作者:王小龙
链接:http://www.zhihu.com/question/26341871/answer/32850703
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:http://www.zhihu.com/question/26341871/answer/32850703
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
最优化,就是:
1. 构造一个合适的目标函数,使得这个目标函数取到极值的解就是你所要求的东西;
2. 找到一个能让这个目标函数取到极值的解的方法。
下面通过两个例子进行解释。
一、图像去噪
假设你手头有一张照片《沙尘暴下依然坚持工作的摄像师》:
 你打算让计算机帮你去个噪,把图像变清晰。你对计算机说:
你打算让计算机帮你去个噪,把图像变清晰。你对计算机说:
 你看,计算机的回复往往是“你丫能不能说机话!”这是因为计算机是无法进行抽象思维的,它不懂重建、去噪、清晰这些复杂的概念,它唯一会的东西就是加减乘除这样的基本运算,你只能使用正确的计算机语句让它去执行对应的基本运算,因此就需要首先把去噪问题转化成一个数学问题,一个函数的求解问题。比如可以试着这样想,去噪,就是要把图像变平滑,于是你对计算机说:给爷来张图片,无比光滑。计算机的回答是:
你看,计算机的回复往往是“你丫能不能说机话!”这是因为计算机是无法进行抽象思维的,它不懂重建、去噪、清晰这些复杂的概念,它唯一会的东西就是加减乘除这样的基本运算,你只能使用正确的计算机语句让它去执行对应的基本运算,因此就需要首先把去噪问题转化成一个数学问题,一个函数的求解问题。比如可以试着这样想,去噪,就是要把图像变平滑,于是你对计算机说:给爷来张图片,无比光滑。计算机的回答是:
 真的是好光滑,但是且慢!摄像师哪去了?你是想光滑图像,但是也需要保留图像中的有用细节。这就说明你设计的目标不合理。一个好的去噪的目标,应该兼顾两个要求:与原始图像尽量接近,并且尽量光滑。一个合适的目标可以是:寻找一幅图像A,让下面这个目标函数J最小:
真的是好光滑,但是且慢!摄像师哪去了?你是想光滑图像,但是也需要保留图像中的有用细节。这就说明你设计的目标不合理。一个好的去噪的目标,应该兼顾两个要求:与原始图像尽量接近,并且尽量光滑。一个合适的目标可以是:寻找一幅图像A,让下面这个目标函数J最小:
J(A) = (A与原始图像尽量接近) + r * (A尽量平滑)
我们要寻找的,就是能让目标函数J最小的图像A,能够兼顾相似和平滑两个要求。因子r用来权衡二者的重要程度。当r取0时,我们得到的最优目标图像就是原始图像自己!因为我们的目标只是相似,而原始图像自己和自己最像,但是这样就没有任何平滑效果;当r取无穷大的时候,为了让整个目标函数J不至于无穷大,我们必须保证A无比平滑,这样就得到上面那张过度平滑,与原始图像毫不相似的无意义图片。因此,为了兼顾两个目标,我们需要把r的值取得不大不小。
有了一个合适的目标函数,下面就需要构造一种获得它的极小值的算法。在图像去噪领域有一大堆算法:卷积去噪、中值去噪、双边滤波、偏微分方程、小波去噪、随机场去噪......它们的作用或多或少都是相同的——求上面那个混合目标函数的最小值。计算机运算获得的去噪图像是:
 从这个成功去噪的例子中我们可以看出:合理的目标函数是最优化第一个需要精心考虑的问题,需要直觉和理性;而如何求解目标函数,则是一个数学算法问题。二者都是数学家们和工程师们大显身手的地方。
从这个成功去噪的例子中我们可以看出:合理的目标函数是最优化第一个需要精心考虑的问题,需要直觉和理性;而如何求解目标函数,则是一个数学算法问题。二者都是数学家们和工程师们大显身手的地方。
二、机器学习
题主困惑机器学习和最优化之间为什么联系紧密,是因为对机器学习这个领域不太了解,实际上研究最优化方法最多的人都在这个领域。机器学习的目的,就是为了让计算机代替人来发现数据之间隐藏的关系。
之所以要使用计算机,是因为数据量太大,远远超过人脑的处理能力。比如我们需要从一堆人脸图片里给每个人标上正确的名字,一幅32像素见方的人脸图像有1024颗像素点,你能想象出一百万张这样的照片和1万个人名字之间的关系是什么样吗。再比如给你1万个患者的DNA序列,每个患者的序列由百万级的碱基对构成,你能找到这些天文数字量级的序列和是否患某种疾病之间的联系吗?
答案是不能!所以研究者退而求其次,建立很多学习模型,这些模型输入是一个样本的数据(头像图片、一个人的DNA序列),输出是样本的标签(人名、是否患病)。模型里有大量可以调整的参数,这些参数通过训练,能够学习到数据和标签之间人类无法直接理解的、复杂的关系。科学家期望当模型训练完成后,再拿来一个样本,喂给这个训练好的机器,它能够吐出一个标签,这个标签恰好就是样本对应的那个正确的标签。
目前人们已经研究出一大堆学习模型:神经网络、支持向量机、AdaBoost、随机森林、隐马尔科夫链、卷积神经网络等等。它们的结构差异很大,但是共同点都是拥有一大堆参数,就等着你喂给它数据供它学习。这些模型的学习也需要一个目标函数:让模型的分类错误率尽量小。为了达到目的,模型的训练往往首先给参数赋上随机初值,然后用各种下降法来寻找能让分类错误率更小的参数设置,梯度下降、牛顿法、共轭梯度法和Levenberg—Marquard法都是常见的方法。
随着研究的深入,问题也越来越多,比如下降法往往只能保证找到目标函数的局部最小值,找不到全局最小值,怎么办呢?答案是不一味下降、也适当爬爬山,说不定能跳出小水沟(局部极小值)找到真正的深井(全局极小值),这种算法叫模拟退火。也可以增大搜索范围,让一群蚂蚁(蚁群算法)或者鸟儿(粒子群算法)一齐搜索,或者让参数巧妙地随机改变(遗传算法)。
那么多模型,到底该选哪个?研究者又发现了一个定理“天下没有免费的午餐”定理,意思是没有一个模型能一直比其他模型好,对于不同类型的数据,必须要通过实验才能发现哪种学习模型更适合。机器学习领域也就成了学界灌水严重的领域之一——换模型、调参数就能发文章哎。
下面说到了调参数,问题又来了,到底是参数多了好还是少了好?参数少了模型太笨学不到数据内的复杂关系,参数多了模型太精明又可能会把数据中的随机噪声当作某种关系进行认真学习(过拟合)。最后大家一致认为,确定模型的复杂度时,要保证模型能力足够强,能够学会数据之间的关系,能力又不能太强,以至于耍小聪明乱学习。这种选择模型的思想被称为奥卡姆剃刀:选择有能力的模型中最简单的那个。此外,训练模型的目标并不是为了使训练样本能够被尽量正确分类,更需要对未知新样本有好的分类效果,这样模型才有实用价值,这种能力被称为泛化能力。除了奥卡姆剃刀原理外,训练时引入随机性的模型比确定的模型(比如BP神经网络)具有更好的泛化能力。
模型的更新也是问题。如果引入了新数据,全部模型都需要重新训练是一笔很大的开销,在线学习模型采用来一个样本学一点的模式,能够不断自我更新;半监督学习利用少量带标签的样本训练一个原始模型,然后利用大量无标签数据再学习。
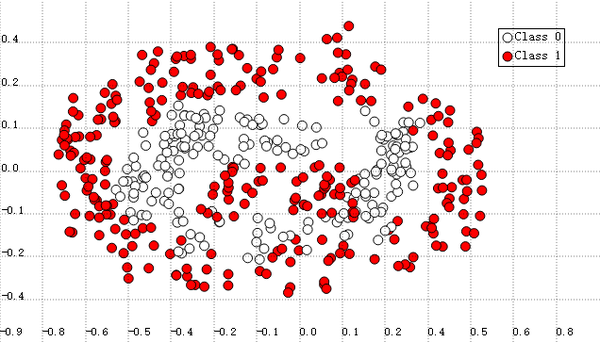
咱们来看看一些经典的学习模型能做成啥样。首先随便画点散点图,红色和白色是两类不同的数据,分类器需要对整个空间做分割,让平均分类错误率尽量小。你可以先想想如果让你来分要如何划分。
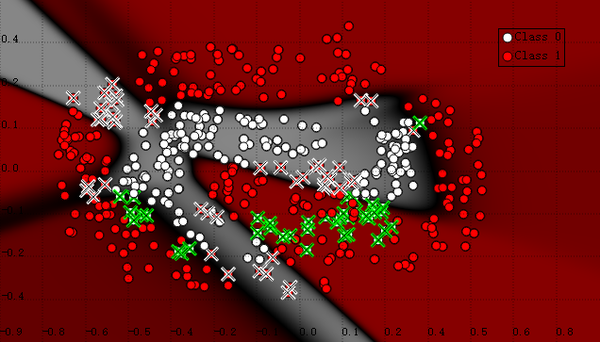
首先是神经网络,使用了6个神经元把空间分成了奇怪的形状:
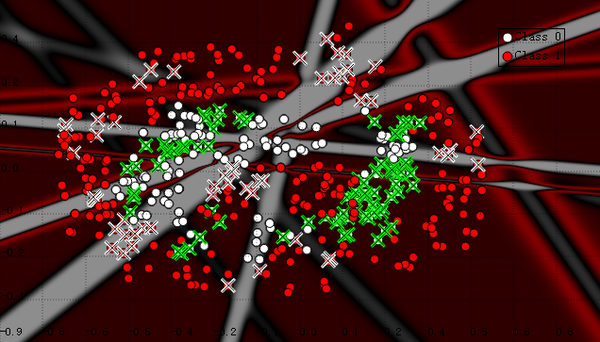
 如果神经元数目变成10个,学到的模式将会十分怪异,说明模型过于复杂了:
如果神经元数目变成10个,学到的模式将会十分怪异,说明模型过于复杂了:
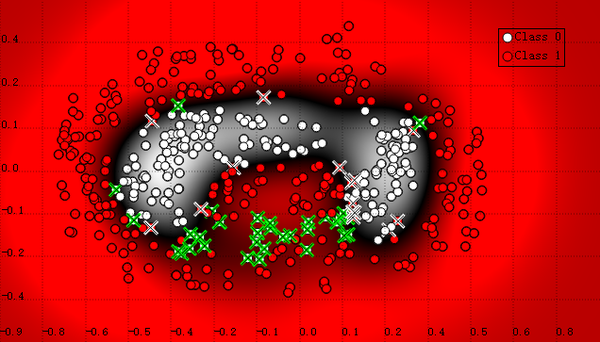
 下面是支持向量机的分类结果,这是这几十年机器学习最重要的成果之一,它的发明是基于结构最小化准则,通俗地讲就是把目标函数设为:
下面是支持向量机的分类结果,这是这几十年机器学习最重要的成果之一,它的发明是基于结构最小化准则,通俗地讲就是把目标函数设为:
J=模型分类正确率 + r * 模型复杂度
使得模型能够自动选择分类效果好,并且尽量简单的参数。
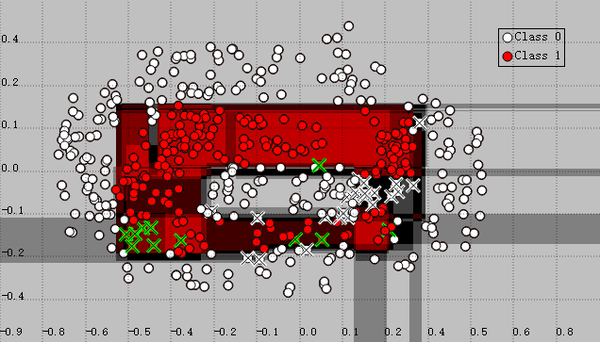
接下来是随机树,它把空间划分为一系列矩形区域(叶子),所有的叶子区域由一颗树形结构从根节点不断划分而成,随机的意思是树的生长每次划分第一维还是第二维是随机的:
支持向量机对于小样本数据和非线性结构数据的分类有十分优秀的表现:


在机器学习领域,还有很多重要问题被不断讨论,优秀的模型也不断在涌现。这个领域的开山模型是神经元,由其组成的多层神经网络由于训练速度慢、分类效果不佳,在支持向量机出现后很快就失去了热度。大家卯着劲研究怎么面对训练样本不足的窘境,PCA和核方法大行其道,前者致力于减少数据维数,后者致力于从低维数据中学习高维结构。但是近几年随着卷积神经网络的流行,神经网络又焕发出了第二春,研究者发现只要样本量足够大(百万级甚至亿级样本量),网络参数足够多(百万级参数),加上巧妙的防过拟合技术,利用现代并行计算带来的强大计算能力,神经网络能够学得和人类的判别能力一样好。机器学习领域发展了几十年,似乎又回到了出发的地方。
1. 构造一个合适的目标函数,使得这个目标函数取到极值的解就是你所要求的东西;
2. 找到一个能让这个目标函数取到极值的解的方法。
下面通过两个例子进行解释。
一、图像去噪
假设你手头有一张照片《沙尘暴下依然坚持工作的摄像师》:
你打算让计算机帮你去个噪,把图像变清晰。你对计算机说:你看,计算机的回复往往是“你丫能不能说机话!”这是因为计算机是无法进行抽象思维的,它不懂重建、去噪、清晰这些复杂的概念,它唯一会的东西就是加减乘除这样的基本运算,你只能使用正确的计算机语句让它去执行对应的基本运算,因此就需要首先把去噪问题转化成一个数学问题,一个函数的求解问题。比如可以试着这样想,去噪,就是要把图像变平滑,于是你对计算机说:给爷来张图片,无比光滑。计算机的回答是:真的是好光滑,但是且慢!摄像师哪去了?你是想光滑图像,但是也需要保留图像中的有用细节。这就说明你设计的目标不合理。一个好的去噪的目标,应该兼顾两个要求:与原始图像尽量接近,并且尽量光滑。一个合适的目标可以是:寻找一幅图像A,让下面这个目标函数J最小:J(A) = (A与原始图像尽量接近) + r * (A尽量平滑)
我们要寻找的,就是能让目标函数J最小的图像A,能够兼顾相似和平滑两个要求。因子r用来权衡二者的重要程度。当r取0时,我们得到的最优目标图像就是原始图像自己!因为我们的目标只是相似,而原始图像自己和自己最像,但是这样就没有任何平滑效果;当r取无穷大的时候,为了让整个目标函数J不至于无穷大,我们必须保证A无比平滑,这样就得到上面那张过度平滑,与原始图像毫不相似的无意义图片。因此,为了兼顾两个目标,我们需要把r的值取得不大不小。
有了一个合适的目标函数,下面就需要构造一种获得它的极小值的算法。在图像去噪领域有一大堆算法:卷积去噪、中值去噪、双边滤波、偏微分方程、小波去噪、随机场去噪......它们的作用或多或少都是相同的——求上面那个混合目标函数的最小值。计算机运算获得的去噪图像是:
从这个成功去噪的例子中我们可以看出:合理的目标函数是最优化第一个需要精心考虑的问题,需要直觉和理性;而如何求解目标函数,则是一个数学算法问题。二者都是数学家们和工程师们大显身手的地方。二、机器学习
题主困惑机器学习和最优化之间为什么联系紧密,是因为对机器学习这个领域不太了解,实际上研究最优化方法最多的人都在这个领域。机器学习的目的,就是为了让计算机代替人来发现数据之间隐藏的关系。
之所以要使用计算机,是因为数据量太大,远远超过人脑的处理能力。比如我们需要从一堆人脸图片里给每个人标上正确的名字,一幅32像素见方的人脸图像有1024颗像素点,你能想象出一百万张这样的照片和1万个人名字之间的关系是什么样吗。再比如给你1万个患者的DNA序列,每个患者的序列由百万级的碱基对构成,你能找到这些天文数字量级的序列和是否患某种疾病之间的联系吗?
答案是不能!所以研究者退而求其次,建立很多学习模型,这些模型输入是一个样本的数据(头像图片、一个人的DNA序列),输出是样本的标签(人名、是否患病)。模型里有大量可以调整的参数,这些参数通过训练,能够学习到数据和标签之间人类无法直接理解的、复杂的关系。科学家期望当模型训练完成后,再拿来一个样本,喂给这个训练好的机器,它能够吐出一个标签,这个标签恰好就是样本对应的那个正确的标签。
目前人们已经研究出一大堆学习模型:神经网络、支持向量机、AdaBoost、随机森林、隐马尔科夫链、卷积神经网络等等。它们的结构差异很大,但是共同点都是拥有一大堆参数,就等着你喂给它数据供它学习。这些模型的学习也需要一个目标函数:让模型的分类错误率尽量小。为了达到目的,模型的训练往往首先给参数赋上随机初值,然后用各种下降法来寻找能让分类错误率更小的参数设置,梯度下降、牛顿法、共轭梯度法和Levenberg—Marquard法都是常见的方法。
随着研究的深入,问题也越来越多,比如下降法往往只能保证找到目标函数的局部最小值,找不到全局最小值,怎么办呢?答案是不一味下降、也适当爬爬山,说不定能跳出小水沟(局部极小值)找到真正的深井(全局极小值),这种算法叫模拟退火。也可以增大搜索范围,让一群蚂蚁(蚁群算法)或者鸟儿(粒子群算法)一齐搜索,或者让参数巧妙地随机改变(遗传算法)。
那么多模型,到底该选哪个?研究者又发现了一个定理“天下没有免费的午餐”定理,意思是没有一个模型能一直比其他模型好,对于不同类型的数据,必须要通过实验才能发现哪种学习模型更适合。机器学习领域也就成了学界灌水严重的领域之一——换模型、调参数就能发文章哎。
下面说到了调参数,问题又来了,到底是参数多了好还是少了好?参数少了模型太笨学不到数据内的复杂关系,参数多了模型太精明又可能会把数据中的随机噪声当作某种关系进行认真学习(过拟合)。最后大家一致认为,确定模型的复杂度时,要保证模型能力足够强,能够学会数据之间的关系,能力又不能太强,以至于耍小聪明乱学习。这种选择模型的思想被称为奥卡姆剃刀:选择有能力的模型中最简单的那个。此外,训练模型的目标并不是为了使训练样本能够被尽量正确分类,更需要对未知新样本有好的分类效果,这样模型才有实用价值,这种能力被称为泛化能力。除了奥卡姆剃刀原理外,训练时引入随机性的模型比确定的模型(比如BP神经网络)具有更好的泛化能力。
模型的更新也是问题。如果引入了新数据,全部模型都需要重新训练是一笔很大的开销,在线学习模型采用来一个样本学一点的模式,能够不断自我更新;半监督学习利用少量带标签的样本训练一个原始模型,然后利用大量无标签数据再学习。
咱们来看看一些经典的学习模型能做成啥样。首先随便画点散点图,红色和白色是两类不同的数据,分类器需要对整个空间做分割,让平均分类错误率尽量小。你可以先想想如果让你来分要如何划分。
首先是神经网络,使用了6个神经元把空间分成了奇怪的形状:
如果神经元数目变成10个,学到的模式将会十分怪异,说明模型过于复杂了:下面是支持向量机的分类结果,这是这几十年机器学习最重要的成果之一,它的发明是基于结构最小化准则,通俗地讲就是把目标函数设为:J=模型分类正确率 + r * 模型复杂度
使得模型能够自动选择分类效果好,并且尽量简单的参数。
接下来是随机树,它把空间划分为一系列矩形区域(叶子),所有的叶子区域由一颗树形结构从根节点不断划分而成,随机的意思是树的生长每次划分第一维还是第二维是随机的:
支持向量机对于小样本数据和非线性结构数据的分类有十分优秀的表现:
在机器学习领域,还有很多重要问题被不断讨论,优秀的模型也不断在涌现。这个领域的开山模型是神经元,由其组成的多层神经网络由于训练速度慢、分类效果不佳,在支持向量机出现后很快就失去了热度。大家卯着劲研究怎么面对训练样本不足的窘境,PCA和核方法大行其道,前者致力于减少数据维数,后者致力于从低维数据中学习高维结构。但是近几年随着卷积神经网络的流行,神经网络又焕发出了第二春,研究者发现只要样本量足够大(百万级甚至亿级样本量),网络参数足够多(百万级参数),加上巧妙的防过拟合技术,利用现代并行计算带来的强大计算能力,神经网络能够学得和人类的判别能力一样好。机器学习领域发展了几十年,似乎又回到了出发的地方。