一、WordCount原理
初学MapReduce编程,WordCount作为入门经典,类似于初学编程时的Hello World。WordCount的逻辑就是给定一个/多个文本,统计出文本中每次单词/词出现的次数。网上找的一张MapReduce实现WordCount的图例,基本描述清楚了WordCount的内部处理逻辑。本文主要是从Hive使用的角度处理WordCount,就不赘述,之前的一篇博文有MapReduce实现WordCount的代码,可参考 https://www.cnblogs.com/walker-/p/9669631.html。
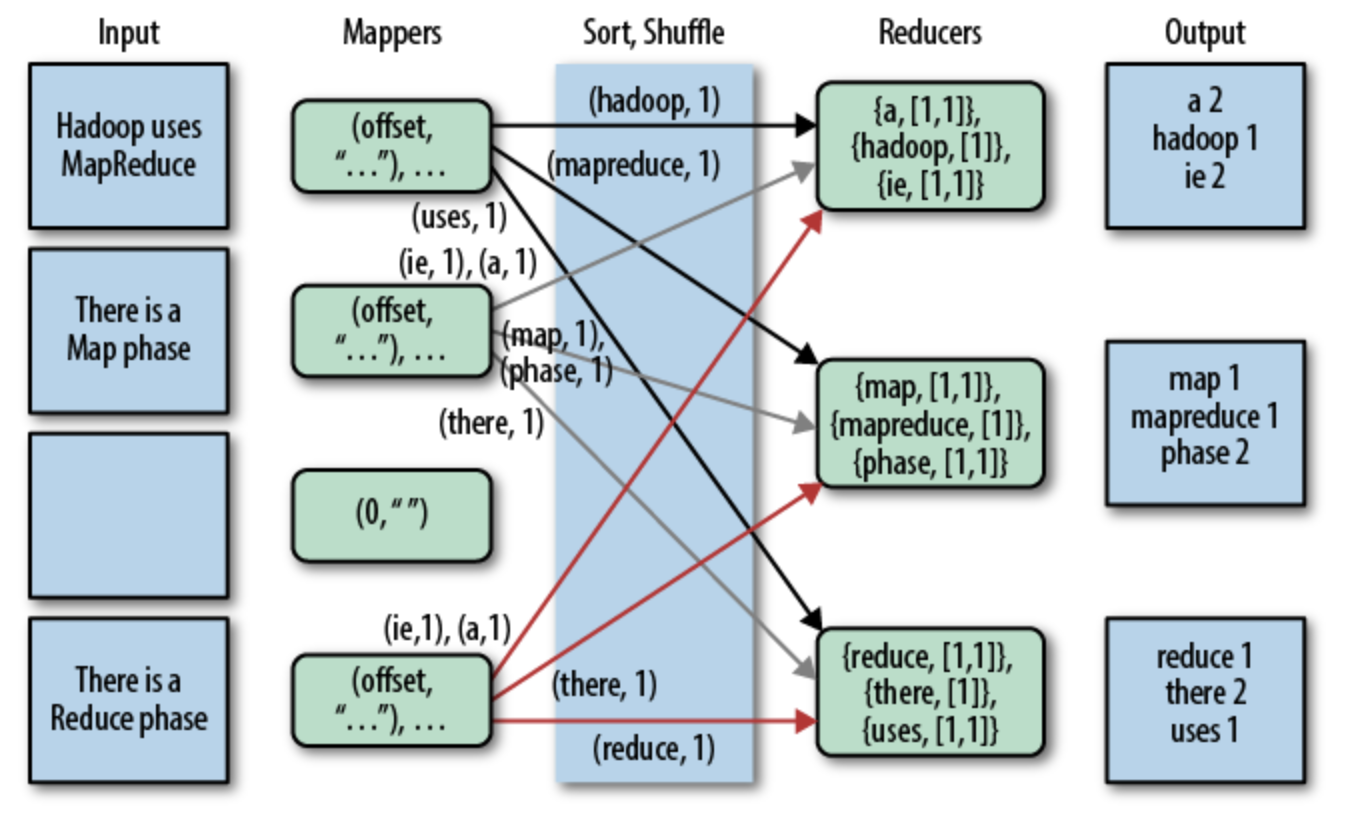
图1 MapRecude实现Word Count图例
二、Hive实现WordCount
2.1 SQL实现
先直接上SQL语句,可以看出SQL实现确实比MapReduce实现要清爽得多。大概实现流程分为三步:
- 分割本文。根据分割符对文本进行分割,切分出每个单词;
- 行转列。对分割出来的词进行处理,每个单词作为一行;
- 统计计数。统计每个单词出现的次数。
SELECT word, count(1) AS count FROM (SELECT explode(split(line, ' ')) AS word FROM docs) w GROUP BY word ORDER BY word;
2.2 实现细节
1. 准备文本内容
新建一个 /home/kwang/docs.txt 文本,文本内容如下:
hello world
hello kwang rzheng
2. 新建hive表
这里由于hive环境建表默认格式是ORC,直接load数据hive表无法直接读取,故建表时指定了表格式。
CREATE TABLE `docs`( `line` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
3. 加载数据到hive表中
加载数据到hive表中有两种方式,一种是从Linux本地文件系统加载,一种是从HDFS文件系统加载。
(1)从Linux本地文件系统加载
LOAD DATA LOCAL INPATH '/home/kwang/docs.txt' OVERWRITE INTO TABLE docs;
(2)从HDFS文件系统加载
首先需要将文件上传到HDFS文件系统
$ hadoop fs -put /home/kwang/docs.txt /user/kwang/
其次从HDFS文件系统加载数据
LOAD DATA INPATH 'docs.txt' OVERWRITE INTO TABLE docs;
加载数据到hive表后,查看hive表的内容,和原始文本格式并没有区别,将文本按行存储到hive表中,可以通过 'select * from docs;' 看下hive表内容:
hello world
hello kwang rzheng
4. 分割文本
分割单词SQL实现:
SELECT split(line, 's') AS word FROM docs;
分割后结果:
["hello","world"] ["hello","kwang","rzheng"]
可以看出,分割后的单词仍是都在一行,无法实现想要的功能,因此需要进行行转列操作。
5. 行转列
行转列SQL实现:
SELECT explode(split(line, ' ')) AS word FROM docs;
转换后的结果:
hello
world
hello
kwang
rzheng
6. 统计计数
SELECT word, count(1) AS count FROM (SELECT explode(split(line, ' ')) AS word FROM docs) w GROUP BY word ORDER BY word;
统计后结果:
hello 2 kwang 1 rzheng 1 world 1
至此,Hive已实现WordCount计数功能。
【参考资料】
[1]. https://www.oreilly.com/library/view/programming-hive/9781449326944/ch01.html