一、依赖安装
安装JDK
二、文件准备
hadoop-2.7.3.tar.gz
2.2 下载地址
http://hadoop.apache.org/releases.html
三、工具准备
3.1 Xshell
3.2 Xftp
四、部署图
master:192.168.136.128
slave:192.168.136.129
slave:192.168.136.130
五、Hadoop安装
以下操作,均使用root用户
5.1 主机名与IP地址映射关系配置
Master节点上,执行如下命令:
#vi /etc/hosts
在文件最后,输入如下内容:
192.168.136.128 LxfN1
192.168.136.129 LxfN2
192.168.136.130 LxfN3
保存,退出,然后通过scp命令,将配置好的文件拷贝其他两个Slave节点:
#scp /etc/hosts root@LxfN2:/etc
#scp /etc/hosts root@LxfN3:/etc
5.2 SSH免登陆配置
#ssh-keygen -t rsa
一直回车
然后分别拷贝到Master以及Slave节点:
对于LxfN1:
对于LxfN2:
scp ./id_rsa.pub root@LxfN1:/root/.ssh/id_rsa_2.pub
对于LxfN3:
scp ./id_rsa.pub root@LxfN1:/root/.ssh/id_rsa_3.pub
在LxfN1上合并所有文件成authorized_keys
分发合并后的文件authorized_keys到其他机器上
scp ./authorized_keys root@LxfN1:/root/.ssh/
scp ./authorized_keys root@LxfN1:/root/.ssh/
通过#ssh LxfN2 测试是否配置成功,如果不需要输入密码,则证明配置成功
5.3 通过Xftp将下载下来的Hadoop安装文件上传到Master及两个Slave的/usr目录下
5.4 通过Xshell连接到虚拟机,在Master及两个Slave上,执行如下命令,解压文件:
# tar zxvf hadoop-2.7.3.tar.gz
建立到解压目录的连接hadoop
5.5 在Master上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
# Hadoop Env
export HADOOP_HOME=/opt/moudles/hadoop
export PATH=PATH:PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
5.6 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Slave节点:
#scp /etc/profile root@LxfN2:/etc
#scp /etc/profile root@LxfN3:/etc
分别在两个Salve节点上执行# source /etc/profile使其立即生效
5.7 查看Hadoop版本信息

# hadoop version Hadoop 2.7.3 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff Compiled by root on 2016-08-18T01:41Z Compiled with protoc 2.5.0 From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4 This command was run using /opt/modules/hadoop/share/hadoop/common/hadoop-common-2.7.3.jar
六、Hadoop配置
以下操作均在Master节点,配置完后,使用scp命令,将配置文件拷贝到两个Slave节点即可。
切换到/opt/modules/hadoop/etc/hadoop/目录下,修改如下文件:
6.1 hadoop-env.sh
在文件最后,增加如下配置:
export JAVA_HOME=/opt/modules/jdk1.8 export HADOOP_PREFIX=/opt/modules/hadoop
6.2 yarn-env.sh
在文件最后,增加如下配置:
export JAVA_HOME=/opt/modules/jdk1.8
6.3 core-site.xml
创建tmp目录:#mkdir /usr/hadoop-2.7.3/tmp
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://LxfN1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop/tmp</value>
</property>
</configuration>
6.4 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
6.5 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6.6 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>LxfN1</value>
</property>
</configuration>
6.7 slaves
LxfN1
LxfN2
LxfN3
6.8 拷贝配置文件到两个Slave节点
在Master节点,执行如下命令:
# scp -r /opt/modules/hadoop/etc/hadoop/ root@LxcN2:/opt/modules/hadoop/etc/
# scp -r /opt/modules/hadoop/ root@LxcN3:/opt/modules/hadoop/etc/
七、Hadoop使用
7.1 格式化NameNode
Master节点上,执行如下命令
#hdfs namenode -format
7.2 启动HDFS(NameNode、DataNode)
Master节点上,执行如下命令
#start-dfs.sh
使用jps命令,分别在Master以及两个Slave上查看Java进程
可以在Master上看到如下进程:
34225 SecondaryNameNode 33922 NameNode 34028 DataNode 49534 Jps
在两个Slave上,看到如下进程:
34028 DataNode 49534 Jps
7.3 启动 Yarn(ResourceManager 、NodeManager)
Master节点上,执行如下命令
#start-yarn.sh
使用jps命令,分别在Master以及两个Slave上查看Java进程
可以在Master上看到如下进程:
34225 SecondaryNameNode
33922 NameNode
34632 NodeManager
34523 ResourceManager
34028 DataNode
49534 Jps
在两个Slave上,看到如下进程:
34632 NodeManager
34028 DataNode
49534 Jps
7.4 通过浏览器查看HDFS信息
浏览器中,输入http://LxfN1:50070
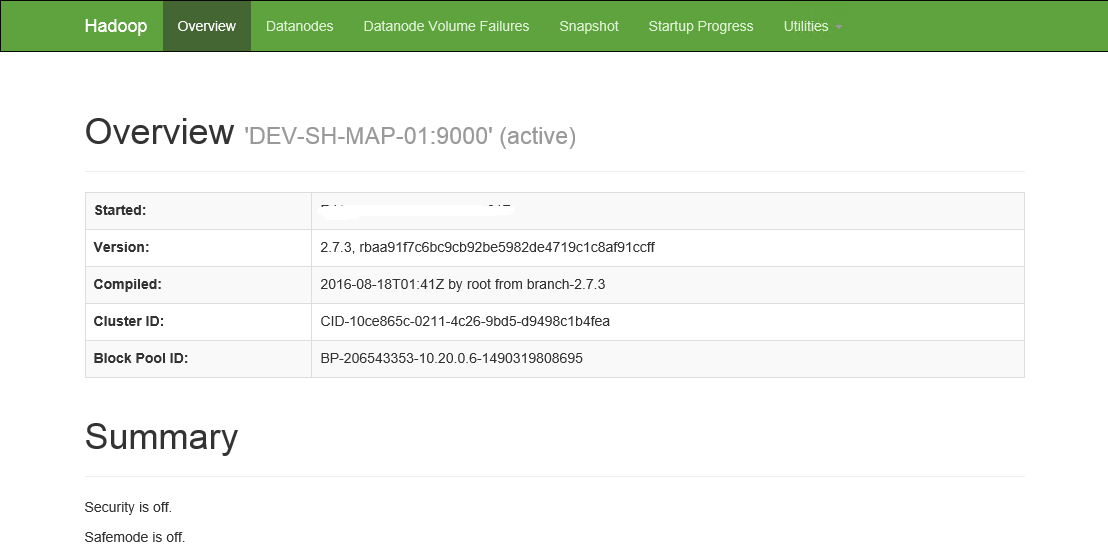
7.5 停止Yarn及HDFS
#stop-yarn.sh
#stop-dfs.sh