- map:对RDD中每个元素都执行一个指定函数从而形成一个新的RDD
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("MyApp")
sc = SparkContext(conf = conf)
def func(x):
return x*2
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
mapRdd2 = rdd.map(func)
print(mapRdd2.collect())# [2, 4, 6, 8, 10]
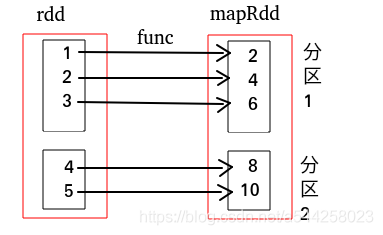
map依赖图关系如下,红框代表整个数据集,黑框代表一个RDD分区,里面是每个分区的数据集
- flatMap:与map类似,但是每一个输入元素会被映射成0个或多个元素,最后达到扁平化效果
data = [[1,2],[3],[4],[5]]
rdd = sc.parallelize(data)
print(rdd.collect()) # [[1, 2], [3], [4], [5]]
flatMapRdd = rdd.flatMap(lambda x: x)
print(flatMapRdd.collect())# [1, 2, 3, 4, 5]
flatMap依赖关系图如下

map和flatMap对比
rdd = sc.parallelize([("A",1),("B",2),("C",3)])
flatMaprdd = rdd.flatMap(lambda x:x)
print(flatMaprdd.collect()) # ['A', 1, 'B', 2, 'C', 3]
maprdd = rdd.map(lambda x:x)
print(maprdd.collect()) # [('A', 1), ('B', 2), ('C', 3)]
- mapPartitions:是map的一个变种,map对每个元素执行指定函数,mapPartitions对每个分区数据执行指定函数
rdd = sc.parallelize([1, 2, 3, 4],2)
def f(iterator):
yield sum(iterator)
print(rdd.mapPartitions(f).collect()) # [3, 7] 两个分区,第一个分区为 [1,2],第二个分区为[3,4]