创建项目并绘制界面
打开Visual Studio并创建一个基于.net 4.5的WPF项目:GetTaoBaoItems
之所以采用4.5是因为后面我们将要用到里面免费的新的异步编程特性.
绘制如下主界面:

下载网页
我们知道要进行网络数据采集必不可少就要下载网页内容,因此我们首先需要构建一个下载网页内容的函数:
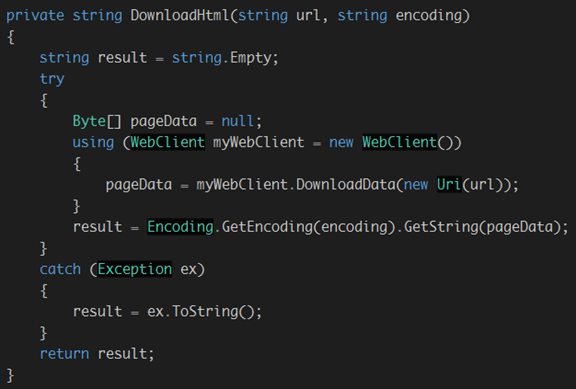
注意using System.Net
我们下载哪个网页了?
我们可以通过类似网址查看一个店铺的所有宝贝: [淘宝店铺地址]/search.htm,如下图所示:
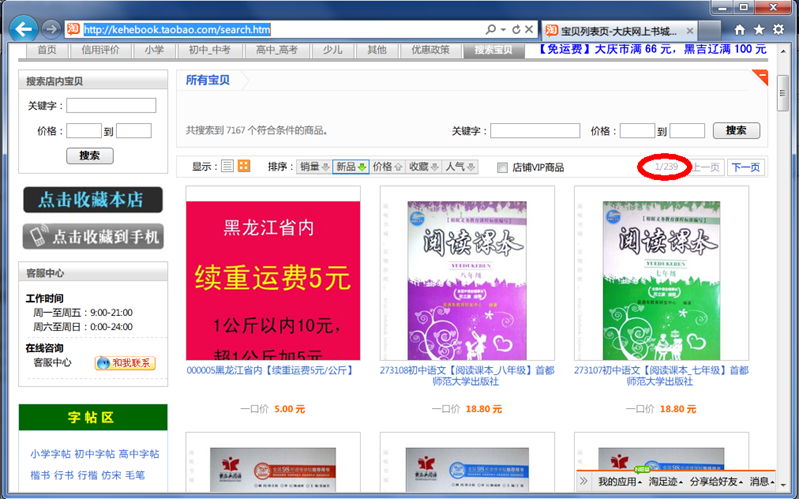
如上图红圈所示,宝贝是分页显示的那么第二页的地址在哪里了?我们选择第二页:

我们可以得知第k页的网址是:
[淘宝店铺地址]/search.htm?search=y&viewType=grid&orderType=_newOn&pageNum=k#anchor
因此我们就可以得知我们要下载的内容应该是这样的:
先下载第一页的内容并获取红圈所示的总页数,然后下载第二页到最后一页.
下载第一页并获取总页数
为获取按钮添加点击按钮事件并在里面添加下载第一页的内容:

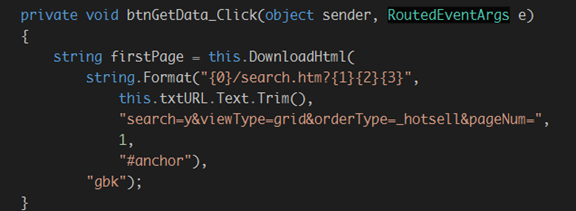
下面我们将要讲解我们怎么来获取页面总页数这个数据.
我们这里开始将要用到正则表达式,大家最好先到如下网页进行一定基础的了解:
http://www.yesky.com/imagesnew/software/vbscript/html/jsgrpRegExpSyntax.htm
先添加如下引用:

然后在获取按钮点击事件里添加如下代码:
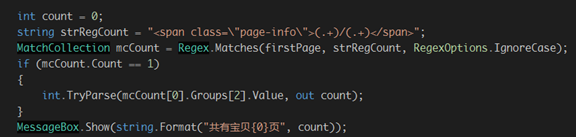
运行程序并点击获取按钮:
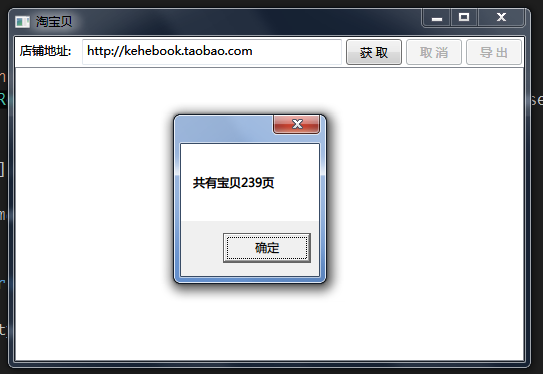
现在将这段代码重构为函数GetPageCount:

获取宝贝信息
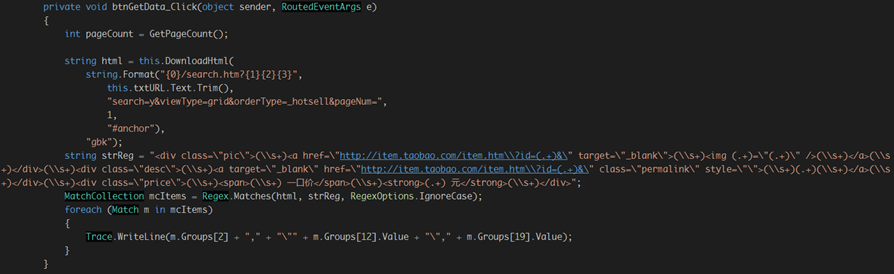
我们当把某一页网页下载回来之后要做的就是对该网页进行分析,如下代码所示:
运行一下:
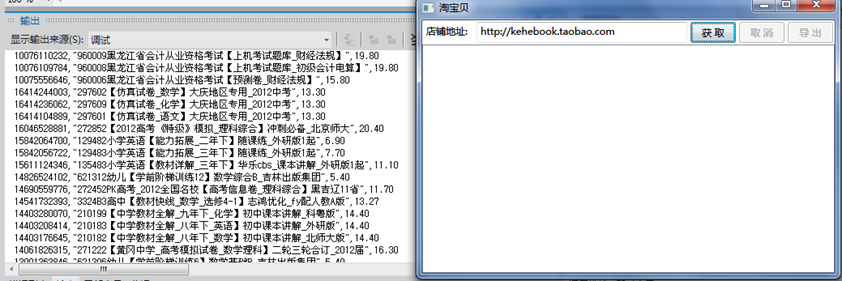
那么下面我们将上面的代码重构为函数AnalyPages:

运行代码:

将数据显示到界面上
我们先添加如下内容来存储数据:

将其绑定到listbox:
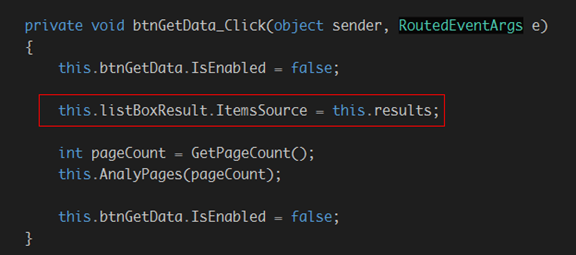
修改之前的函数AnalyPages:
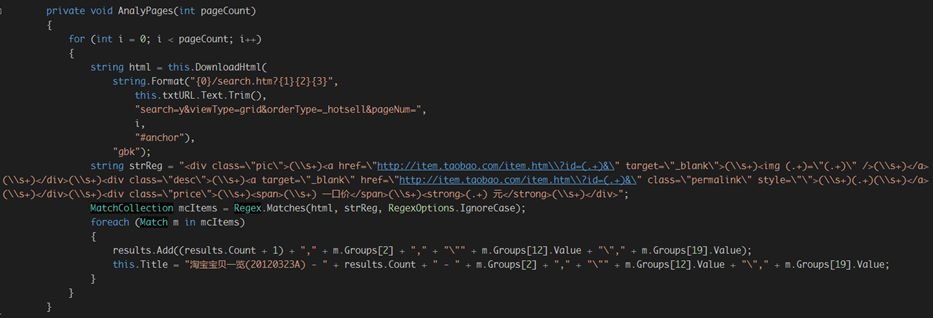
运行程序:

对程序进行异步改造
先将下载网页的函数修改如下:

修改使用到了此函数的所有函数:
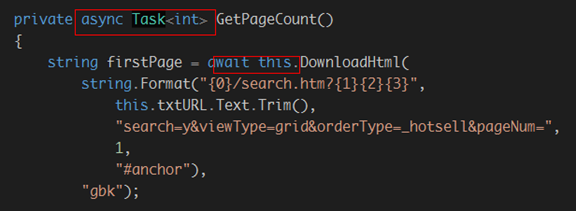


我们还需要对函数AnalyPages进行二次改造因为这里将会下载数百网页:
我们重构一下循环的内部部分:
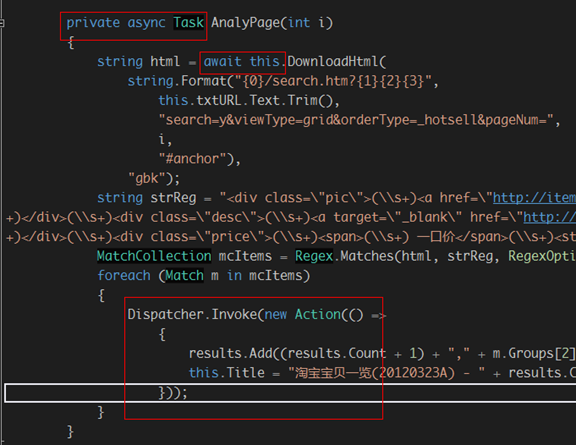
改写下AnalyPages本身:
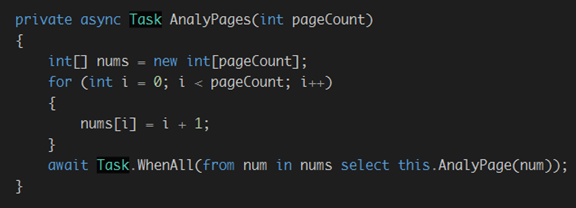
运行程序:

下篇文章我们将讲述如何取消正在运行的异步操作,并且将最终数据导出.