关于删除表中多余的重复记录,网上大多数都是用这种方法来处理的
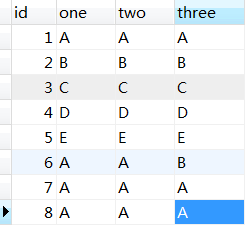
如图是测试表的数据,要去掉one,two,three三列都重复的记录,只保留一条,也就是说要将最后两条记录删除掉
网上常用的SQL语句:
1 DELETE 2 FROM 3 testdelete 4 WHERE 5 (one, two, three) IN (SELECT one, two, three FROM testdelete GROUP BY one, two, three HAVING COUNT(*) > 1) 6 AND id NOT IN (SELECT MIN(id) FROM testdelete GROUP BY one, two, three HAVING COUNT(*) > 1)
这个语句在Oracle 和SQL Server中能运行,但是MySQL执行的时候不能成功,会提示如下错误

这句话的意思是不能对进行查询操作的表进行update操作,也就说我们的where条件中进行了子查询,
并且子查询也是针对需要进行update操作的表的,mysql不支持这种查询修改的方式。
所以,我们只要查询和修改的不是同一个表就行了或者两者有先后顺序,当查询完成后在对其进行删除操作,这样就可以
避免错误的发生。
第一种方式我采用了内嵌视图的方法来完成删除重复记录的操作
使用视图来将查询和修改分开,使其不再同时操作一张表,参见如下SQL语句
1 DELETE 2 FROM 3 testdelete 4 WHERE 5 id IN ( 6 SELECT 7 id 8 FROM 9 ( 10 SELECT 11 id 12 FROM 13 testdelete 14 WHERE 15 (one, two, three) IN (SELECT one, two, three FROM testdelete GROUP BY one, two, three HAVING count(*) > 1) 16 AND id NOT IN (SELECT min(id) FROM testdelete GROUP BY one, two, three HAVING count(*) > 1) 17 ) AS deleteview 18 )
第二种方式我写了个存储过程来完成删除重复记录的操作
先将重复记录数查询出来,然后用一个循环语句删除重复记录来达到去重的效果
DELIMITER $ CREATE DEFINER=`root`@`localhost` PROCEDURE `function_delete`() BEGIN DECLARE count INT; DECLARE deleteid INT; DECLARE i INT; SET i = 0; SELECT COUNT(*)INTO count from testdelete where (one,two,three) IN (SELECT one,two,three FROM testdelete GROUP BY one,two,three HAVING COUNT(*)>1) AND id NOT IN (SELECT MIN(id) FROM testdelete GROUP BY one,two,three HAVING COUNT(*)>1); WHILE i < count do SELECT id INTO deleteid from testdelete where (one,two,three) IN (SELECT one,two,three FROM testdelete GROUP BY one,two,three HAVING COUNT(*)>1) AND id NOT IN (SELECT MIN(id) FROM testdelete GROUP BY one,two,three HAVING COUNT(*)>1) LIMIT 1; DELETE FROM testdelete where id = deleteid; set i = i+1; end while; END$ DELIMITER ;