结对作业第二次
一、结队成员
031502119 雷晶
031502617 张柽
二、代码仓库
结对编程——Git
三、生成数据
由于考虑到输入数据的量比较大,本次作业的学生以及部门数据我们讨论后采用按要求随机生成的方式生成。
这是我们的生成数据代码:
//部门随机数据生成
for (int i = 0; i < depart_num; i++)
{
//时间状态,使用过的置为1
int time_status[49] = { 0 };
//标签的状态,使用过的置为1
int tag_status[16] = { 0 };
//部门编号[1-depart_num]
depart[i].department_no = i + 1;
//需要学生个数上限[0-15]
depart[i].number_limit = rand() % 16;
//随机生成兴趣标签[2-4个]
for (int j = 0; j < rand() % 3 + 2; j++) {
while (1)
{
int index = rand() % 16;
if (tag_status[index] == 0)
{
depart[i].tags[depart[i].tag_num] = tag[index];
tag_status[index] = 1;
depart[i].tag_num++;
break;
}
}
}
//随机生成部门活动时间[3-7个]
for (int j = 0; j < rand() % 5 + 3; j++) {
while (1)
{
int index = rand() % 49;
if (time_status[index] == 0)
{
depart[i].event_schedules[depart[i].schedule_num] = free_time[index];
time_status[index] = 1;
depart[i].schedule_num++;
break;
}
}
}
}
//学生随机数据生成
for (int i = 0; i < stu_num; i++)
{
//时间状态,使用过时间段的置为1
int time_status[49] = { 0 };
//标签的状态,使用过的标签置为1
int tag_status[16] = { 0 };
//学生编号[1-stu_num]
stu[i].student_no = i + 1;
//兴趣标签随机生成2-4个
for (int j = 0; j < rand() % 3 + 2; j++) {
while (1)
{
int index = rand() % 16;
if (tag_status[index] == 0)
{
stu[i].tags[stu[i].tag_num] = tag[index];
tag_status[index] = 1;
stu[i].tag_num++;
break;
}
}
}
//空闲时间随机生成3-7个
for (int j = 0; j < rand() % 5 + 3; j++) {
while (1)
{
int index = rand() % 49;
if (time_status[index] == 0)
{
stu[i].available_schedules[stu[i].schedule_num] = free_time[index];
time_status[index] = 1;
stu[i].schedule_num++;
break;
}
}
}
//志愿随机生成[对应部门号depart_num]
for (int j = 0; j < 5; j++) {
stu[i].want[j] = rand() % depart_num + 1;
}
//绩点随机生成
stu[i].point = (rand() % 5000) / 1000.0;
这是我们的部分生成数据(Json格式):
//部门数据
"department" : [
{
"department_no" : 1,
"event_schedules" : [
"Fri.18:00-20:00",
"Wed.10:00-12:00",
"Wed.16:00-18:00",
"Thur.20:00-22:00",
"Thur.8:00-10:00",
"Sat.20:00-22:00",
"Wed.14:00-16:00"
],
"number_limit" : 3,
"tags" : [ "chess", "table tennis", "music" ]
},
{
"department_no" : 2,
"event_schedules" : [
"Mon.8:00-10:00",
"Thur.10:00-12:00",
"Fri.8:00-10:00",
"Sun.16:00-18:00",
"Sat.18:00-20:00",
"Sat.14:00-16:00"
],
"number_limit" : 15,
"tags" : [ "film", "running" ]
},
//学生数据
"student" : [
{
"free_time" : [ "Sat.10:00-12:00", "Fri.16:00-18:00", "Thur.10:00-12:00" ],
"student_no" : 1,
"tags" : [ "dance", "singing", "running" ],
"want" : [ 16, 20, 5, 18, 13 ]
},
{
"free_time" : [
"Thur.14:00-16:00",
"Thur.20:00-22:00",
"Sat.16:00-18:00",
"Sun.20:00-22:00",
"Wed.8:00-10:00"
],
在进行数据的随机生成中我们主要考虑了以下几点,同时在下述中给出了这样生成数据的合理性:
学生:
- 生成的空闲时间段以及兴趣标签不可以重复。
- 生成的学生兴趣标签的个数在2至4个中等概率随机分布。
- 生成的学生空闲时间的个数在3至7个中等概率随机分布。
- 学生的绩点也是在0至5分间随机生成的,虽然在现实中这样的绩点生成不符合实际,但是在比较中我们只比较学生绩点相对的高低,与绩点的数值大小差距及数值的分布无关,所以这样设计是合理的。
- 志愿一定要报满5个,但是允许重复。
部门:
- 随机生成[0,15个]部门
- 生成的空闲时间段以及兴趣标签不可以重复
- 生成的部门特点标签的个数在2至4个中等概率随机分布
- 生成的学生空闲时间的个数在3至7个中等概率随机分布
生成数据集的格式:
- 为了规范化也方便以后的数据处理以及读入,我们的生成数据集采用了json格式输出。
- 因为我们用的是C++来编写程序,所以我们采用JsonCPP来进行输出的操作
生成json格式数据代码
void print_generate_information(int depart_num, int stu_num)
{
Json::Value root;
Json::Value Stu;
Json::Value Dep;
for (int i = 0; i < depart_num; i++)
{
//定义department及各属性
Json::Value department;
Json::Value event_schedules;
Json::Value tags;
//给各属性赋值
for (int j = 0; j < depart[i].schedule_num; j++)
{
event_schedules[j] = Json::Value(depart[i].event_schedules[j]);
}
for (int j = 0; j < depart[i].tag_num; j++)
{
tags[j] = Json::Value(depart[i].tags[j]);
}
department["department_no"] = Json::Value(depart[i].department_no);
department["number_limit"] = Json::Value(depart[i].number_limit);
department["event_schedules"] = Json::Value(event_schedules);
department["tags"] = Json::Value(tags);
Dep[i] = Json::Value(department);
}
for (int i = 0; i < stu_num; i++)
{
//定义student及各属性
Json::Value student;
Json::Value want;
Json::Value free_time;
Json::Value tags;
//给student属性赋值
for (int j = 0; j < 5; j++)
{
want[j] = Json::Value(stu[i].want[j]);
}
for (int j = 0; j < stu[i].schedule_num; j++)
{
free_time[j] = Json::Value(stu[i].available_schedules[j]);
}
for (int j = 0; j < stu[i].tag_num; j++)
{
tags[j] = Json::Value(stu[i].tags[j]);
}
student["student_no"] = Json::Value(stu[i].student_no);
student["want"] = Json::Value(want);
student["free_time"] = Json::Value(free_time);
student["tags"] = Json::Value(tags);
Stu[i] = Json::Value(student);
}
root["student"] = Json::Value(Stu);
root["department"] = Json::Value(Dep);
//缩进输出
Json::StyledWriter sw;
cout << sw.write(root);
}
- 附上Jsoncpp学习链接: vs上配置jsoncpp,json的基本语法
读取生成的json数据:
- 由于要实现题目要求的
为输入输出设计标准化、通用化、可扩展的接口,也为了方便后面的评估测试,我们将生成的json数据读入我们的匹配程序,再进行数据处理、匹配和输出结果。
读取json格式数据代码
int read_information()
{
Json::Reader reader;
Json::Value root;
//从文件中读取
ifstream is;
is.open("./import.txt", ios::binary);
if (reader.parse(is, root))
{
for (int i = 0; i < root["department"].size(); i++)
{
//读取部门编号
int department_no = root["department"][i]["department_no"].asInt();
depart[department_no - 1].department_no = department_no;
//读取部门人数上限
depart[department_no - 1].number_limit = root["department"][i]["number_limit"].asInt();
//读取部门活动时间
for (int j = 0; j < root["department"][i]["event_schedules"].size(); j++)
{
depart[department_no - 1].event_schedules[j] = root["department"][i]["event_schedules"][j].asString();
depart[department_no - 1].schedule_num++;
}
//读取部门标签
for (int j = 0; j < root["department"][i]["tags"].size(); j++)
{
depart[department_no - 1].tags[j] = root["department"][i]["tags"][j].asString();
depart[department_no - 1].tag_num++;
}
}
for (int i = 0; i < root["student"].size(); i++)
{
//读取学生编号
int student_no = root["student"][i]["student_no"].asInt();
stu[student_no - 1].student_no = student_no;
//读取学生志愿
for (int j = 0; j < 5; j++)
{
stu[student_no - 1].want[j] = root["student"][i]["want"][j].asInt();
}
//读取学生空闲时间
for (int j = 0; j < root["student"][i]["free_time"].size(); j++)
{
stu[student_no - 1].available_schedules[j] = root["student"][i]["free_time"][j].asString();
stu[student_no - 1].schedule_num++;
}
//读取学生兴趣标签
for (int j = 0; j < root["student"][i]["tags"].size(); j++)
{
stu[student_no - 1].tags[j] = root["student"][i]["tags"][j].asString();
stu[student_no - 1].tag_num++;
}
}
}
is.close();
department_num = root["department"].size();
return root["student"].size();//返回学生数量
}
四、智能匹配算法
分析问题的心路历程
-
一开始我们看到这个题目时,发现这是一个多对多的算法,也就是一个部门可以选择多个学生,同时一个学生也可以进入多个部门。然后我们进行学生和部门的匹配时要根据学生的优先级来进行筛选,但是具体这个优先级要怎么设定呢?一开始我们是决定首先考虑时间匹配度最高的,在时间匹配相同的情况下考虑兴趣比配度高的,若时间比配度和兴趣匹配度均相同我们就考虑绩点。(由于学生的绩点是从0—5中随机生成的数,且精确到小数点后3位,所以出现绩点依旧相同的概率非常的小。)
-
有了初步的思路我们就开始写代码了。但是在写匹配算法的过程中我们发现,这样的逐级筛选在算法实现上比较困难,而且每次对进入部门的同学进行排序时都要比较他们的时间匹配度,兴趣匹配度,甚至经常也要对他们的绩点进行比较。导致了算法想的效率很低。
-
【最终版评价标准】于是我们又想了一个在算法实现上相对容易,优先级排序标准比较合理,算法的效率也相对高的方法:给每个学生一个评价分数,评价分数按照时间匹配度分数、兴趣匹配度分数和绩点分数按比例加在一起得到。也就是
-
总的评价分数=对该部门的时间匹配度分数*0.5+对该部门的兴趣匹配度分数*0.3+绩点分数*0.2 -
这样一来由于绩点的不同,学生总评价分数相同的概率非常小,评价分数的计算方式也相对合理。于是我们最终使用的这种方式来生成评价分数,作为学生间比较的评价标准。当然同一个学生对应不同部门时的评价分数也是不同的。
最终使用的算法
- 我们在进行学生与部门匹配时使用的算法是
“婚姻算法”的一个变形,称为“盖尔-沙普利算法”,也被称为“延迟接受算法”,简称“GS算法”。在百度学习过各种资料后我们大致理解了这个算法 - 但是这个
“GS算法”是进行1对1匹配的,而我们的要求是:一个学生有5个志愿(可重复),可以进入多个部门,而一个部门也可以收[0,15]个的学生。所以我们在原有的“GS算法”算法上进行了改动让它可以适应我们题目的要求,进行多对多的匹配。 - 在进行部门和学生匹配时最好的配对方案当然是,每个学生最终去的部门正好都是自己的“第一选择”。这虽然很完美,但绝大多数情况下都不可能实现。
- 在我们设计的算法中学生们将一轮一轮地去争取他们想进的部门,在部门人数没有满的情况下部门将接受他们。但如果此时部门中的人数已经满了,则我们要将这位学生和部门中评价分数最低的学生进行对比,若他比其中最低的学生还要低,则他就无法进入部门,若他比最低的学生要来得高,则他进入部门而那位学生离开部门。
- 这样扫过一遍第一轮志愿后,我们再扫第二志愿、第三志愿......以此类推知道5个志愿全部扫完。这时在部门内的学生就是部门最终选择的学生,而其余未进入部门的学生就是被淘汰的学生。(由于20个部门,每个部门要0到15和学生,而我们一共有300个学生,进行初步计算后我们就会发现,一定有学生无法进入部门,同时若有一定量的学生报某个部门,那个这个部门就不会收不到学生。)
展示部分代码
- 生成评价分数:
void compute(int stu_num)
{
for (int i = 0; i < stu_num; i++)
{
for (int j = 0; j < 5; j++)
{
Student& student = stu[i];
Departments& department = depart[stu[i].want[j] - 1];
//计算活动时间重合次数
for (int m = 0; m < student.schedule_num; m++)
{
for (int n = 0; n < department.schedule_num; n++)
{
if (department.event_schedules[n] == student.available_schedules[m])
{
student.match_schedule[j]++;
}
}
}
//计算兴趣标签重合次数
for (int m = 0; m < student.tag_num; m++)
{
for (int n = 0; n < department.tag_num; n++)
{
if (department.tags[n] == student.tags[m])
{
student.match_tag[j]++;
}
}
}
//加权 活动时间占50%,兴趣占%30,绩点占20%
student.match_best[j] = student.match_schedule[j] * 0.5 + student.match_tag[j] * 0.3 + student.point * 0.2;
}
}
}
- 学生与部门匹配
//使用Gale-Shapley算法进行匹配
void match(int stu_num)
{
//未分配到部门的学生队列
queue<Student> que;
for (int i = 0; i < stu_num; i++)
{
que.push(stu[i]);//初始都是未分配状态,都加进队列
}
while (!que.empty())
{
Student& cur_student = stu[que.front().student_no - 1];
que.pop();
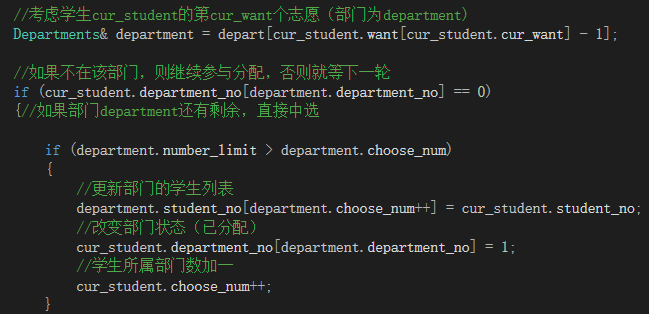
//考虑学生cur_student的第cur_want个志愿(部门为department)
Departments& department = depart[cur_student.want[cur_student.cur_want] - 1];
//如果不在该部门,则继续参与分配,否则就等下一轮
if (cur_student.department_no[department.department_no] == 0)
{//如果部门department还有剩余,直接中选
if (department.number_limit > department.choose_num)
{
//更新部门的学生列表
department.student_no[department.choose_num++] = cur_student.student_no;
//改变部门状态(已分配)
cur_student.department_no[department.department_no] = 1;
//学生所属部门数加一
cur_student.choose_num++;
}
else
{//名额已满则开始竞争,与权重值最小的学生进行比较
int min_stu_no = -1; //学生中权重值最小的学生编号
int position; //权重值最小的学生在部门中选列表中的下标
double min_best = 100; //临时最小权重值
//在部门学生列表中查找权重值最低的学生编号
for (int i = 0; i < department.choose_num; i++)
{
Student tmp = stu[department.student_no[i] - 1];
if (min_best > tmp.match_best[cur_student.cur_want])
{
min_best = tmp.match_best[cur_student.cur_want];//更新最小值
min_stu_no = tmp.student_no; //权重值最小的学生编号
position = i; //权重值最小的学生所在部门列表的下标
}
}
//如果部门department不纳新
//或者 学生cur_student的权重值比部门department中所有已经中选的学生还低,那么学生cur_student只好等下轮
if (department.number_limit != 0 && cur_student.match_best[cur_student.cur_want] > min_best)
{//否则学生cur_student就直接替换掉权重值最低的那个学生
//更新被淘汰学生的信息
Student& min_stu = stu[min_stu_no - 1];
min_stu.department_no[department.department_no] = 0;//被淘汰后,将该部门对应的数组下标置0(未分配)
min_stu.choose_num--; //被淘汰学生所选部门数减一
//更新新加入的学生信息
department.student_no[position] = cur_student.student_no;
cur_student.department_no[department.department_no] = 1;
cur_student.choose_num ++ ;
}
}
}
//下一个志愿
cur_student.cur_want++;
//如果五个志愿还没有考虑完,则放入队列继续参与分配
if (cur_student.cur_want < 5)
{
que.push(cur_student);
}
}
}
五、结果分析
算法测试报告:
| 优先条件 | 部门收学生数 | 匹配学生个数 | 未匹配学生个数 | 实际耗时(s) | 输出文件路径 |
|---|---|---|---|---|---|
| 活动时间优先 | 115 | 92 | 208 | 2.59s | https://github.com/leijing000/SoftwareEngineering/blob/master/output_test/output_condition_time.txt |
| 兴趣爱好优先 | 115 | 98 | 202 | 2.705s | https://github.com/leijing000/SoftwareEngineering/blob/master/output_test/output_condition_intrest.txt |
| 绩点优先 | 115 | 92 | 208 | 2.734s | https://github.com/leijing000/SoftwareEngineering/blob/master/output_test/output_condition_point.txt |
从测试结果我们发现,对于相同的输入数据集,改变评价分数的生成方式,对结果没有产生较大的影响。经过分析我们认为,我们的数据是随机生成的,而且三个指标的范围相差不大,所以造成了哪种方式优先对结果的影响比较微弱。
六、代码规范
-
我们的代码使用了自描述的变量名和方法名,让命名变得有意义。主要通过下划线和英文字母命名,让名字尽量能够一看就知道是什么意思;
-
添加注释,尤其像这么长的代码,注释非常重要。
-
将功能块封装成函数

七、结对感受与总结
“张柽”
这两次的结对中,和雷晶的合作特别的愉快,一般我们都会先开个小会讨论一下分工,然后各自回去干活。遇到了问题再一起约出来,一起讨论怎么解决,一起优化算法,一起改bug,一起讨论博客的思路。经过这两次的结对作业,我也进步的许多,相信队友也是一样。我学会了用原型软件工具画出好看的界面,学会去解决那些完全陌生的问难,还收获了我们两之间的友谊,这些都会成为我们宝贵的财富。
闪光点:
- 我的队友特别的漂亮、聪明、温柔善解人意。看到她就有了很强的动力,去完成作业中的每一个要求。
- 我的队友写代码的能力和学习能力都很强,这点是值得我努力学习的。向她学习这种上进的不服输的精神。
建议
- 我觉得我的队友特别的完美。
- 如果要在鸡蛋里挑骨头的话,那就以后咱们写代码的时候都记得随时把注释写上吧,不然后面改算法再去看和找代码真的有点辛苦,写到最后都是几百行的代码,找不到自己要改的代码的位置挺头疼的。
“雷晶”
刚看到题目的时候,我都不知道题目在讲什么,一脸懵逼。后来在和队友张柽的讨论下渐渐有了大概的流程,我们按流程一步一步地完成这次作业。从随机生成数据到数据的输出,从数据的读入再到算法的实现。虽然这次作业很难,我们还是在规定时间内完成了,我觉得张柽给我的帮助很大,我们一起研究算法,讨论算法会遇到的各种问题,不断优化我们的算法,效率比一个人自己完成要高出好多好多。而且,两个人在一起就不容易懈怠,有队友一起并肩作战的感觉很赞。不过这次作业正好是在国庆期间,我和队友都回家了,前期只能通过手机进行交流,无法进行面对面的沟通,这是比较遗憾的吧。所以,前期我们主要是进行资料的查找和新知识的学习,并将随机生成的代码写好了,至于算法,是我们到了学校之后一起写的,两个人一起写代码可以避免不少错误的发生,提高效率并增加乐趣。
闪光点:
- 我的队友非常可爱活泼,相处下来非常愉快。
- 队友也非常地有想法,很多我没想到的她都想到了,给了我很好的启发与帮助。