假设数据集是独立同分布的,可以将数据集划分为不同的比例:Train Set and Test Set.
同时在Train Set and Test Set上做精度测试,或者隔一段时间在Test Set上做测试,来判断训练模型是否发生过拟合,受否需要提前的终止,目的是选择最好的模型参数。(严格的说,其实应该是Validation)
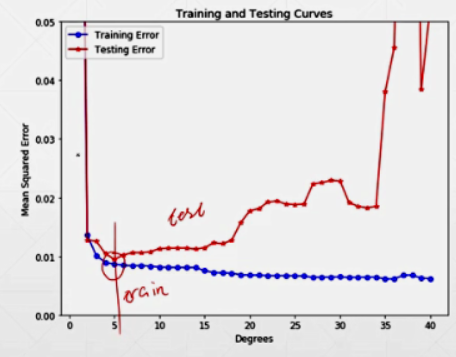
严格的会分为三部分:Train Set; Validation Set(提前终止,提高泛化能力); Test Set(不会得到)
K-fold cross-validation:每个数据都有可能back propagation。
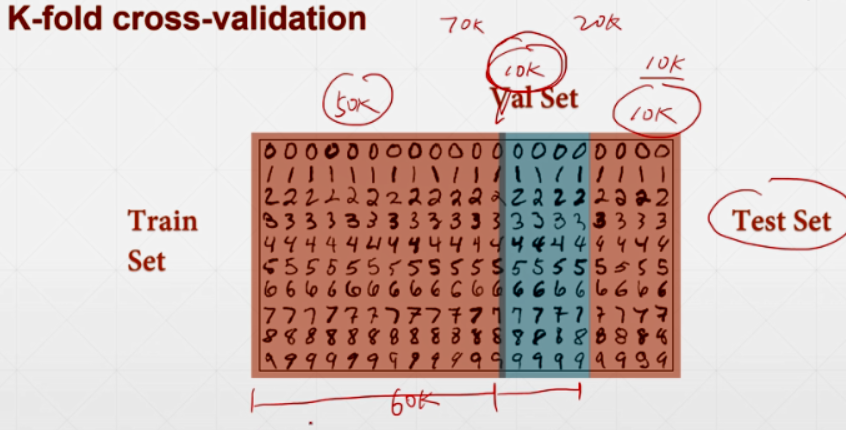
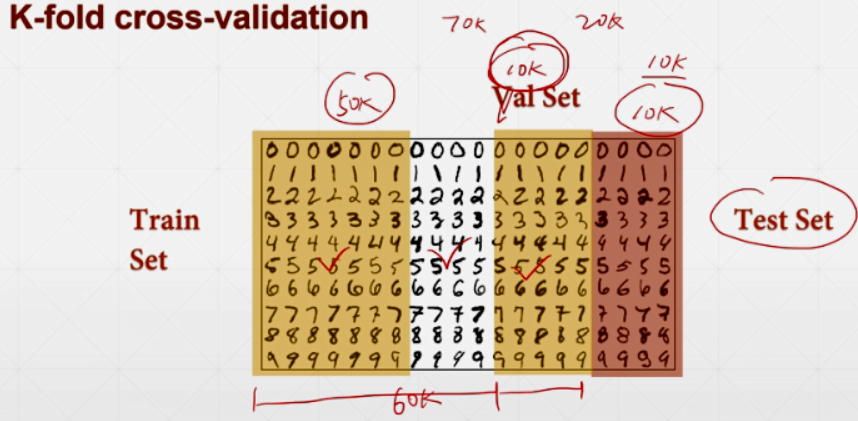
换着方式取Train Set,将能利用的数据都利用起来: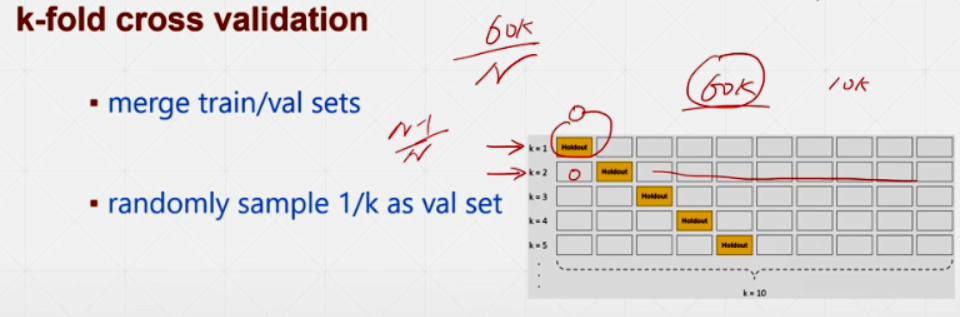
减缓过拟合的方法:

1) regularization
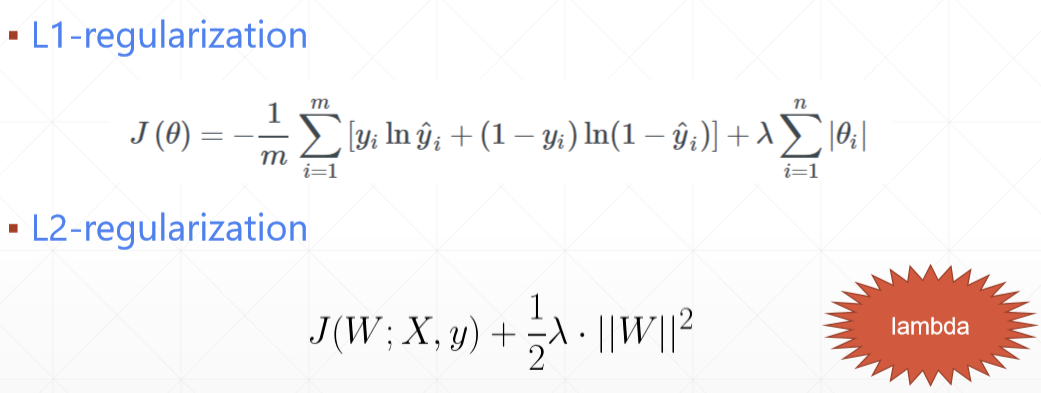
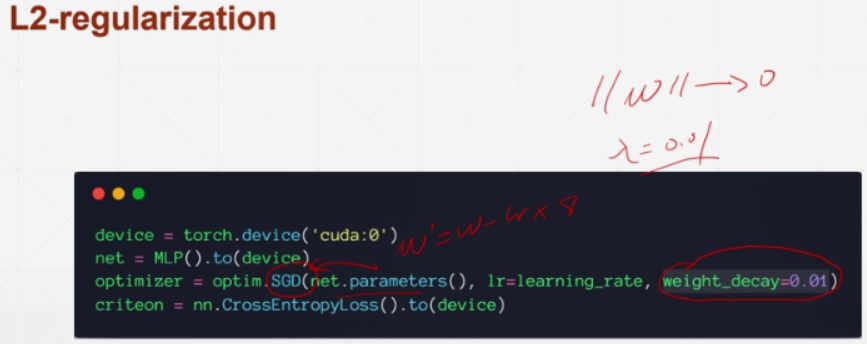

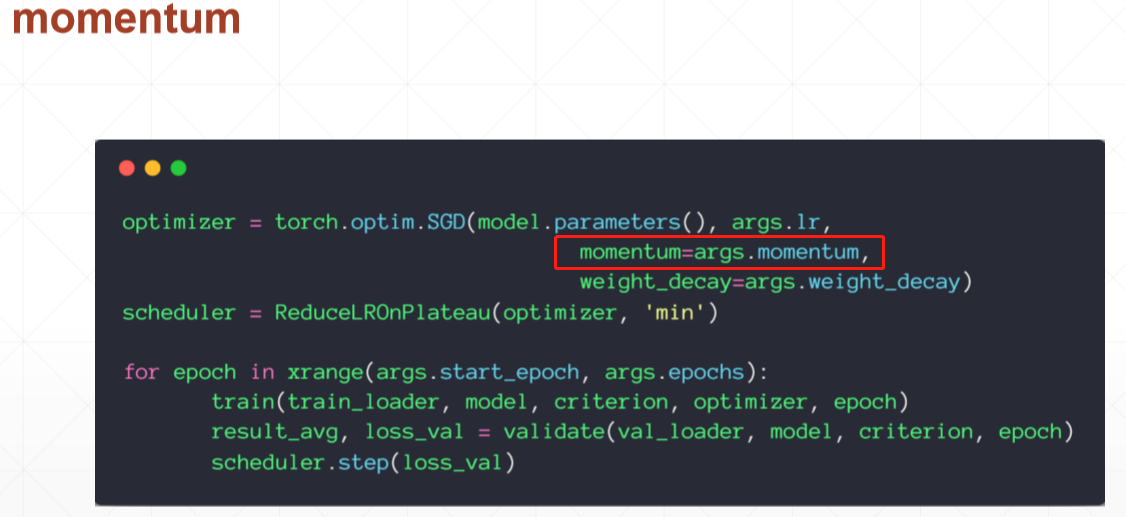
2)momentum
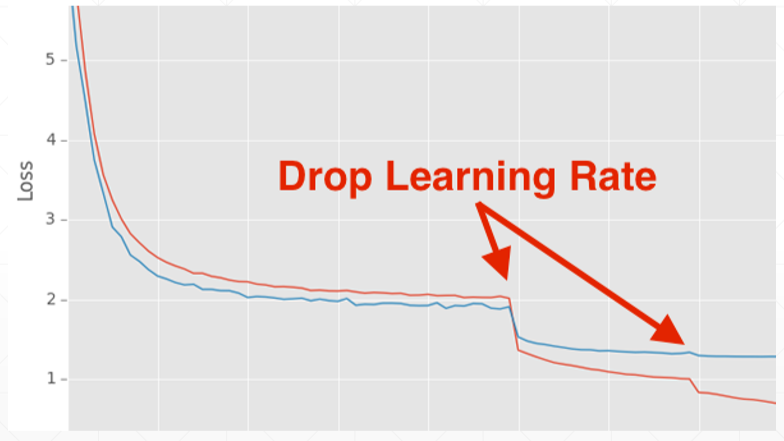
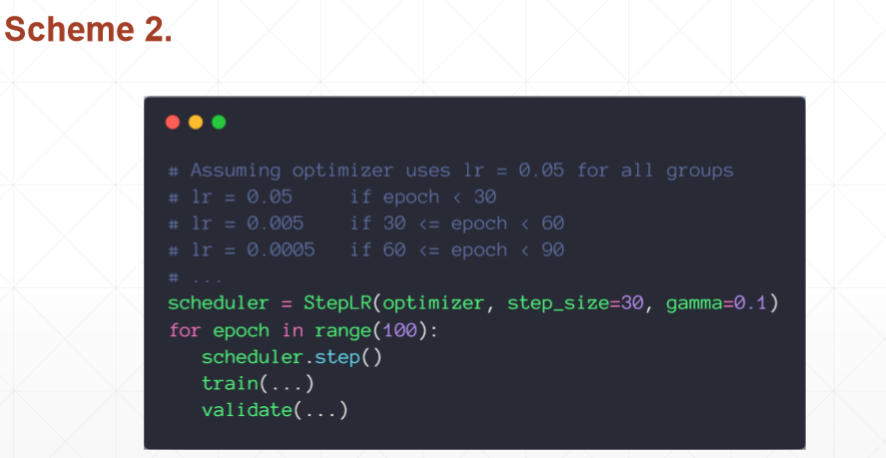
3)Learning rate tunning

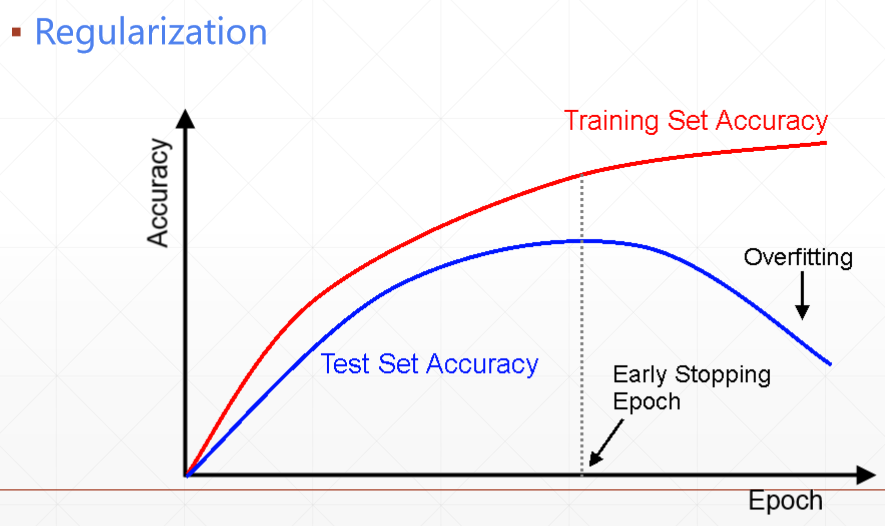
4)Early Stopping

5)Dropout


pytorch和tensorflow中的Dropout参数含义是不同的
