作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
1.将爬虫大作业产生的csv文件上传到HDFS
(1)在HDFS里创建一个目录用于存放待分析的大数据文件。

(2)把文件上传到HDFS。


2.对CSV文件进行预处理生成无标题文本文件
(1)创建一个pre_deal.sh脚本文件对csv文件进行预处理,为数据编号。
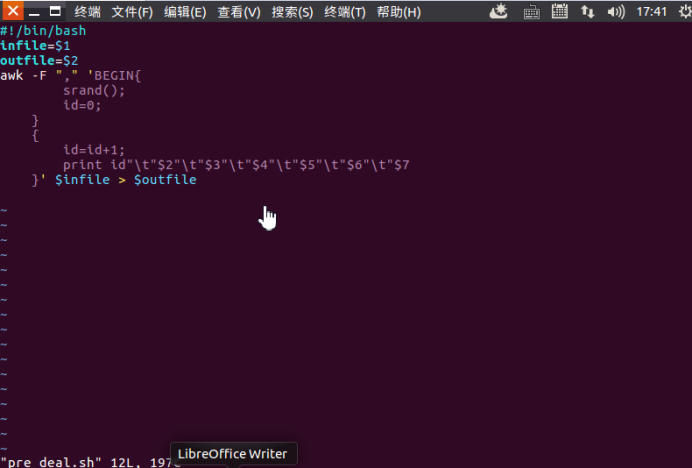
(2)由csv文件转换为无标题的文本文件
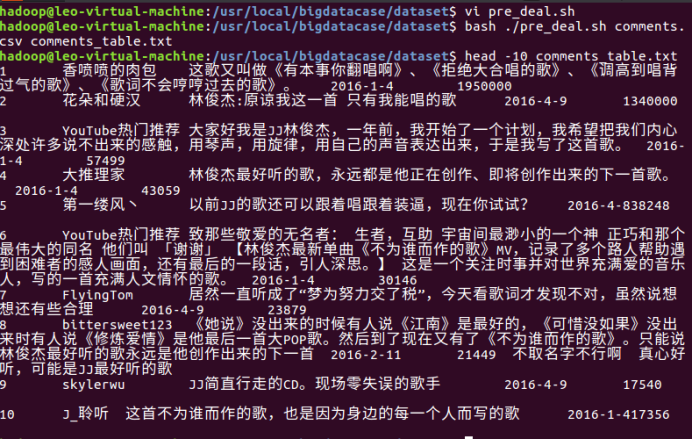
3.把hdfs中的文本文件最终导入到数据仓库Hive中
(1)启动Hadoop系统,进入Hive数据仓库创建数据库
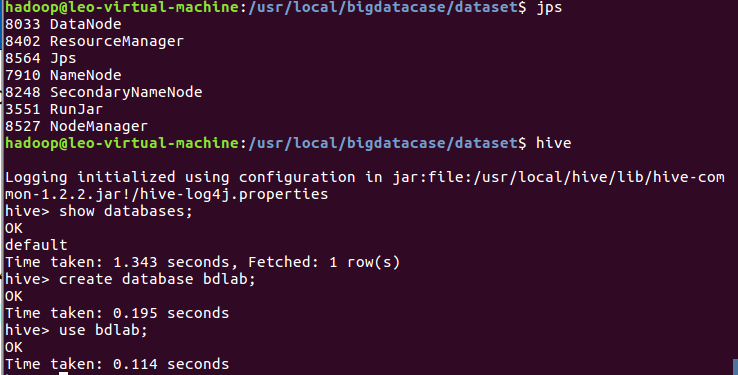
(2)创建一个comments表把数据导入到Hive中

4.在Hive中查看并分析数据

5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
- 查询数据总数。
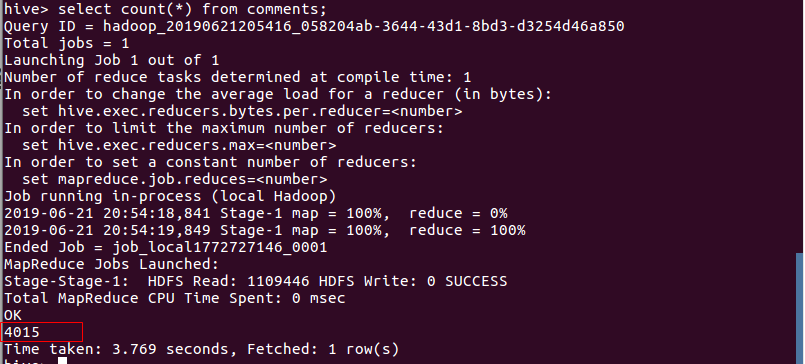
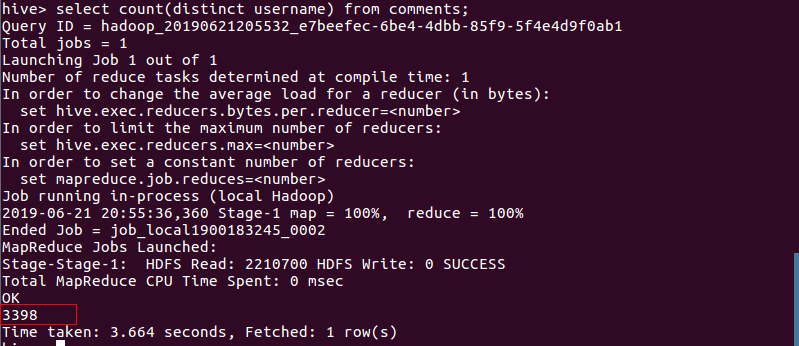
- 统计不重复的总数,即用户总数
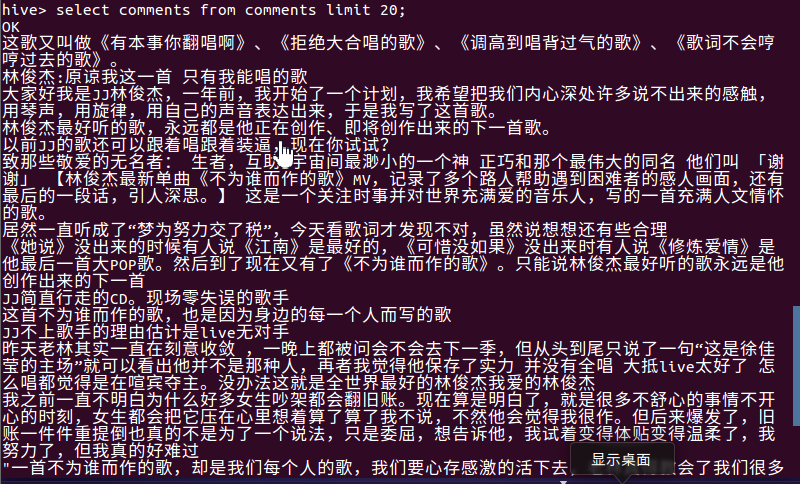
- 查看前20条评论的内容
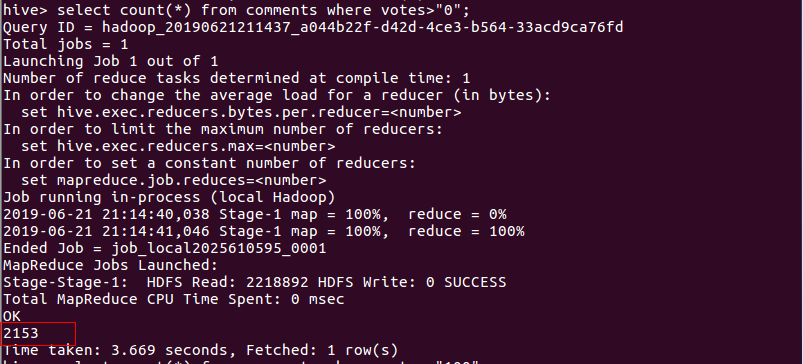
- 统计被点赞过的评论的数量。
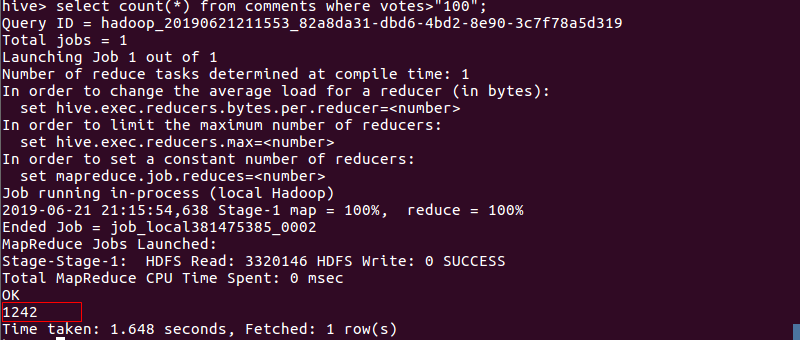
- 统计点赞超过100的评论的数量。
- 查看点赞数前10的评论内容及点赞数量
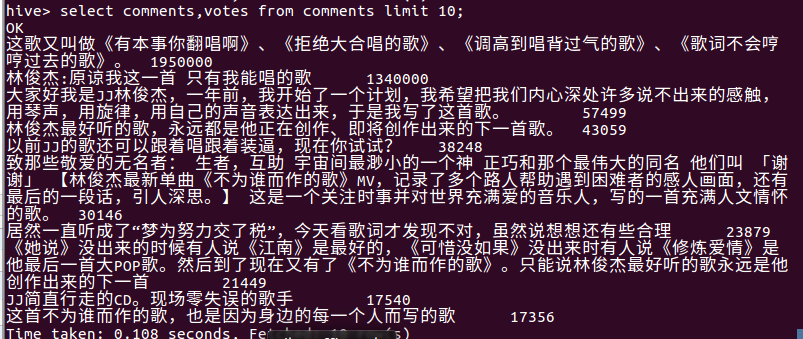
- 统计有被回复的评论数
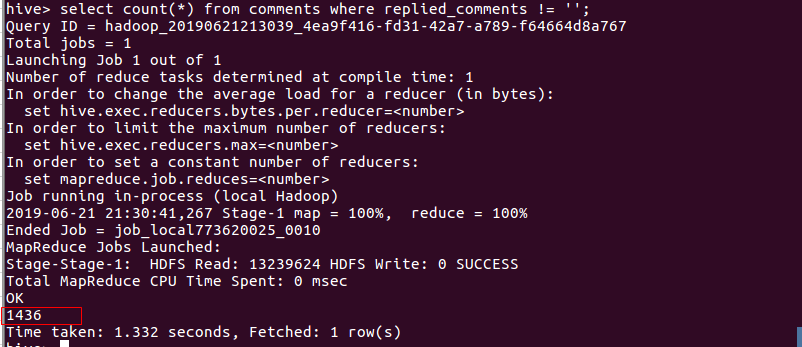
- 查看内容提到高考的评论
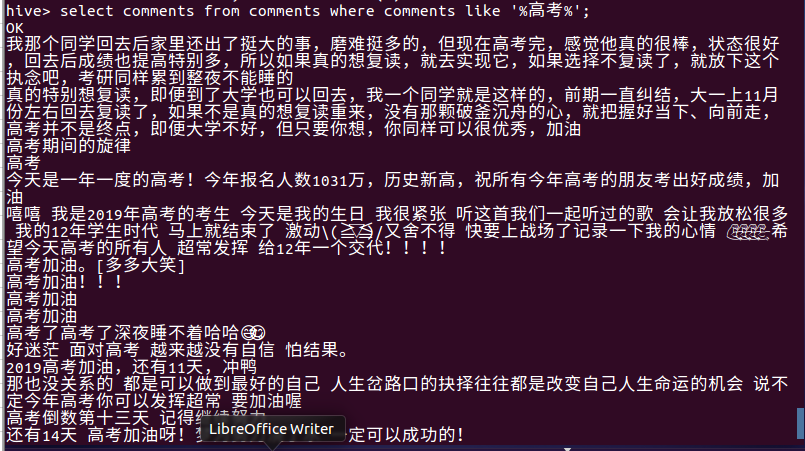
- 查看内容提到开通会员的评论
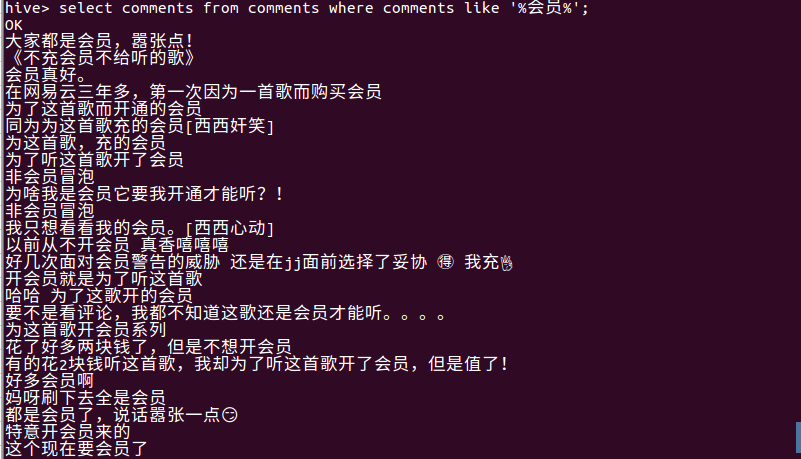
- 统计评论中开通会员的用户数
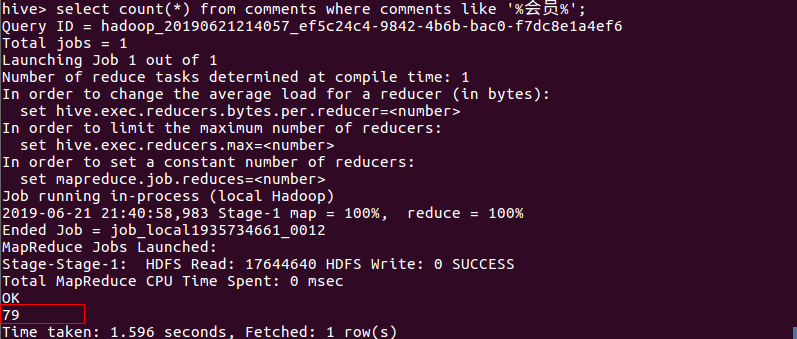
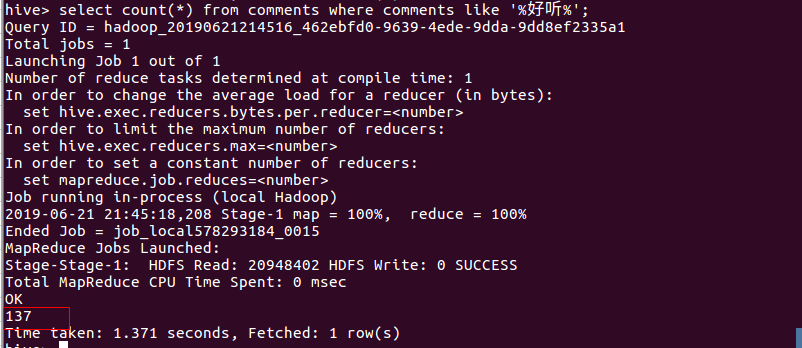
- 统计内容包含喜欢,好听的评论数。
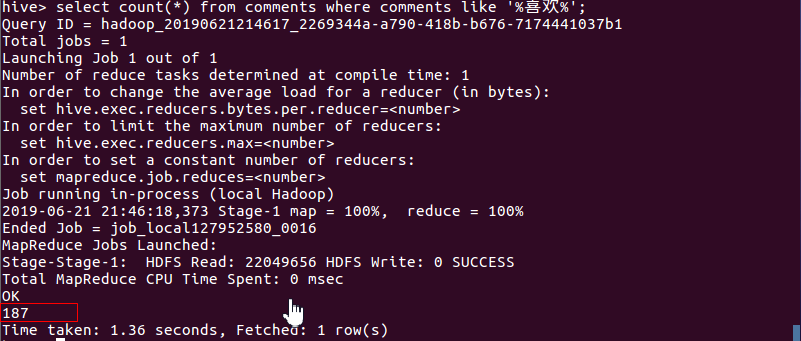
- 查看喜欢这首歌的评论内容
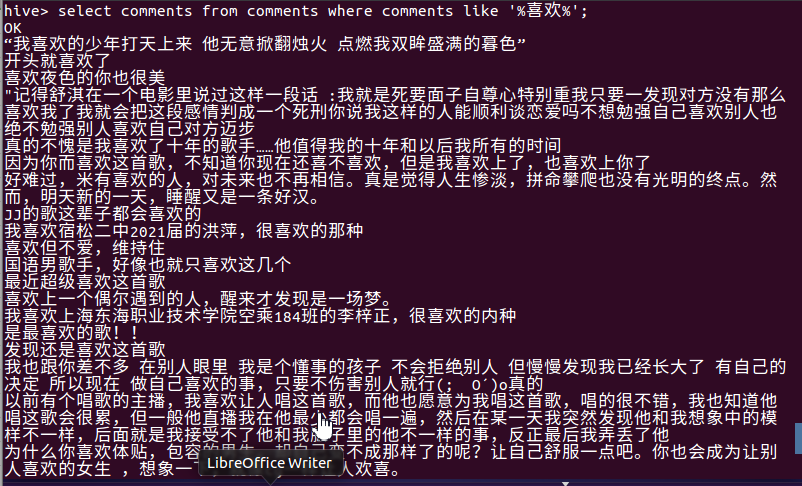
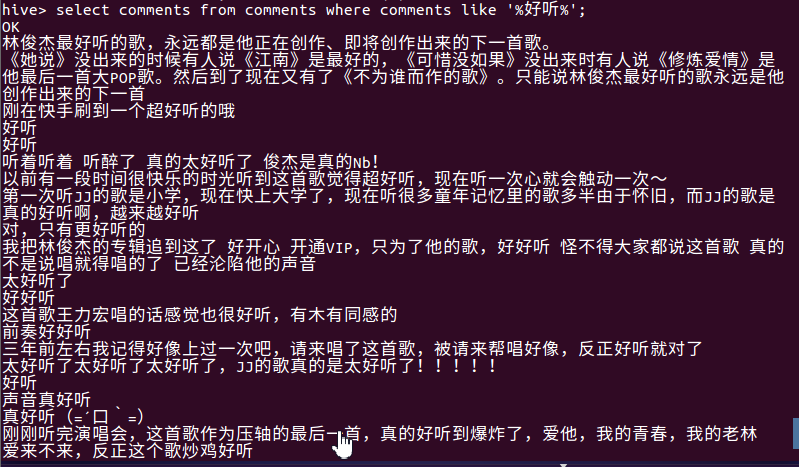
总结:评论总数为4015,用户数为3398,其中很多用户认为歌曲很励志,许多临近高考的听众,同时也有很多听众在评论中提到歌曲很好听,很喜欢,甚至为了这一首歌开通了会员。点赞数量最多的用户香喷喷的肉包拥有1950000个点赞,评论内容为:这歌又叫做《有本事你翻唱啊》、《拒绝大合唱的歌》、《调高到唱背过气的歌》、《歌词不会哼哼过去的歌》。