hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
一、依赖文件安装
1.1 JDK
参见博文:http://www.cnblogs.com/liugh/p/6623530.html
1.2 Hadoop
参见博文:http://www.cnblogs.com/liugh/p/6624872.html
1.3 Scala
参见博文:http://www.cnblogs.com/liugh/p/6624491.html
二、文件准备
spark-2.1.0-bin-hadoop2.7.tgz
下载地址:http://spark.apache.org/downloads.html
三、工具准备
3.1 Xshell
3.2 Xftp
四、部署图
master:192.168.136.128
slave:192.168.136.129
slave:192.168.136.130
五、Spark安装
以下操作,均使用root用户
5.1 通过Xftp将下载下来的Spark安装文件上传到Master及两个Slave的/usr目录下
5.2 通过Xshell连接到虚拟机,在Master及两个Slave上,执行如下命令,解压文件:
# tar zxvf spark-2.1.0-bin-hadoop2.7.tgz
5.3 在Master上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
#Spark Env
export SPARK_HOME=/usr/spark-2.1.0
export PATH=PATH:PATH:SPARK_HOME/bin:$SPARK_HOME/sbin
5.4 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Slave节点:
#scp /etc/profile root@DEV-SH-MAP-02:/etc
#scp /etc/profile root@DEV-SH-MAP-03:/etc
分别在两个Salve节点上执行# source /etc/profile使其立即生效
六、Spark配置
以下操作均在Master节点,配置完后,使用scp命令,将配置文件拷贝到两个Worker节点即可。
切换到/usr/spark-2.1.0/conf/目录下,修改如下文件:
6.1 spark-env.sh
将spark-env.sh.template重命名为spark-env.sh
#mv spark-env.sh.template spark-env.sh
使用vi编辑器,打开spark-env.sh,在文件最后,添加如下内容:
export JAVA_HOME=/usr/jdk1.8.0_121 export SCALA_HOME=/usr/scala-2.12.1 export SPARK_MASTER_IP=10.10.0.1 export SPARK_WORKER_MEMORY=1g export HADOOP_CONF_DIR=/usr/hadoop-2.7.3/etc/hadoop
6.2 slaves
将slaves.template重命名为slaves
#mv slaves.template slaves
使用vi编辑器,打开slaves,在文件最后,添加如下内容:
DEV-SH-MAP-01 DEV-SH-MAP-02 DEV-SH-MAP-03
6.3 拷贝配置文件到两个Worker节点
在Master节点,执行如下命令:
# scp -r /usr/spark-2.1.0/conf/ root@DEV-SH-MAP-02:/usr/spark-2.1.0/
# scp -r /usr/spark-2.1.0/conf/ root@DEV-SH-MAP-03:/usr/spark-2.1.0/
七、Spark使用
7.1 启动Hadoop集群
参见博文:http://www.cnblogs.com/liugh/p/6624872.html
7.2 启动Master节点
Master节点上,执行如下命令:
#start-master.sh
使用jps命令,查看Java进程:
34225 SecondaryNameNode 33922 NameNode49702 Jps 34632 NodeManager 34523 ResourceManager 34028 DataNode 36415 Master
7.3 启动Worker节点
Master节点上,执行如下命令:
#start-slaves.sh
使用jps命令,查看Java进程:

34225 SecondaryNameNode 33922 NameNode 36562 Worker 49702 Jps 34632 NodeManager 34523 ResourceManager 34028 DataNode 36415 Master
7.4 通过浏览器查看Spark信息
浏览器中,输入http://10.10.0.1:8080
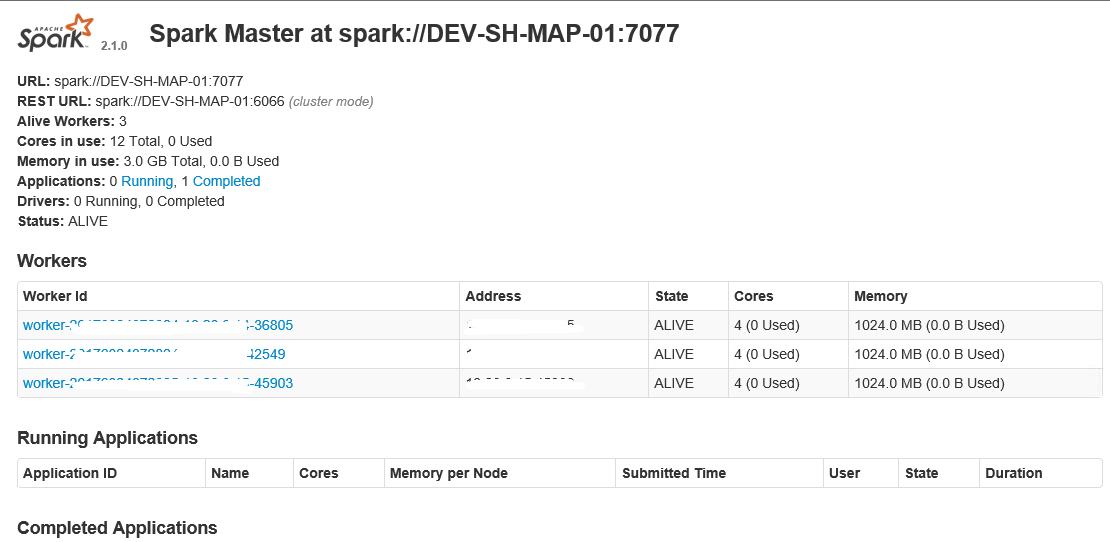
7.5 停止Master及Workder节点
#stop-master.sh
#stop-slaves.sh