sed是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
sed的选项、命令、替换标记
命令格式
sed [options] 'command' file(s) sed [options] -f scriptfile file(s)
常用选项:
-n∶使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN的资料一般都会被列出到萤幕上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e∶直接在指令列模式上进行 sed 的动作编辑;
-f∶直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename 内的sed 动作;
-r∶sed 的动作支援的是延伸型正规表示法的语法。(预设是基础正规表示法语法)
-i∶直接修改读取的档案内容,而不是由萤幕输出。
常用命令:
a ∶新增, a 的后面可以接字符串,而这些字符串会在目前的下一行出现。 c ∶取代, c 的后面可以接字符串,这些字符串可以取代 n1,n2 之间的行。 d ∶删除,后面不接任何东西; i ∶插入, 与a只有一点不同,增加的字符串会在目前的上一行出现; p ∶列印,亦即将某个选择的资料印出。在使用p的时候一般会加上-n参数。 s ∶取代,可以直接进行取代的工作。
基本用法
- d∶删除,后面不接任何东西;
删除某行 $ sed '1d' filename 删除第一行 $ sed '$ d' filename 删除最后一行 $ sed '1,2d' filename 删除第一行到第二行 $ sed '2,$ d' filename 删除第二行到最后一行
- p∶列印,亦即将某个选择的资料印出。在使用p的时候一般会加上-n参数。
显示某行 $ sed -n '1p' filename 显示第一行 $ sed -n '$ p' filename 显示最后一行 $ sed -n '1,2p' filename 显示第一行到第二行 $ sed -n '2,$ p' filename 显示第二行到最后一行 使用模式进行查询 $ sed -n '/world/p' filename 查询包括关键字world所在所有行 $ sed -n '/$ /p' filename 查询包括关键字$ 所在所有行,使用反斜线屏蔽特殊含义
- a∶新增, a 的后面可以接字符串,而这些字符串会在目前的下一行出现。
- i ∶插入, 与a只有一点不同,增加的字符串会在目前的上一行出现;
[root@localhost ~]# cat filename Hello! world! end [root@localhost ~]# sed '1a people' filename 第一行后增加字符串"people" Hello! people world! end [root@localhost ~]# sed '1,3a people' filename 第一行到第三行后增加字符串"people" Hello! people world! people end people [root@localhost ~]# sed '1i people person' filename 第一行前增加多行,使用换行符 people person Hello! world! end
- c∶取代, c 的后面可以接字符串,这些字符串可以取代 n1,n2 之间的行。
[root@localhost ~]# cat filename Hello! world! end [root@localhost ~]# sed '1c Hi' filename Hi world! end [root@localhost ~]# sed '1,2c Hi' filename Hi end
- s ∶取代,可以直接进行取代的工作。
格式:sed 's/要替换的字符串/新的字符串/g' 修改的文件 [root@localhost ~]# cat filename Hello! world! end [root@localhost ~]# sed -i 's/Hello!/start/g' filename 把Hello!替换为start [root@localhost ~]# cat filename start world! end [root@localhost ~]# cat filename start world! end [root@localhost ~]# sed -i '$a bye' filename 在最后一行后面新加bye($代表最后一样,a表示在当前行下一面添加,bye是新加内容,中间有没有空格都行) [root@localhost ~]# cat filename start world! end bye
awk
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
awk 是一种很棒的语言,它适合文本处理和报表生成,其语法较为常见,借鉴了某些语言的一些精华,如 C 语言等。在 linux 系统日常处理工作中,发挥很重要的作用,掌握了 awk将会使你的工作变的高大上。 awk 是三剑客的老大,利剑出鞘,必会不同凡响。
1、首先我们看一下常用的cut命令的基本使用方法,cut英文意思是切,它的功能和和awk基本相同,唯一不同的是awk可以说是cut的plus版本(但不是一个厂家)。
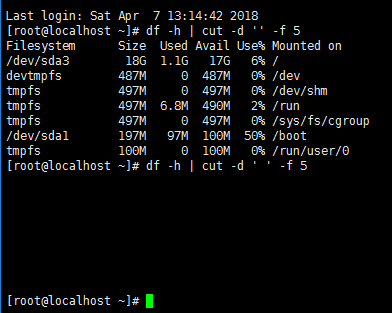
cut -d(指定以什么为分割符) -f(指定列) 第一列 #cut -d ‘ ’ -f 5
cut无法切割以空格为分割符的数据。
2、awk的基本常用写法
awk ‘条件一{动作一}条件二{动作二} ’ 文件
当然我们也可用使用管道符|awk。。。。。
3、awk的基本写法
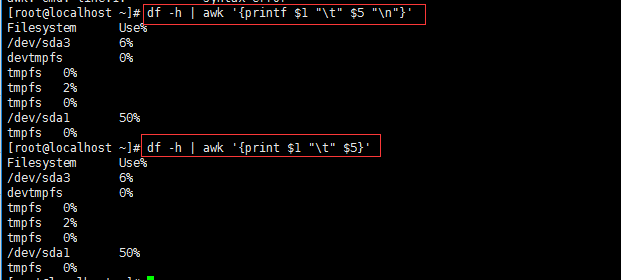
#我们使用printf的话最后必须要加上
换号符号,$数字是表示第几列
df -h | awk '{printf $1 " " $5 "
"}'
#如果使用print的话就不需要再多写一个
了
df -h | awk '{print $1 " " $5}'
#注意,为了不想让两行数据黏在一起,所以中间需要用“ ”空格符隔开。最外面的必须是单引号,而里面的 和
必须使用双引号。
4、实例
我们想试试判断linux的根分区的使用情况,或者是某个分区的使用情况,我们怎么判断呢。
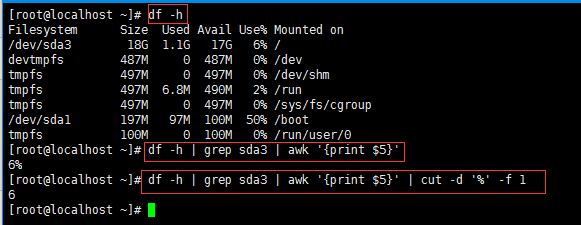
#df -h | grep sda3 | awk '{print $5}' | cut -d '%' -f 1
解释:
df -h | grep sda3是我的根分区,awk抓取第五列,也就是拿到6%这个数字,但是不想要百分号,那我们在用cut切一下,就OK了
5、BEGIN(实际上就是在打印结果的开始打印里面动作的一句话)
#df -h | grep sda3 | awk 'BEGIN{print "This is the use of the root partition"}{print $5}' | cut -d '%' -f 1

BEGIN的关键用法。
#awk '{FS=":"}{print $1 " " $3}' /etc/passwd
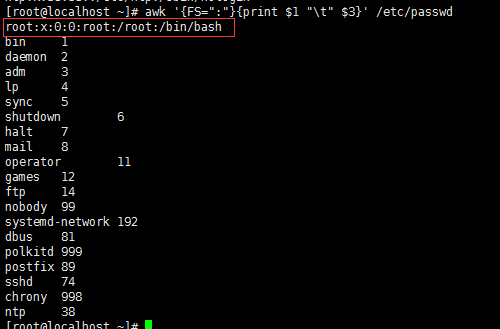
#awk 'BEGIN{FS=":"}{print $1 " " $3}' /etc/passwd
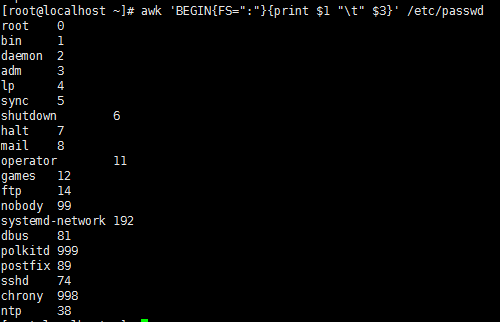
关键:我们知道awk是每次提取的时候都是先读取第一行后,才开始执行后面的动作语句,所以第一行没有被处理。这个时候就需要使用BEGIN,这个时候它就会处理所有数据。
END的用法
有BEGIN当然就有END了
#awk 'END{print"END!!!"}{print $1 " " $3}' /etc/passwd
#和BEGIN的用法基本相同,只不过是在处理数据动作的最后加打印而已。
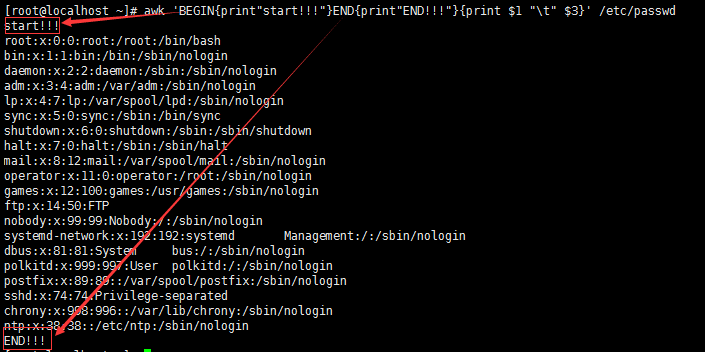
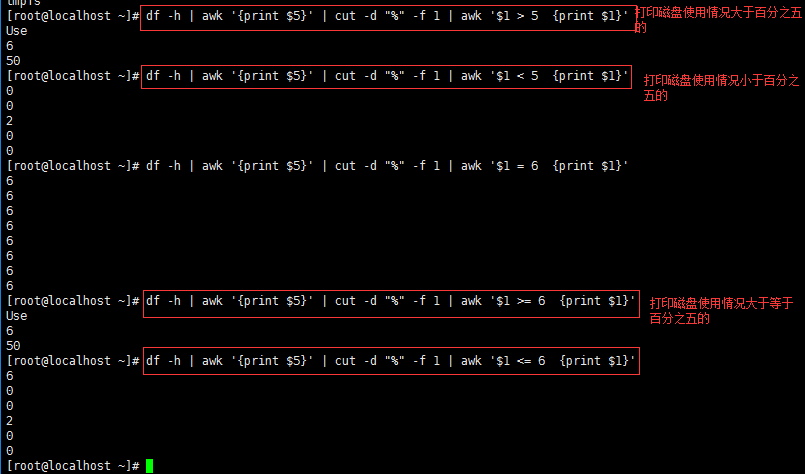
6、关系运算符
关系运算符 > 大于 < 小于 = 等于 #这里的等于就把结果都改成这等于后面的数值,如下图 >= 大于等于 <= 小于等于