如何保证高可用
(1)RabbitMQ的高可用性
1)单机模式
就是demo级别的,一般就是你本地启动了玩玩儿的,没人生产用单机模式
2)普通集群模式
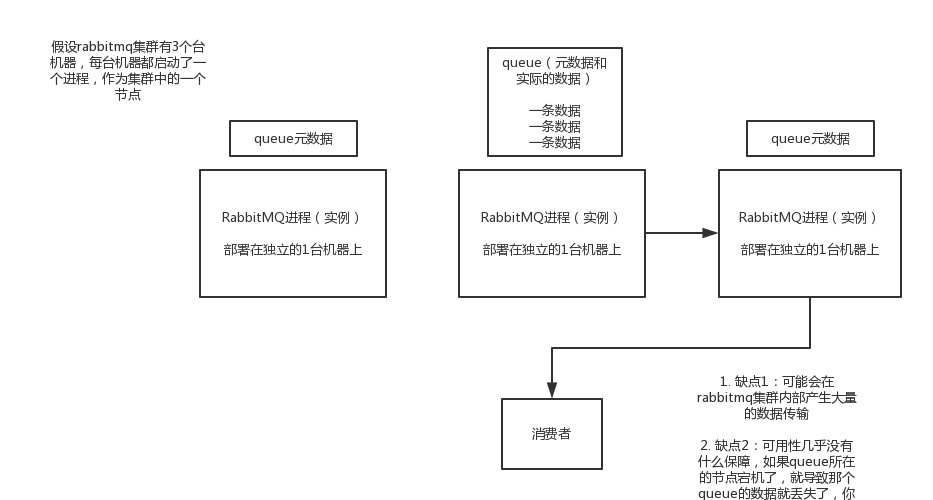
创建的queue只会在一个rabbtimq实例上,其他实例上为queue的元数据,如果连接到了另外一个实例,那么那个实例会从queue所在实例上拉取数据过来。
没做到所谓的分布式,就是个普通集群,因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个queue所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放queue的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让rabbitmq落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个queue拉取数据。
3)镜像集群模式

这种模式,才是所谓的rabbitmq的高可用模式,跟普通集群模式不一样的是,你创建的queue,无论元数据还是queue里的消息都会存在于多个实例上,然后每次你写消息到queue的时候,都会自动把消息到多个实例的queue里进行消息同步。
好处:集群高可用
坏处:
1、性能开销太大了,消息同步所有机器,导致网络带宽压力和消耗很重
2、没有扩展性可言了,如果某个queue负载很重,你加机器,新增的机器也包含了这个queue的所有数据,并没有办法线性扩展你的queue
如何开启镜像集群模式?
rabbitmq有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候可以要求数据同步到所有节点的,也可以要求就同步到指定数量的节点,然后你再次创建queue的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
(2)kafka的高可用性
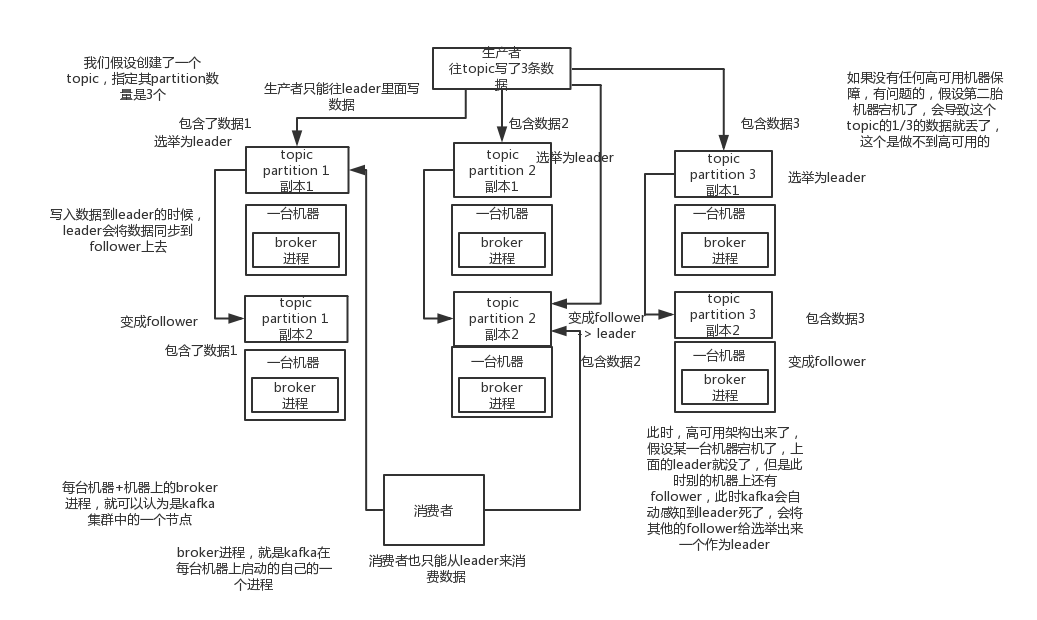
kafka一个最基本的架构认识:多个broker组成,每个broker是一个节点;你创建一个topic,这个topic可以划分为多个partition,每个partition可以存在于不同的broker上,每个partition就放一部分数据。
这就是天然的分布式消息队列,就是说一个topic的数据,是分散放在多个机器上的,每个机器就放一部分数据。
kafka 0.8以后,提供了HA机制,就是replica副本机制。每个partition的数据都会同步到其他机器上,形成自己的多个replica副本。然后所有replica会选举一个leader出来,那么生产和消费都跟这个leader打交道,然后其他replica就是follower。写的时候,leader会负责把数据同步到所有follower上去,读的时候就直接读leader上数据即可。只能读写leader?很简单,要是你可以随意读写每个follower,那么就要care数据一致性的问题,系统复杂度太高,很容易出问题。kafka会均匀的将一个partition的所有replica分布在不同的机器上,这样才可以提高容错性。
写数据的时候,生产者就写leader,然后leader将数据落地写本地磁盘,接着其他follower自己主动从leader来pull数据。一旦所有follower同步好数据了,就会发送ack给leader,leader收到所有follower的ack之后,就会返回写成功的消息给生产者。(当然,这只是其中一种模式,还可以适当调整这个行为)
消费的时候,只会从leader去读,但是只有一个消息已经被所有follower都同步成功返回ack的时候,这个消息才会被消费者读到。
如何防止消息重复?
保证消费幂等性
如何保证幂等性?
1、比如数据库主键约束,不可重复插入
2、若写redis天然幂等
3、消费的id到redis中保存下,每次消费到redis中查是否存在,存在则不消费
消息丢失

rabbitmq
1)生产者弄丢了数据
生产者将数据发送到rabbitmq的时候,可能数据就在半路给搞丢了,因为网络啥的问题,都有可能。
此时可以选择用rabbitmq提供的事务功能,就是生产者发送数据之前开启rabbitmq事务(channel.txSelect),然后发送消息,如果消息没有成功被rabbitmq接收到,那么生产者会收到异常报错,此时就可以回滚事务(channel.txRollback),然后重试发送消息;如果收到了消息,那么可以提交事务(channel.txCommit)。但是问题是,rabbitmq事务机制一搞(同步),基本上吞吐量会下来,因为太耗性能。
所以一般来说,如果你要确保说写rabbitmq的消息别丢,可以开启confirm模式,在生产者那里设置开启confirm模式之后,你每次写的消息都会分配一个唯一的id,然后如果写入了rabbitmq中,rabbitmq会给你回传一个ack消息,告诉你说这个消息ok了。如果rabbitmq没能处理这个消息,会回调你一个nack接口,告诉你这个消息接收失败,你可以重试。而且你可以结合这个机制自己在内存里维护每个消息id的状态,如果超过一定时间还没接收到这个消息的回调,那么你可以重发。
事务机制和cnofirm机制最大的不同在于,事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是confirm机制是异步的,你发送个消息之后就可以发送下一个消息,然后那个消息rabbitmq接收了之后会异步回调你一个接口通知你这个消息接收到了。
所以一般在生产者这块避免数据丢失,都是用confirm机制的。
2)rabbitmq弄丢了数据
就是rabbitmq自己弄丢了数据,这个你必须开启rabbitmq的持久化,就是消息写入之后会持久化到磁盘,哪怕是rabbitmq自己挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢。除非极其罕见的是,rabbitmq还没持久化,自己就挂了,可能导致少量数据会丢失的,但是这个概率较小。
设置持久化有两个步骤,第一个是创建queue的时候将其设置为持久化的,这样就可以保证rabbitmq持久化queue的元数据,但是不会持久化queue里的数据;第二个是发送消息的时候将消息的deliveryMode设置为2,就是将消息设置为持久化的,此时rabbitmq就会将消息持久化到磁盘上去。必须要同时设置这两个持久化才行,rabbitmq哪怕是挂了,再次重启,也会从磁盘上重启恢复queue,恢复这个queue里的数据。
而且持久化可以跟生产者那边的confirm机制配合起来,只有消息被持久化到磁盘之后,才会通知生产者ack了,所以哪怕是在持久化到磁盘之前,rabbitmq挂了,数据丢了,生产者收不到ack,你也是可以自己重发的。
哪怕是你给rabbitmq开启了持久化机制,也有一种可能,就是这个消息写到了rabbitmq中,但是还没来得及持久化到磁盘上,结果不巧,此时rabbitmq挂了,就会导致内存里的一点点数据会丢失。
3)消费端弄丢了数据
rabbitmq如果丢失了数据,主要是因为你消费的时候,刚消费到,还没处理,结果进程挂了,比如重启了,那么就尴尬了,rabbitmq认为你都消费了,这数据就丢了。
这个时候得用rabbitmq提供的ack机制,简单来说,就是你关闭rabbitmq自动ack,可以通过一个api来调用就行,然后每次你自己代码里确保处理完的时候,再程序里ack一把。这样的话,如果你还没处理完,不就没有ack?那rabbitmq就认为你还没处理完,这个时候rabbitmq会把这个消费分配给别的consumer去处理,消息是不会丢的。
kafka
1)消费端弄丢了数据
唯一可能导致消费者弄丢数据的情况,就是说,你那个消费到了这个消息,然后消费者那边自动提交了offset,让kafka以为你已经消费好了这个消息,其实你刚准备处理这个消息,你还没处理,你自己就挂了,此时这条消息就丢咯。
这不是一样么,大家都知道kafka会自动提交offset,那么只要关闭自动提交offset,在处理完之后自己手动提交offset,就可以保证数据不会丢。但是此时确实还是会重复消费,比如你刚处理完,还没提交offset,结果自己挂了,此时肯定会重复消费一次,自己保证幂等性就好了。
生产环境碰到的一个问题,就是说我们的kafka消费者消费到了数据之后是写到一个内存的queue里先缓冲一下,结果有的时候,你刚把消息写入内存queue,然后消费者会自动提交offset。
然后此时我们重启了系统,就会导致内存queue里还没来得及处理的数据就丢失了
2)kafka弄丢了数据
这块比较常见的一个场景,就是kafka某个broker宕机,然后重新选举partiton的leader时。大家想想,要是此时其他的follower刚好还有些数据没有同步,结果此时leader挂了,然后选举某个follower成leader之后,他不就少了一些数据?这就丢了一些数据啊。
生产环境也遇到过,我们也是,之前kafka的leader机器宕机了,将follower切换为leader之后,就会发现说这个数据就丢了
所以此时一般是要求起码设置如下4个参数:
给这个topic设置replication.factor参数:这个值必须大于1,要求每个partition必须有至少2个副本
在kafka服务端设置min.insync.replicas参数:这个值必须大于1,这个是要求一个leader至少感知到有至少一个follower还跟自己保持联系,没掉队,这样才能确保leader挂了还有一个follower吧
在producer端设置acks=all:这个是要求每条数据,必须是写入所有replica之后,才能认为是写成功了
在producer端设置retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了
我们生产环境就是按照上述要求配置的,这样配置之后,至少在kafka broker端就可以保证在leader所在broker发生故障,进行leader切换时,数据不会丢失
3)生产者会不会弄丢数据
如果按照上述的思路设置了ack=all,一定不会丢,要求是,你的leader接收到消息,所有的follower都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试,重试无限次。
小惊喜
1、积少成多,下载高佣联盟,领取各大平台隐藏优惠券,每次购物省个十块八块不香吗,通过下方二维码注册的用户可添加微信liershuang123(微信号)领取价值千元海量学习视频。
为表诚意奉献部分资料:
软件电子书:链接:https://pan.baidu.com/s/1_cUtPtZZbtYTF7C_jwtxwQ 提取码:8ayn
架构师二期:链接:https://pan.baidu.com/s/1yMhDFVeGpTO8KTuRRL4ZsA 提取码:ui5v
架构师阶段课程:链接:https://pan.baidu.com/s/16xf1qVhoxQJVT_jL73gc3A 提取码:2k6j

2、本人重金购买付费前后端分离脚手架源码一套,现10元出售,加微信liershuang123获取源码