Facebook 运维内幕曝光:一人管理2万台服务器
目前,Facebook 已经凭借它在网络基础建设上的可扩展能力成为了行业的领军者。Facebook 数据中心运维主管 Delfina Eberly(下图人物) 在“7x24 Exchange 2013 秋季会议”上的演讲中为我们透露了 Facebook 部分内部运维数据,下面我们来具体了解下。

Facebook 数据中心运维主管 Delfina Eberly
服务器数量惊人,一人管理 2 万台
Facebook 服务器数量惊人,其硬件方面的工作重点主要放在“可服务性”上,内容也涉及服务器的初期设计,一系列工作的目标就是为了保证数据机房的设备维修最简单、最 省时。她介绍说,每个 Facebook 数据中心的运维工作人员管理了至少 20,000 台服务器,其中部分员工会管理数量高达 26,000 多个的系统。
近期 Facebook 的服务器与管理人数比又创下了新高,目前已经超过 10000:1,可以查看文章高扩展性对此进行更加详细的了解。
大数据汹涌,运维工作不轻松
在 Facebook 数据中心做运维工作并不轻松,对工作人员的能力要求很高。他们每天面对的是海量数据。
据统计,Facebook 目前拥有 11.5 亿用户,日常登录用户约 7.2 亿。每天 Facebook 用户分享的内容达到 47.5 亿条,“赞”按钮点击次数近 45 亿次。Facebook 目前存储了 2400 亿张照片,每月照片存储容量约增加 7 PB(注,单位换算:1PB=1024TB)。
自动故障诊断系统:原为留住人才
为了管理运维工作,Facebook 已经开发了相应软件来自动化处理日常运维任务,如 CYBORG 可自动检测服务器问题并进行修复。如果 CYBORG 无法自动修复检查出的问题,系统将自动给订单系统发送警告,并分派给数据中心工作人员,以对相应问题进行详细追踪与分析。
Eberly 提到,自动化工作的目标是尽量避免将技术人员派往现场解决问题,除非必须对服务器进行现场处理。强调自动化不是因为 Facebook 对打造无人数据中心感兴趣,原因在于 Facebook 重视自己的员工。
Eberly 解释说:我们要留住人才,因为大家更喜欢高水平的任务,公司希望让他们留下来与我们一起进步成长,这对 Facebook 来说至关重要。
“可服务性”主导服务器设计:节时 54%
在 Facebook,运维团队的时间与工作量是根据 Facebook 硬件设计来安排的。比方说,全部服务器从头开始就坚持“可服务性”这一原则来进行设计,那么数据中心的工作人员就没有必要老钻机房了;服务器被设计成无需 工具就可以对磁盘和组件进行替换。这样做的结果就是:Facebook 用来修理服务器的时间减少了 54%。
Eberly 介绍说,Facebook 运维团队会仔细跟踪设备故障率,这一数据会为公司的采购提供参考。公司的财产管理和订单系统用序列号来跟踪硬盘和其他组件,这方便完整了解每个硬件的生命周期。
Eberly 还提到,虽然这些系统很复杂,但并不需要太多开发者。Facebook 的运维团队仅有 3 名软件工程师,但他们对数据中心的工作来讲至关重要。
最后
从 Eberly 的介绍中,我们可以看到 Facebook 在可扩展性网络建设上的实力。同时,这也为行业提供了一些可参考的经验,如:开发自动故障系统,根据“可服务性”设计基础架构。同时,运维也是一个系统工程,需要得到其他部门的配合支持才行。
Via Datacenterknowledge
想通过手机客户端访问开源中国:请点这里
(本站只作转载,不代表本站同意文中观点或证实文中信息)
We Finally Cracked The 10K Problem - This Time For Managing Servers With 2000x Servers Managed Per Sysadmin
In 1999 Dan Kegel issued a big hairy audacious challenge to web servers:
It's time for web servers to handle ten thousand clients simultaneously, don't you think? After all, the web is a big place now.
This became known as the C10K problem. Engineers solved the C10K scalability problems by fixing OS kernels and moving away from threaded servers like Apache to event-driven servers like Nginx and Node.
Today we are considering an even bigger goal, how to support 10 Million Concurrent Connections, which requires even more radical techniques.
No similar challenge was issued for managing servers in a datacenter, but according toDave Neary from Red Hat, in a recent FLOSS Weekly episode, we have passed the 10K barrier for server management with 10,000 or more servers managed per sysadmin.
Should We Let This Milestone Pass Without Mention?
Absolutely not! It’s a stunning accomplishment with 200x-2000x increases in productivity. Dave said he remembered in the 1990s it took one sysadmin to manage 4 or 5 Windows servers. A Linux sysadmin could manage 50 to 60 servers.
Now companies are managing over 10,000 servers per sysadmin. This huge change is rooted both in IaaS, treating a datacenter as an elastic programmable resource, divorcing operations from infrastructure deployment, and in the DevOps revolution, with its emphasis on tools, culture, automation, metrics, sharing of resources, and infrastructure as code.
What Will It Take To Manage 10 Million Servers Per Sysadmin?
Who might know? Google of course.
As James Hamilton says, Counting Servers is Hard, but Microsoft says they have 1 million servers, and Google is planning for 10 million servers, so it may take a while before we can get to 10 million servers per sysadmin.
But when it does happen the base will be built on:
-
Treating The Datacenter As A Computer.
-
And within the datacenter Multiplex Multiple Works Loads On Computers To Increase Machine Utilization And Save Money.
-
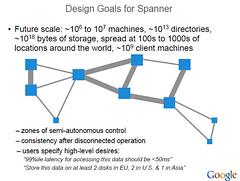
But that’s just a single datacenter. That doesn’t get you 10 to million servers. For 10 million servers you have to exploit many datacenters, so you build a system likeSpanner that can scale up to millions of machines across hundreds of datacenters and trillions of database rows.
-
Then of course you’ll need to create an amazing world spanning network to connect it all together.
-
But to really get 10 million servers per sysadmin you’ll probably need a huge dose ofDeep Learning to make sense of it all.
At a high level the approach of scaling to 10 million connections per server and scaling 10 million machines per sysadmin are the same: scalability is specialization.
But at lower level they differ completely. Scaling to 10 million connections is about removing layers and doing the work yourself. Scaling to 10 million servers is all about putting the intelligence into smarter and smarter layers. A lot like how human body utilizes trillions of individual components mediated by many autonomous systems all directed by a parallelized and decentralized brain.