转自:https://www.cnblogs.com/cieusy/p/10477167.html
论文阅读 | Region Proposal by Guided Anchoring
相关链接
论文地址:https://arxiv.org/abs/1901.03278
概述
众所周知,anchor策略是目标检测领域的基石。很多目标检测算法的高精度检测都依赖于密集的anchor策略,也就是在空间域上以预设的尺度和宽高比做均匀采样。但是,由于anchor策略产生大量冗余的anchor box,生成数目巨大的低质量负样本,导致正负样本严重失衡,而且还有IoU阈值设置、超参数设计困难等一系列问题。文章提出Guided Anchoring,基于语义特征指导anchor生成。主要思想是定位可能的目标中心点,然后根据中心点设置最优的anchor box。该方法联合预测各个位置可能的目标的中心点以及相应的尺度和宽高比。相比于RPN baseline,使用Guided Anchoring方法在MS COCO数据集上的anchor减少了90%,而召回率则提升了9.1%。此外,将其用于Fast-RCNN、Faster R-CNN以及RetinaNet,检测mAP分别提升了2.2%、2.7%和1.2%。
Guided Anchoring
Guided Anchoring框架如图1所示:
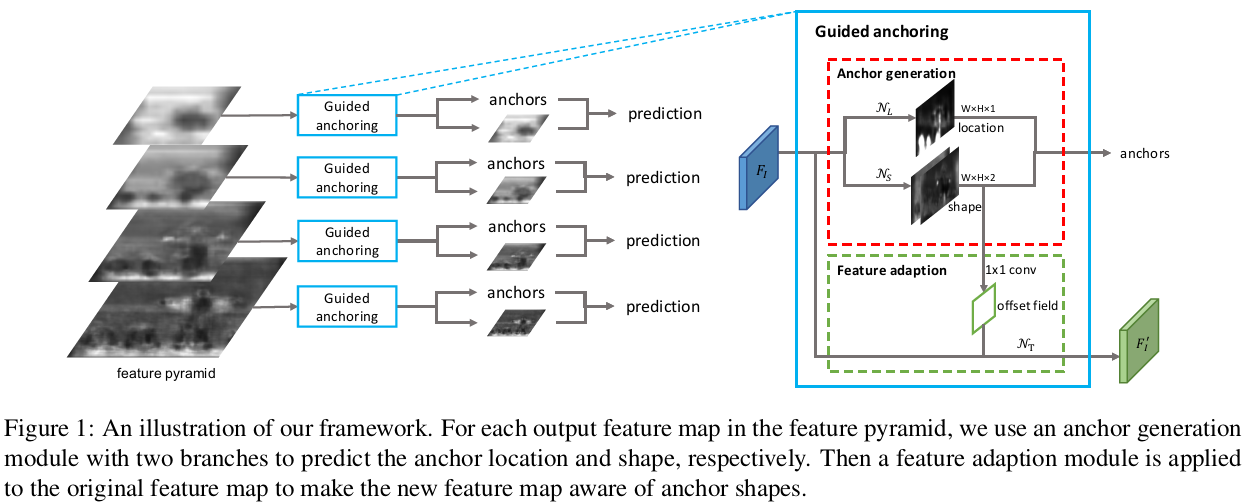
预定义的anchor尺度和宽高比对于不同的数据集和算法需要单独调整。怎样生成稀疏且形状自适应的anchor呢?注意到目标在图像中的分布不均匀,而且目标的尺度也与图像内容、场景的位置和几何形状密切相关。因此分两步生成稀疏的子区域:首先识别可能包含对象的子区域,然后确定不同位置的尺度和宽高比。
将目标的位置和形状用一个四元组表示:(x, y, w, h),其中(x, y)是目标中心坐标,w和h分别是宽和高。则其分布满足:
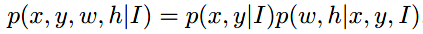
从上面公式可以发现:给定一幅图像I,目标可能只存在于确定的区域;目标的形状与它的位置密切相关。
anchor产生模块示意图如图1红框内。该模块包括位置和形状预测两个部分。首先根据一幅图像I生成feature map FI。top部分,位置预测分支产生目标可能位置的概率图,形状预测分支预测位置相关的形状。根据设定阈值选择位置以及对应位置的最可能的形状生成anchor。考虑到anchor形状不固定,采用一个Feature Adaption模块进行调整。
1.Anchor Location Prediction
anchor预测分支产生一个与feature map FI大小相同的概率图,每个p(i, j | FI)对应图像I的坐标((i + 0.5)s, (j + 0.5)s),其中s是feature map的步长。对基础feature map先通过1*1卷积,然后逐元素Sigmoid转换为概率值。然后根据阈值筛选,可以过滤掉90%的区域而保持相同的召回率。
2.Anchor Shape Prediction
给定一个feature map FI,预测每个位置的最优形状(w, h),也就是与最近的groundtruth的bounding box的IoU最大的shape。考虑到w和h的取值范围较大,所以先做如下转化:
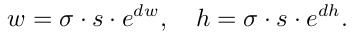
其中s是步长,σ是经验尺度因子(文中取8)。可以将[0, 1000]压缩至[-1, 1]。该分支输出dw和dh。首先通过1*1卷积层产生两个通道的map(包括dw和dh的值),然后经过逐元素转换层实现w和h的转化。
得益于任意形状的anchor,所以对于宽高比夸张的目标也具有更好的效果(比如火车等)。
3.Anchor-Guided Feature Adaptation
由于每个位置的形状不同,大的anchor对应较大感受野,小的anchor对应小的感受野。所以不能像之前基于anchor的方法那样直接对feature map进行卷积来预测,而是要对feature map进行feature adaptation。作者利用变形卷积的思想,根据形状对各个位置单独进行转换:
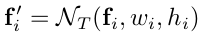
其中,fi是第i个位置的特征,(wi, hi)是对应的anchor形状。NT通过3*3的变形卷积实现。首先通过形状预测分支预测offset field,然后对带偏移的原始feature map做变形卷积获得adapted features。之后进一步做分类和bounding box回归。
4.Training
采用多任务loss进行端到端的训练,损失函数为:
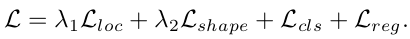
(1)anchor location
利用groundtruth bounding box来指导label生成,1代表有效位置,0代表无效位置。中心附近的anchor应该较多,而远离中心的anchor数目应该少一些。假定R(x, y, w, h)表示以(x, y)为中心,w和h分别为宽高的矩形区域。将groundtruth的bbox(xg, yg, wg, hg)映射到feature map的尺度得到(x'g, y'g, w'g, h'g)。
a.定义中心区域CR=R(x'g, y'g, σ1w', σ1h'),CR区域内的像素标记为正样本;
b.定义ignore区域IR=R(x'g, y'g, σ2w', σ2h')CR,该区域的像素标记为ignore;
c.其余区域标记为外部区域OR,该区域所有像素标记为负样本。
考虑到基于FPN利用了多层feature,所以只有当feature map与目标的尺度范围匹配时才标记为CR,而临近层相同区域标记为IR,如图2所示。文中使用Focal Loss来训练定位分支。

(2)anchor shape
首先将anchor与groundtruth的bbox匹配,然后计算最佳宽和高(可以最大化IoU)。定义变化的anchor与gt bbox的IoU:

变化anchor:awh=(x0, y0, w, h)
groundtruth bbox:gt=(xg, yg, wg, hg)
其中IoUnormal是IoU的常规定义,w和h是变量。采用近似的方法,采样一些可能的w和h。文中采样了9组常见的w、h。实验表明结果对sample的组数不敏感。文中采用有界IoU损失来最大化IoU。
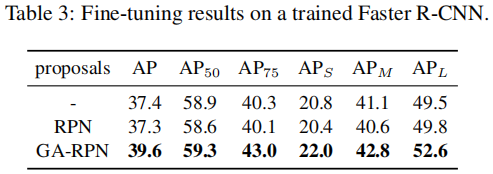
作者使用Guided Anchoring策略来改进RPN(称为GA-RPN)。图3对比了RPN和GA-RPN产生的proposal的IoU分布:
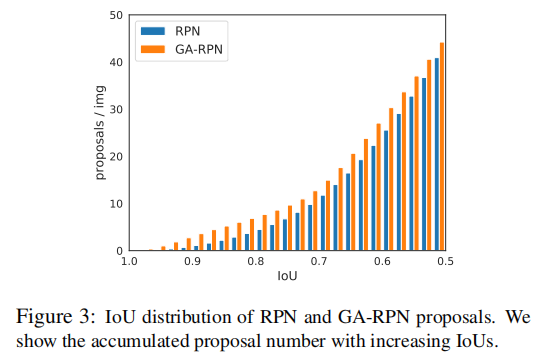


很显然,GA-RPN产生的正样本数目更多,而且高IoU的proposal占的比例更大。训练时相比于RPN,GA-RPN采用更高的阈值、使用更少的样本(使用高质量proposal的前提是根据proposal的分布调整训练样本的分布)。
实验
数据集:MS COCO 2017
backbone:ResNet-50+FPN
image scale:1333*800,σ1 = 0.2,σ2 = 0.5,λ1 = 1, λ2 = 0.1,batchsize:16
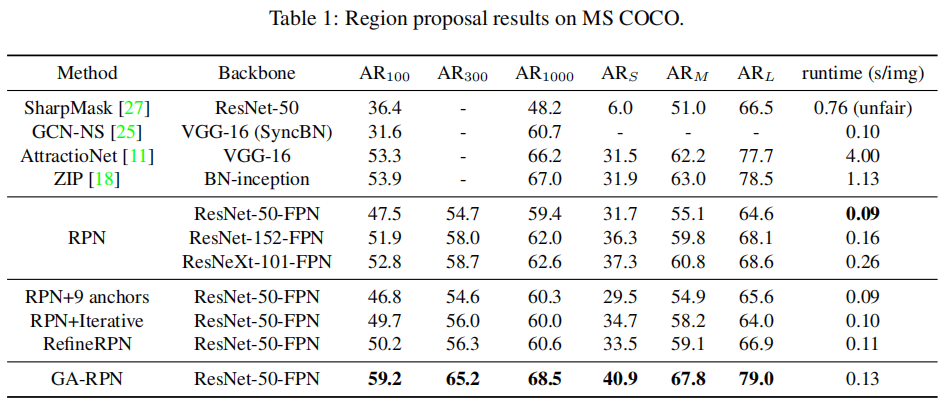
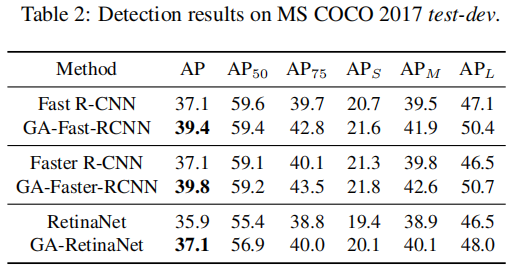
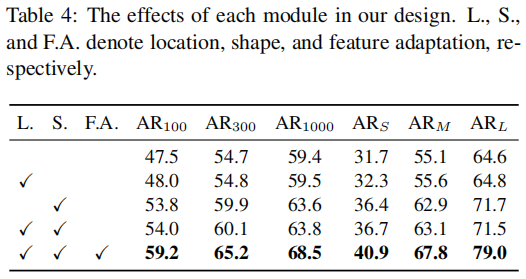
各个模块的对照实验(其中AR*表示每幅图像*个proposal的平均召回率,ARS、ARM、ARL是在100 proposal计算的):
下图显示了滑窗法、GA以及gt产生的anchor的尺度和宽高比分布情况:

可见,GA方法产生的anchor分布更接近groundtruth。
总结
总的来讲,文章贡献主要有以下几点:
提出了一种新的anchor策略,用于产生稀疏的任意形状的anchor;
设计了基于anchor形状的特征适应模块来refine特征;
提出了一种改进模型性能的方案.