转自:https://blog.csdn.net/qq_35976351/article/details/80892902
什么是特征交叉
特征交叉一种合成特征的方法,可以在多维特征数据集上,进行很好的非线性特征拟合。假设一个数据集有特征和,那么引入交叉特征值,使得:
那么最终的表达式为:
为什么进行特征交叉
很多情况下,数据的预测值和各个特征值之间不是线性的关系,比如下图:
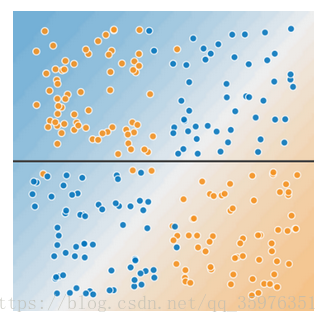
无法找到一个直线把蓝色和黄色的点分离开,此时就等使用特征交叉的方式,进行拟合。当然,也可以使用神经网络。。。。
特征交叉的方式
使用One-Hot向量的方式进行特征交叉。这种方式一般适用于离散的情况,很少用于连续的数据集上。我们可以把特征交叉看成数据的逻辑与操作。
比如给出分档的经纬度数据:
binned_latitude(lat) = [
0 < lat <= 10
10 < lat <= 20
20 < lat <= 30
]
binned_longitude(lon) = [
0 < lon <= 15
15 < lon <= 30
]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
经过交叉后,得到新的数据集:
binned_latitude_X_longitude(lat, lon) = [
0 < lat <= 10 AND 0 < lon <= 15
0 < lat <= 10 AND 15 < lon <= 30
10 < lat <= 20 AND 0 < lon <= 15
10 < lat <= 20 AND 15 < lon <= 30
20 < lat <= 30 AND 0 < lon <= 15
20 < lat <= 30 AND 15 < lon <= 30
]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
特征交叉本质上是一个笛卡尔积,两个特征列进行笛卡尔积。笛卡尔积中,如果同时满足两者的条件,则结果为1;否则为0,因此这种方式更加适合离散型的数据特征。一般来说,先把数据进行分档处理,再把分档的结果进行特征交叉,此时可以获得更好的数据特征,分档处理可以对数据降维,从而极大地简化计算量。
特征交叉的典型应用:
比如在地图的方面的处理中,需要用到特征交叉。下图的房价和经纬度中,单纯的给出经度或者纬度,都不能直接反应房价和地理位置的关系。更好的方式为经度和纬度交叉点,才能表示位置。

图片中,先对数据进行分档处理,也就是精度和纬度分别分割成100的数据段,然后把分段后的数据列进行特征交叉,那么每个房屋会对应一个1000维的特征向量,二维的位置信息会转化成一维的位置向量,只有精确的位置点的数据才是1,其余的都是0