3.7Tensor底层原理
真正管理存储这数据的内存区域的,是类Storage的实例,这个Storage的实例通过一个一维数组来存储数据。不管外在表现为多少维的数组,都是存储在一个一维数组中。而怎么让这个一维数组看起来像多维数组,就是Tensor完成的。
Storage类中有一个指针指向存储数据的一位数组,而Tensor通过对Storage进行封装,使得在外部看来数据是多维的。

那么如何得到tensor中的某个值在Storage的索引位置呢?
[offset_{i,j} = stride[0]*i + stride[1]*j + storage\_offset quad (1)
]
其中,(i,j)为该值在tensor中的索引,以二维tensor为例。
storage_offset 一个指向该Tensor元素开始的Storage索引,因为可能有些Tensor只使用了Storage的一部分,它控制着每个Tensor的起始位置,一般为0。
stride 一个元组,表示获取一个Storage中的一个元素需要在每个维度上跳过多少个元素。
比如下图:
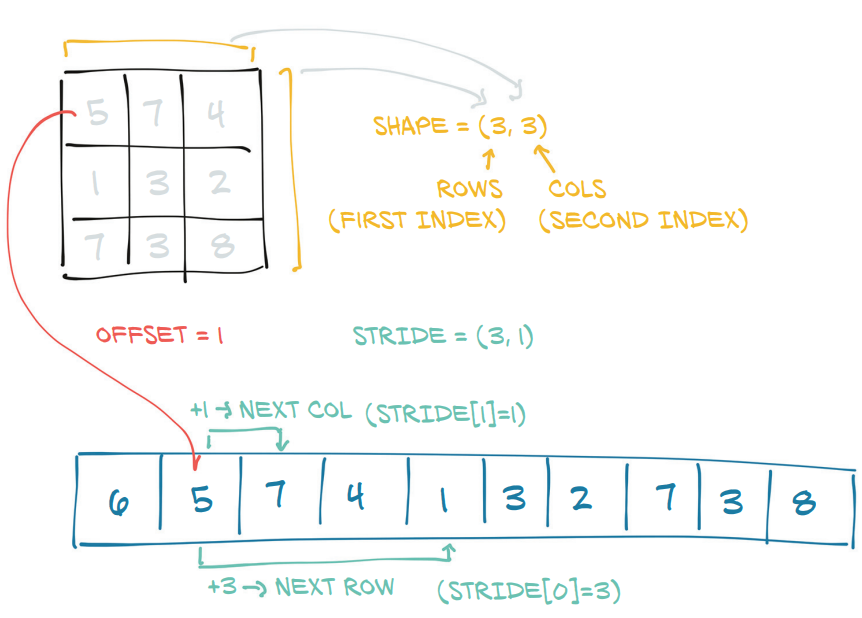
其 stride=(3.1),storage_offset=0,根据方程(1),tensor中第2行第2列的值3在Storage中的索引: (3*1+1*1 + 0=4)
a = torch.tensor([[5, 7, 4], [1, 3, 2], [7, 3, 8]])
print(a)
print(a.storage())
print("size is {}".format(a.size()))
print("stride is {}".format(a.stride()))
print("storage offset is {}".format(a.storage_offset()))