单独记录装饰器这个知识点是因为这个知识点是非常重要的,必须掌握的(代码大约150行)。
了解装饰器之前要知道三个知识点
- 作用域,上一篇讲到过顺序是L->E->G->B
- 高阶函数:
-
满足下列其中一种即可称之为高阶函数:
a、把一个函数名当做实参传递给另一个函数
b、返回值中包含函数名
3.闭包
闭包是由函数及其相关的引用环境组合而成的实体(即:闭包=函数+引用环境),通俗讲法是:在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。,具体看下面代码:
n = 10 # 定义全局作用域变量 def fn(): # 形成闭包 n = 100 # 定义局部变量n def inner(): nonlocal n n += 1 # 这里定义操作相同变量n无法调用上层作用中的变量,如果只读不写则可以正常访问 # python3 中新增nonlocal 关键字可以调用上层作用域中的变量 print(n) return inner # 返回内嵌函数的地址,从而形成闭包 # 形成闭包的条件 # 1、必须要有一个内嵌函数 # 2、内嵌函数中要对自由变量的引用 # 3、外部函数必须返回内嵌函数 t = fn() t() ->101 print(n) ->10
这里要插播一下,刚刚看到群里面有一道题目,需求如下:
需要将str1 = (('a'),('b')),(('c'),('d')) 变成 [{'a': 'c'}, {'b': 'd'}]
可以先尝试下:
给个提示,用到zip和map,上一篇已经说过map了,这次来补充一下zip是个啥,举个例子给你看下:
#zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表 s1 = (('a'),('b')) s2 = (('c'),('d')) s3 = zip(s1, s2) print(list(s3)) ->结果是:[('a', 'c'), ('b', 'd')]
所以应该知道怎么玩了吧,接下来就是答案了:
str1 = (('a'),('b')),(('c'),('d')) z = zip(str1[0], str1[1]) #返回的是一个迭代器 b = list(map(lambda x: {x[0]: x[1]} , z)) #map这里做的就是将zip类的两个元祖拿出来然后进行元祖变成字典的转换(这个转换不错值得学习),返回的也是一个迭代器,所以用list返回成列表 print(b)
好了,言归正传哈,了解了上面的三个知识点后,接着就来说说装饰器,装饰器的作用主要是啥呢?装饰器就是对已经存在的对象添加新的功能
现在我们一步一步来,原先我们已经有了一些功能了,假设像下面的
#业务中的某一个功能 def f1(): print('f1...')
此时我们有一个需求,就是需要计算这个函数执行花费的时间,那怎么玩呢?直接修改函数吗?那如果成千上百的函数都需要呢?所以不能直接修改,这样我们就重新定义一个函数
import time def count_time(f): start_time = time.time() f() time.sleep(0.1) #由于执行时间太短,所以加了0.1秒 end_time = time.time() print(end_time-start_time) def f1(): print('f1...') count_time(f1)
似乎已经达到了效果,但是又有一个问题来了,你想想原本大家都是通过f1去调用的,现在是不是都得改成count_time了,别人是不是得砍死你呢?
是不是我们得想办法既加上功能又还是以前的名称调用呢?这个就是装饰器的由来
import time
def count_time(f): def inner(): start_time = time.time() f() time.sleep(0.1) end_time = time.time() print(end_time-start_time) return inner def f1(): print('f1...') f1 = count_time(f1) # 右边就是返回执行时间统计和业务程序的内存对象地址,又将这个对象地址赋值给f1,这样调用f1就是原来功能加上新功能了
f1()
函数count_time就是装饰器,它把真正的业务方法包裹在函数里面,看起来像f1被上下时间函数装饰了,但是每次写f1 = count_time(f1)还是很麻烦的,因此装饰器有相应的语法就是@count_time
@符号是装饰器的语法糖,在定义函数的时候使用,避免再一次赋值操作,像下面一样
import time def count_time(f): def inner(): start_time = time.time() f() time.sleep(0.1) end_time = time.time() print(end_time-start_time) return inner @count_time #就等同于f1 = count_time(f1),也就是将inner的引用对象引给了f1 def f1(): print('f1...') f1()
接着又有新的问题了,啥问题呢?像f1这种都是无参数的函数,那么如果有多个参数咋办呢?此时我们就需要加上不定长参数
import time def count_time(f): def inner(*args, **kwargs): start_time = time.time() result = f(*args, **kwargs) time.sleep(0.1) end_time = time.time() print(end_time-start_time) return result return inner @count_time #就等同于f1 = count_time(f1) def f1(*args, **kwargs): sum_num = 0 for i in args: sum_num += i return sum_num sum_num = f1(1,2,3) print(sum_num)
呼,似乎终于写完了,但是呢产品又跑过来,说现在有些函数又要额外加些新功能,比如这些需要加一个日志打印功能,另外的函数又不用,那我们怎么办呢?
我们的思路肯定是将功能添加到count_time函数内但是呢我们需要再传入一个参数作为打印日志功能的开关,此时我们就会想到是不是装饰器可以传入参数呢?
我们发现f1 = count_time(f1),这里并没有传入参数的入口,那咋么办呢?
import time def logger(flag=0): def count_time(f): def inner(*args, **kwargs): start_time = time.time() result = f(*args, **kwargs) time.sleep(0.1) end_time = time.time() print(end_time-start_time) if flag: print("打印日志") return result return inner return count_time @logger(1) # 因为logger(1)实际上是做了执行操作,所以执行的结果就是将count_time装饰器返回,然后还保留了flag参数,接着就是@count_time了也就是f1=count_time(f1) def f1(*args, **kwargs): sum_num = 0 for i in args: sum_num += i return sum_num sum_num = f1(1,2,3) print(sum_num)
上面的logger是允许带参数的装饰器。它实际上是对原有装饰器的一个函数封装,并返回一个装饰器(一个含有参数的闭包函数)。
如果没有如果没有使用@语法,等同于 # f1 = logger(1)(f1),这下应该明白了吧
学完了这些之后呢,就来做一个作业,就是用装饰器做一个简单的登录判断
qq文本中存了这些账户信息(一般之后都是存到数据库的)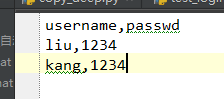
# -*- coding:utf-8 -*- # @__author__ : Loris # @Time : 2018/11/6 10:31 """ 需求:用装饰器的知识做一个登录功能 要求: 1、给用户展现三个菜单,home、book、clothes 2、用户点击了其中菜单后,判断用户是否已经登录,如果登录了就直接进入到菜单内,如果没登录就让用户选择时用微信还是qq登录 3、qq和微信的账号和密码存在文本中,校验通过后才可以进入,不通过则提示用户输入有误! """ # 读取账户信息 def read_file(file_name): user_msg = [] # 存储信息 with open(file_name, encoding="utf-8") as f_msg: f_msg.readline() # 第一行去掉 for i in f_msg: user_msg.append(i.strip().split(",")) # 通过,分割,将用户名和密码变成一个列表 user_msg = dict(user_msg) # 将读取出来的信息变成字典 return user_msg #判断三次密码错误就退出 def is_login(f, user_msg): global login_status global first_flag count = 3 # 总共三次 while count > 0: username = input("username:") passwd = input("password:") if username in user_msg: pswd = user_msg[username] if passwd == pswd: print("你已经成功登录") login_status = True f() break else: print("账户名和密码错误") count -= 1 else: print("账户名和密码错误") count -= 1 if count == 0: first_flag = 0 # 定义登录装饰器 def login_style(style="qq"): def login(f): def inner(): if not login_status: if style == "qq": # 从文件中读取用户信息 user_msg = read_file("qq") is_login(f, user_msg) elif style == "weixin": user_msg = {"liu":"123", "long":"haha"} is_login(f, user_msg) else: f() return inner return login #定义三个菜单栏内的功能 @login_style("weixin") def home(): print("我是首页") @login_style() def book(): print("书本页面") @login_style() def clothes(): print("衣服页面") # 定义一个全局参数作为是否已经登录的标识位,默认为没登陆 login_status = False #用户的三个菜单栏 menu_list = ["home", "book", "clothes"] first_flag = 1 #定义主函数 def main(): while first_flag: #首先是循环打印菜单栏 print("菜单栏如下:") for menu in menu_list: print(menu) # 用户选择 choice_menu = input("please choice:") # 判断用户选择是否正确 if choice_menu == menu_list[0]: eval(menu_list[0])() elif choice_menu == menu_list[1]: eval(menu_list[1])() elif choice_menu == menu_list[2]: eval(menu_list[2])() else: print("请重新输入") if __name__ == "__main__": main()