排序算法总结:
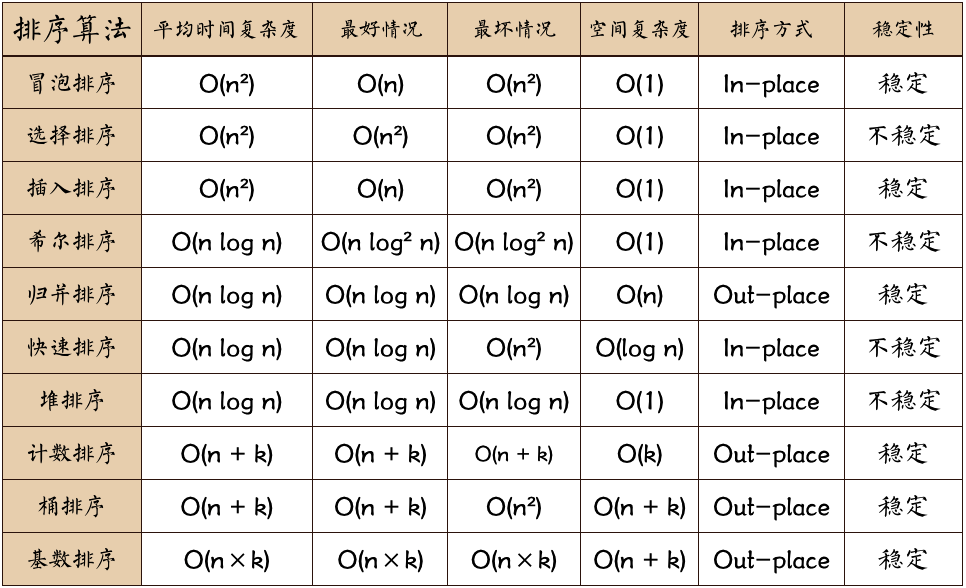
图片名词解释:
- n: 数据规模
- k: “桶”的个数
- In-place: 占用常数内存,不占用额外内存
- Out-place: 占用额外内存
该节参照:https://blog.csdn.net/weixin_41190227/article/details/86600821
一、快速排序
1.递归形式(一)
# 快速排序递归玩法 def quicksort(arr): # 结束条件 if len(arr) <= 1: return arr # 用中间值更稳定 middle = arr[len(arr) // 2] # 记得将middle拿出来,最后再放到中间 del arr[len(arr) // 2] # 利用列表生成式,100W数据,2.9s # left = [x for x in arr if x <= middle] # right = [x for x in arr if x > middle] # 2.6s left = [] right = [] for x in arr: left.append(x) if x <= middle else right.append(x) # 记得把middle放中间 return quicksort(left) + [middle] + quicksort(right) if __name__ == '__main__': arr = list(range(100000)) import random random.shuffle(arr) sorted = quicksort(arr) print(sorted)
2.递归形式(二)
# partition(data,left,right) def partition(data, left, right): tmp = data[left] # 取最左边的数作为mid while left < right: # 左指针小于右指针时循环,左右重叠终止 while left < right and data[right] >= tmp: # 当right数大于mid,则right-- right -= 1 data[left] = data[right] # 当right数小于mid,则将right数放到左边left位置 while left < right and data[left] <= tmp: # 当left数小于mid,则left++ left += 1 data[right] = data[left] # 当left数大于mid,则将left数放到右边right位置 data[left] = tmp # 当left与right重叠后,重叠的位置就是mid的位置,将tmp覆盖在此位置 return left # 返回mid数的idx(left和right一样) def quicksort2(data, left, right): if left < right: # 当left<right时才递归 mid = partition(data, left, right) # 获取中间数的idx,idx左边的数都小于mid,右边的都大于mid # 分别对两边递归排序 quicksort2(data, left, mid - 1) quicksort2(data, mid + 1, right) if __name__ == '__main__': arr = list(range(100000)) import random random.shuffle(arr) quicksort2(arr, 0, len(arr) - 1) print(arr)
3.非递归形式
# 非递归玩法 def quicksort2(arr): ''' 模拟栈操作实现非递归的快速排序 ''' if len(arr) < 2: return arr stack = [] stack.append(len(arr) - 1) stack.append(0) while stack: l = stack.pop() r = stack.pop() index = partition(arr, l, r) if l < index - 1: stack.append(index - 1) stack.append(l) if r > index + 1: stack.append(r) stack.append(index + 1) def partition(arr, start, end): # 分区操作,返回基准线下标 pivot = arr[start] while start < end: while start < end and arr[end] >= pivot: end -= 1 arr[start] = arr[end] while start < end and arr[start] <= pivot: start += 1 arr[end] = arr[start] # 此时start = end arr[start] = pivot return start if __name__ == '__main__': li = list(range(1000000)) import random random.shuffle(li) sorted = quicksort2(li)
二、插入排序
# 插入排序 def insertsort(arr): count = len(arr) # 外层循环每循环一次,就将一个未排序的数插入前面排好的队列中 for i in range(1, count): j = i # 内存循环,一个一个比较 while j >= 1: # 如果后面比前面小,则交换位置 if arr[j] < arr[j - 1]: arr[j - 1], arr[j] = arr[j], arr[j - 1] j -= 1 else: break if __name__ == '__main__': arr = list(range(10000)) import random random.shuffle(arr) insertsort(arr)
三、冒泡排序
# 冒泡排序 def bubblesort(arr): count = len(arr) # 外层循环每循环一次,就在arr的最后排好一个大值 for i in range(0, count): # 内层循环每循环一次,就是两个相邻数比较,前面大则交换,后面大则不变 for j in range(0, count - 1 - i): if arr[j] > arr[j + 1]: # 交换前后两个值 arr[j], arr[j + 1] = arr[j + 1], arr[j] if __name__ == '__main__': arr = list(range(10000)) import random random.shuffle(arr) bubblesort(arr)
四、选择排序
# 选择排序 def selectionsort(arr): count = len(arr) # 找到列表中的最小值,排到前面 for i in range(0, count - 1): # 初始化剩余未排部分的最小值为第一个数 min_idx = i # 找到剩余未排部分的最小值的索引 for j in range(i + 1, count): if arr[j] < arr[min_idx]: min_idx = j # 交换找到的最小值与第一个值 arr[i], arr[min_idx] = arr[min_idx], arr[i] if __name__ == '__main__': arr = list(range(1000)) import random random.shuffle(arr) selectionsort(arr)
五、归并排序

# 归并算法,将两个有序列表合并成一个有序列表 def merge(left, right, arr): length = len(arr) # 获取了总长度后,就清空,用于存放排好序的数据 arr.clear() i, j = 0, 0 # i和j索引加起来的值不能大于length-2 while i + j <= length - 2: # 谁小就先放入arr中 if left[i] < right[j]: arr.append(left[i]) # 如果是left的最后一个元素,则将right中剩下的全部放入arr,包括当前right[j] if i == len(left) - 1: arr.extend(right[j:]) # 退出循环,排序完毕 break # 如果不是left的最后一个元素,则i++ i += 1 else: arr.append(right[j]) # 如果是right的最后一个元素,则将left中剩下的全部放入arr,包括当前left[i] if j == len(right) - 1: arr.extend(left[i:]) break # 如果不是right的最后一个元素,则j++ j += 1 # 归并排序,利用分治法,递归的进行归并 def mergesort(arr): # 当列表只剩1个元素的时候,不需要排序 if len(arr) < 2: return # 获取中间元素的idx mid_idx = len(arr) // 2 # 将列表切成两份(拷贝) left = arr[:mid_idx] right = arr[mid_idx:] # 各自排序 mergesort(left) mergesort(right) # 归并起来 merge(left, right, arr) if __name__ == '__main__': arr = list(range(100000)) import random random.shuffle(arr) mergesort(arr)
六、希尔排序
希尔排序是直接插入排序的优化版本,分组进行直接插入排序,逐渐减小组的数量(减小步长),直到只剩1组。
# 希尔排序(shell sort) def shellsort(arr): # 获取总长度 alen = len(arr) n = alen # 每次循环步长都小一半 while n > 0: # 计算该次的步长 n = n // 2 # 一共有n组,元素之间的步长也是n for i in range(n): # 每一组有alen//n个元素(最后一组可能是alen//n+1个) for j in range(i, alen, n): # 以下过程就是直接插入排序 temp = arr[j] if temp < arr[j - n]: while temp < arr[j - n] and j > 0: arr[j] = arr[j - n] j = j - n arr[j] = temp if __name__ == '__main__': arr = list(range(100000)) import random random.shuffle(arr) shellsort(arr)
七、堆排序
堆排序的步骤:
1.生成堆
2.从根节点出数
3.将最后一个位置的数放到根节点
4.调整堆
5.循环2-4
# 调整堆 def sift(data, low, high): # low为开头,high为结尾 i = low # 根节点的idx为low j = 2 * i + 1 # 根节点的左子节点的idx为2*i+1 temp = data[i] # 获取根节点 while j <= high: # 说明根节点有子节点 if j < high and data[j] < data[j + 1]: # 根节点有右节点,然后比较左右子节点大小 j += 1 # 如果右节点大,则j为右节点 if temp < data[j]: # 如果根节点小于子节点中较大者 data[i] = data[j] # 将大的子节点的值替换到根节点,此时子节点空出来 i = j # 将该空出来的位置变为根节点 j = 2 * i + 1 # 继续计算新的根节点的子节点,准备下次循环 else: break # 如果根节点大于子节点,则停止循环 # 退出循环后,将temp里的值(也就是最上层根节点的值)放入空位中 data[i] = temp def heapsort(data): n = len(data) # 生成堆 for i in range(n // 2 - 1, -1, -1): # 从最后一个有子节点的父节点开始,调整到根节点 sift(data, i, n - 1) # 出数 for i in range(n - 1, -1, -1): # 从最后一个数开始循环 data[0], data[i] = data[i], data[0] # 交换最后一个数和根(根最大),相当于将排好序的数放在最后,堆的范围减小1 sift(data, 0, i - 1) # 将最后一个数交换到根,然后进行一次调整 # 时间装饰器 def timewrap(func): import time def warp(*args, **kwargs): start = time.time() func(*args, **kwargs) end = time.time() print(end - start) return warp @timewrap def apply_sort_func(arr): heapsort(arr) if __name__ == '__main__': arr = list(range(1000000)) import random random.shuffle(arr) apply_sort_func(arr) print(arr)
≧◔◡◔≦