1. Django ORM实现原理较为复杂,这里仅讨论元类在其中的部分作用。
-
首先要知道元类是什么
python中一切皆对象,那么定义的类也是对象,而类是由什么创建的呢?
自定义一个类,在使用type()函数,可以看见这个类是type类型的,所以自定义的这个类必然是type创建的。
实际上:类是由元类创建的,当定义一个类时如果没有指定元类,就会一层层向上找,如果父类中也没有指定元类,再向上找模块,模块也没有,就会使用内置的type()来创建类。
如果指定了元类,那么就会改变这一默认行为,使用指定的元类来创建类。
所有自定义的元类都必须继承 type, 且需要重写 __ new __()方法,该方法用来创建实例
它接受四个参数:需要实例化的类对象,类的名字,类继承的父类集合,类的字典属性
可在该方法内控制类对象的生成过程。
-
为何要继承models.Model?
-
自动添加的自增主键
Model指定了元类为ModelBase(继承自type),所有自定义的Model都是由ModelBase创建出来的。ModelBase的__ new __()方法中引用了 _prepare()方法,该方法中判断了是否自定义了主键,如果没有则添加一个自增主键。
-
自动添加的查询管理器
Django会为每一个Model自动添加一个名称为objects的查询管理器,其实现也是在_prepare() 中。最终可知Model.objects并不是一个Manager对象,而是ManagerDescriptor实例,ManagerDescriptor是一个描述符,是对Manager访问的一种保护,主要实现对Model实例和抽象Model的拒绝访问。
利用Manager(objects)就可以实现对Model的增删改查,有些方法还会返回QuerySet,这是怎么实现的呢?
- Manager中并没有定义什么,而是继承了BaseManager.from_queryset(QuerySet),并利用_get_queryset_methods()将一些方法注入给Manager,例如:filter,get,create等。
- _get_queryset_methods()中遍历QuerySet的方法定义,然后跳过BaseManager同名的方法,跳过queryset_only为True的方法,跳过以” _ ”开头的方法,将其他方法注入BaseManagerFromQuerySet中。
-
2. Model的查询API
-
创建Model实例
- 调用Model的save()来创建,先创建一个实例,在保存实例。没有返回值。
- 调用Manager的create()方法,返回Model实例。
-
返回单实例的查询方法
- Manager的get()方法,可同时列出多个查询条件,会抛出两种异常DoesNotExist和MultipleObjectsReturned
- Django支持在查询时使用pk来代替主键名称
- Manager的get_or_create()方法,返回元组(object,created),查到了则返回,否则创建。
- 类似的方法还有first和last,分别返回queryset的第一项与最后一项
- first()效果同使用索引[0],不同的时如果没有查到会报IndexError
- QuerySet不支持负值索引
- Manager的get()方法,可同时列出多个查询条件,会抛出两种异常DoesNotExist和MultipleObjectsReturned
-
返回QuerySet的查询方法
-
Manager的all()方法,返回所有数据实例。
- QuerySet是惰性求值,定义时并不会访问数据库,只有在迭代或者获取个数的时候才会到数据库进行查询
-
reverse()方法,获取全量数据,排列顺序与all相反
-
order_by()方法,可自定义怕徐规则,可指定多个排序字段
- order_by()方法会清除之前的所有排序
- 不传递参数,则没有任何排序规则,默认的也没有
- 传递 ? 代表随机排序,通常无意义且耗时
-
filter()方法,获取全量数据的一个子集,等同于使用where子句过滤不符合条件的记录
- 不传递任何参数等同于all
- 常用查询条件
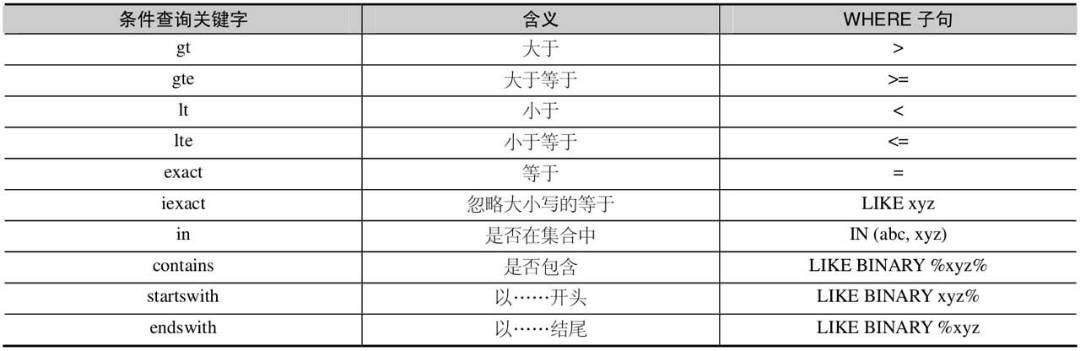
contains(), startswith(), endswith()都有对应的忽略大小写的版本,即在方法名前面添加 字母 i 就可以了
-
exclude()方法,反向过滤,相等于在filter前面加了一个not
- 实际上exclude和filter确实使用了同一个方法,即_filter_or_exclude(),只是用了一个布尔值标记自己的正向过滤还是反向过滤
-
链式查询由于filter,exclude这样的方法返回的是QuerySet,所以可在其后继续调用filter,exclude
-
values()方法获取字典结果,该方法同样会返回QuerySet,但并不是Model的实例对象,而是字典类型,字典的键对应Model的字段名
-
values_list()方法,和values()及其相似,只不过返回的是元组而不是字典,元组元素的顺序与传递的字段顺序相同
-
对QuerySet进行切片操作,例如Comment.objects.all()[:2],QuerySet不支持负值索引
- 切片操作会返回另一个QuerySet,单并不会触发数据库的查询
- 如果使用的是step切片语法,则会触发数据库查询并返回Model实例列表
- 切片后的QuerySet不能再进行过滤和排序操作
-
-
返回RawQuerySet的查询方法
Djang的ORM非常强大,支持使用原生sql语句实现查询
Comment.objects.raw('select * from post_comment')- 不要拼接SQL语句,可能存在注入风险,raw方法提供params参数,接收一个列表或者字典来替换sql语句中的占位符
- RawQuerySet支持索引和切片,但比较低效
-
返回其他类型的查询方法
- count()方法,在 数据库层面执行
select count(*)返回数字类型 - exist()s方法,判断是否存在
- 使用update()方法,更新实例,update只更新特定的列,而save会更新所有的列
- delete()方法,删除实例,返回二元组,第一个元素标识删除的实例个数,第二个元素是字典类型,记录每一个Model类型删除的实例个数,如果两个表存在关联关系,且设置了级联删除,则会一起删除
- count()方法,在 数据库层面执行
3. 存在关联关系的查询
- 反向查询,
小写模型名_set - 跨关联关系查询,双下划线
- 跨关联关系多值查询
- 只使用一个filter,将多个条件写在一个过滤器内,则需要同时满足这多个条件
- 如果使用filter链式调用,虽然总的条件相同,但将不同的条件分开放在不同的filter内,采用链式调用,则可能获取到不同的结果详情点这里
4. F对象与Q对象
-
F对象查询,主要用于 操作数据库中某一列的值,可以在 没有实际访问数据库 的情况下对字段的值进行引用
F对象功能强大,支持跨关联关系。且使用F对象,可以避免线程不安全导致的脏数据。使用F对象,让数据库负责更新过程。F对象描述的是SQl表达式,而不是Python运算。
-
Q对象查询,用于复杂查询,将关键字封装在一起,并传递给filter,exclude,get等方法。多个Q对象可以使用 &,| 进行组合,产生一个新的Q对象。使用 ~可实现NOT查询。Q对象也可以与关键字参数组合在一起,但这种情况下,Q对象必须放在最前面。
5. 聚合与分组查询
- 集合查询
- aggregate是QuerySet的一个终止子句,返回字典类型,键是聚合的标识,值是聚合的结果
- 常用聚合函数:Avg(), Count(), Max(), Min(), Sum()
- 返回字典的键名是Django根据字段名和聚合函数的名称拼接而来的,可以指定名称
- 可以传递多个聚合函数,以 逗号 分隔
- 分组查询
- 默认对每个Model对象都生成一个统计值,通过annotate方法完成,annotate不是终止子句,它返回一个QuerySet对象,可对结果进行在加工。如果annotate前面有values,则先按照values中的字段将Model分组,再对每个分组计算统计值。
- 如果查询语句中含有values(),即在annotate前面有values,则先按照values中指定的字段对Model对象进行分组(相等于GROUP BY),再对每个分组计算统计值。如果Model有默认的排序字段,那么该排序字段也会被自动的加入GROUP BY中,可使用不带参数的order_by()方法将排序清除。
- 如果查询语句中没有values(),而values()在annotate后面,则仅限制需要的字段,没有特殊作用。