时间久了,有些遗忘,回顾记录一下:
快速排序:
顾名思义,对于c++,快速排序历史上一直是实践中已知最快的泛型排序算法,平均运行时间:O(n*logn),最差就是O(n^2)。
STL中的sort用的就是快排,只不过根据数据量级穿插了别的如插入排序,堆排等算法,进行动态调整,使性能达到最优解。一般来说,对于小数据量n<=20插入排序会更优,减少了快排递归的损耗。
快速排序是一种分治的递归算法。简单来讲,就是先从需要排序的序列中选定一个中心点pivot,然后进行n轮的比较交换,每一轮下来,将序列调整为左右两个部分,小于pivot放在一边,大于pivot的在另外一边。依次类推,再分别按照相同的思路处理左右两部分,直至无法分割为止。
最坏的情况,就是倒序,pivot选择的是第一个,每次分治其实都是分了一个完整的和一个空的,因此相当于没有分,最差O(n^2)。
关于pivot选择:
根据快排思想,pivot的选择在一定程度会决定了算法实现的优劣,如何避免或者说降低最坏的情况的出现呢?
1. 第一元素作为pivot
常见的大部分介绍demo都是选择第一元素,这种对于预排序或者倒序的,很容易出现最坏情况,这绝对是个可怕的坏主意,应该立即放弃这种想法。
2. 随机选择pivot
一般来说这种策略非常安全,除非随机数故障。另外:随机数生成开销显著,根本减少不了算法其余部分的平均运行时间。
3. 三数中值法
一般做法就是,左边,中间,右边,取中间大的那个。这样避免了预排序或者倒序的情况,直接避免了最坏情况,而且能减少很多的比较次数。
代码实现:
1. 双指针循环
2. 单指针循环
//以下3和4暂时没有代码记录,仅作思路参考。
3. 其实这里12都是在数组内部交换排序,如果不在意空间复杂度,更为简便的就是多开几个数组,小于的放入一个,等于的放入一个,大于的放入一个,依次来递归同样可以达到效果,只是无法体现整个算法的交换和排序过程。
4. 非递归的方式:所有递归的方式最终转换非递归都是使用栈或者队列,类似二叉树层序遍历一样,此处同样,分割后的两边的起始与结束可以入栈出栈,直到栈为空来实现。
//中位数选择
int median3(std::vector<int>&vecInt, int start, int end)
{
int center = (start + end) / 2;
//end取最大的
if (vecInt[end] < vecInt[start])
std::swap(vecInt[end], vecInt[start]);
if (vecInt[end] < vecInt[center])
std::swap(vecInt[end], vecInt[center]);
//start取大的那个。
if (vecInt[start] < vecInt[center])
std::swap(vecInt[start], vecInt[center]);
return start;
}
//双指针循环,最后返回分割点
int partion1(std::vector<int>&vecInt, int start, int end)
{
median3(vecInt,start,end);
int pivot = vecInt[start];
int i = start;
int j = end;
while (i < j)
{
//注意顺序, 必须先从右边开始查找,
//i标记小从左到右,最终停留在大值上,j标记大的,最终停留在小的值上面。
//最后循环完成,必然是ij重叠,也就是分界处,此时的值要与原始的pivot交换,因此此值必须要小于pivot
//因此,必须先从j先走,停留在小于的值上面等i。
//否则,如果先从i开始,最终停留在大于pivot上等j,交换后以ij分界,左边就有值大于pivot,逻辑错误。
while (vecInt[j] > pivot && i < j) { j--; }
while (vecInt[i] <= pivot && i < j) { i++; }
if (i < j)
{
std::swap(vecInt[i],vecInt[j]);
}
}
//将pivot放入分界线处i=j
//std::swap(pivot,vecInt[i]);
//i=j时候,pivot的start位置与分界处i交换,否则会覆盖数据
std::swap(vecInt[start], vecInt[i]);
return i;
}
//单指针循环 最后返回分割点
int partion2(std::vector<int>&vecInt, int start, int end)
{
median3(vecInt, start, end);
//pivot标记值,mark标记分界线
int pivot = vecInt[start];
int mark = start;
//从mark后开始比较,遇见小于等于pivot的值,扩充mark范围,往mark位置放。
//最后完成后mark指向分界处,左边小于等于pivot,右边大于
for (int i = start + 1; i <= end; i++)
{
if (vecInt[i] <= pivot)
{
mark++;
std::swap(vecInt[i], vecInt[mark]);
}
}
//最后交换start位置到pivot交换到mark位置
std::swap(vecInt[start], vecInt[mark]);
return mark;
}
//快速排序实现,分治思想
int qSort(vector<int> &vecInt, int start, int end)
{
if (start >= end)
return 0;
int q = partion1(vecInt,start,end);
//递归调用,i的位置为pivot
qSort(vecInt, start, q-1);
qSort(vecInt, q+1, end);
return 0;
}
//快速排序对外接口
int Solution::quickSort(vector<int> &vecInt)
{
if (vecInt.size() <= 1)
return 0;
//
int endIndex = vecInt.size() - 1;
qSort(vecInt, 0, endIndex);
return 0;
}
Demo:
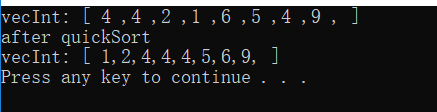
void testQuickSort()
{
std::vector<int> vecInt{ 4,4,2,1,6,5,4,9};
std::cout << "vecInt: [ ";
for (int i = 0; i < vecInt.size(); i++)
{
std::cout << vecInt[i] << " ,";
}
std::cout << " ]" << std::endl;
Solution sl;
std::cout << "after quickSort" << std::endl;
sl.quickSort(vecInt);
std::cout << "vecInt: [ ";
for (int i = 0; i < vecInt.size(); i++)
{
std::cout << vecInt[i] << ",";
}
std::cout << " ]" << std::endl;
}
结果: