robots是一种协议,主要是告诉搜索引擎什么东西可以抓,什么东西不让他抓。
而且robots.txt是蜘蛛访问的第一个文件,所以我们需要参与排名的页面都要写进去~~!
我们需要做的就是告诉搜索引擎抓高质量的,不抓低质量的,欺骗搜索引擎认为我们网站整体都是挺好的,从而获取最好的排名。
使用我们需要到网站根目录下创建一个 robots.txt 的文件,如下所示:

我们可以看一下淘宝的玩法:

由上图可以看出来,淘宝这么大的网站他都是有写robots.txt文件的,搜索引擎是按照上面的标识来进行抓取网站的数据的~~!
User-agent: Baiduspider
这里主要是告诉百度蜘蛛来抓取的
Disallow: /
禁止抓取
User-agent: *
Disallow: /
如果这样标注着,那么代表着所有的文件搜索引擎均不能抓取
User-agent: *
Disallow: /Admin
禁止搜索引擎爬行到Admin文件夹
User-agent: * Disallow:/Admin Allow:/Admin/images/123.png
Admin目录禁止爬虫抓取,但是又可以让搜索引擎抓取到 Admin 目录下的 images 目录下的 123.png
到了这里我们就开始编写自己的robots文件了,如下所示:
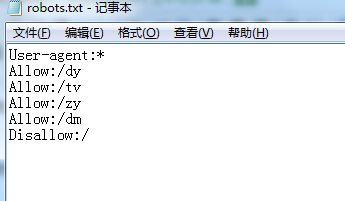
保存后放置到网站根目录,然后登陆站长平台:
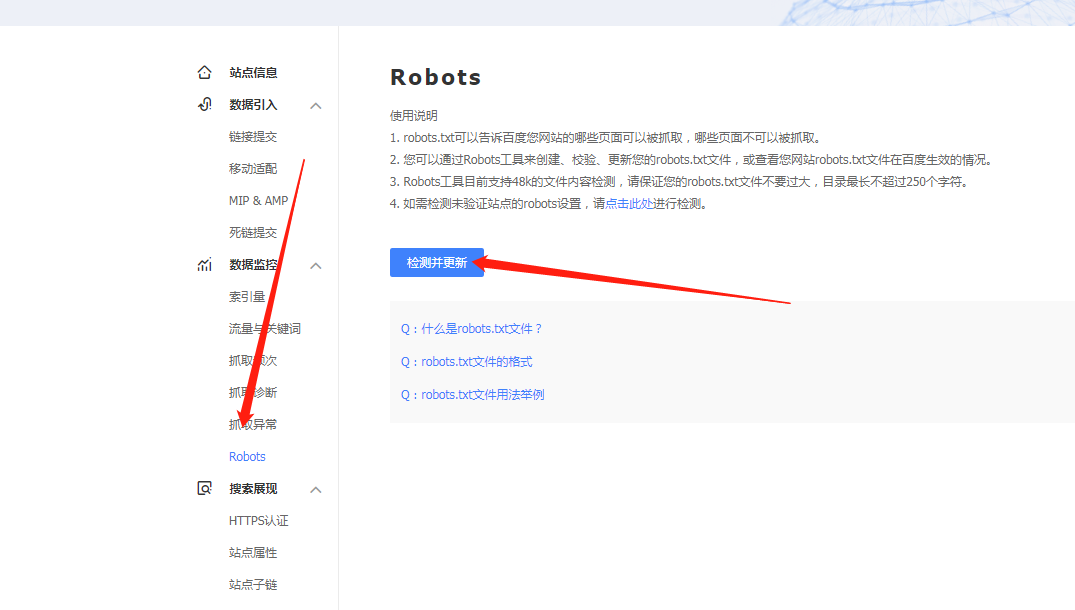
然后校验一下:
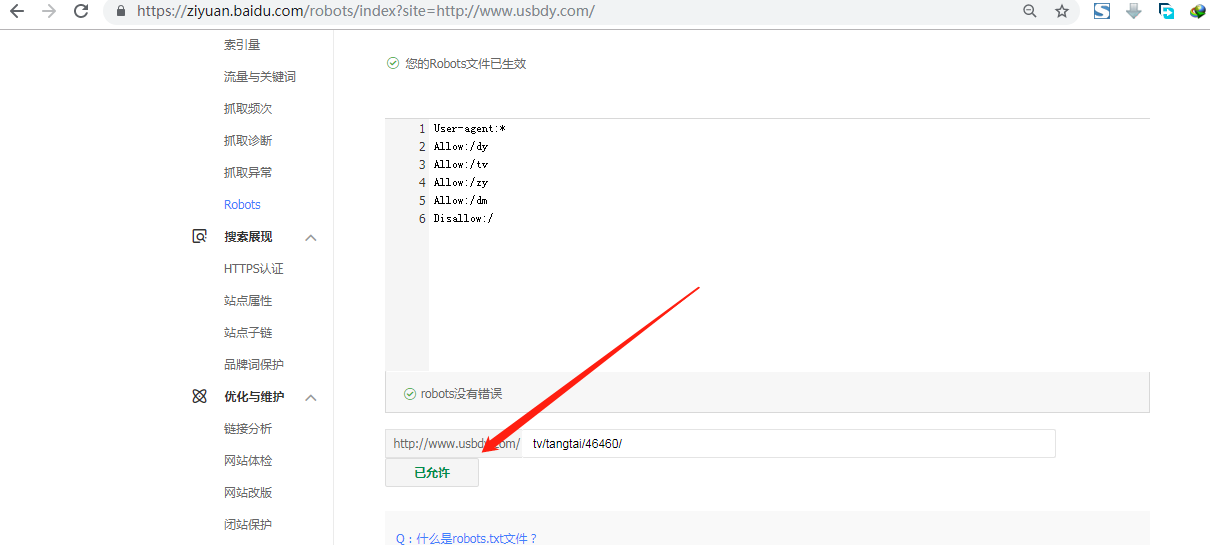
这样即可完成了robots全套操作咯~~!