,对每一个ROI,如果检测得到ROI属于哪一个分 类,就只使用哪一个分支的相对熵误差作为误差值进行计算。(举例说明:分类有3类(猫,狗,人),检测得到当前ROI属于“人”这一类,那么所使用的Lmask为“人”这一分支的mask,即,每个class类别对应一个mask可以有效避免类间竞争(其他class不贡献Loss)
② 对每一个像素应用sigmoid,然后取RoI上所有像素的交叉熵的平均值作为Lmask。
由于MaskRCNN网络包含了很多之前介绍过的知识点,例如RPN,FPN,RoIPooling,RoIAlign,故这遍文章看上去显得比较‘单薄’,如果想弄清楚MaskRCNN网络,还是可以需要结合文章一开头提到的几遍博文一起阅读…
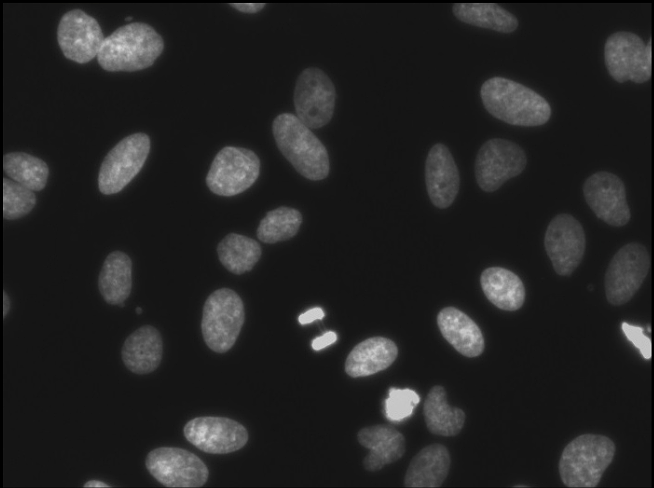
文章开头的时候,利用自己的标注工具,对细胞图片进行标注,每个图片产生一个JSON文件,通过训练后,测试效果如下(标注的图片不是很多,效果还行):

作为一枚技术小白,写这篇笔记的时候参考了很多博客论文,在这里表示感谢,同时,转载请注明出处......
如有疑问,欢迎留言...