依旧先来段废话呵呵,程序还在开发阶段,担心开发出来的程序会走样,所以拿出来溜溜。市面上已经有n多的采集软件了,我只是在重复轮子,比它们的好不到哪去,差到没边到是极有可能。不过相比目前的一些采集程序而言,我算是基于组件的吧,各个组件间可替换,希望能算得上是一个亮点。同时也希望这次的展示,同行专家们给予建议和批评。
目前没有解决的问题是:
1.一些需要cookie的网站,怎么采集,sina我是登录进去了,不过cnblogs我没有登录成功。
2.定时的执行,怎么样让一个任务定时执行,使用Quartz.net?,由于一个采集任务的网址可能非常之多,第一个网址采集的时间,和最后一个网址采集的时间可能相隔几小时,如果整个任务的要求是间隔1h,采集一次,那么最后一个网址可能才刚采集完又要采集了,或是上一次任务都还没有执行到该网址。这里还没有考虑采集间隔策略的情况,比如如果三次采集未发生变化则延长下次采集时间等
3.储存问题,如果使用DAS、或是数据库到是一点问题都没有,但是如果各个客户端将采集的结果以文件的形式储存,怎么将各客户机上的文件汇总合并又将是一个系统的工程
4.任务流程及组件的装配界面实现的问题,目前对流程的配置都是使用文本编辑器来编辑配置文件,极易写错,对GDI+不了解,没有想到好的方法来实现界面化的组件装配。
我们先来看一下采集的结果,再介绍整个采集的流程。采集的结果用xml保存,使用了程序内置的Store2Xml组件,如果你想储存到特定的数据库中,你可以自己写一个组件,或者提供某个cms的webservice我们再做一个适配组件。
我考虑再做一个Store2MDB的组件,便于将数据转移也是嵌入式的,不采用sqlite是因为一般用户可能不太了解。

下面我以采集http://tech.sina.com.cn/VC/index.html下的创业资讯和创业锦囊栏目为例,展示一下这个程序
step1:分析网页
这两个栏目的样式是一样的,因此我们只需要写一个采集规则就可以了。
打开任意一个栏目的列表页,查看它的源码,我们需要找到重复的片段,如下图中高亮的部分是重复出现的内容

我们将上图中的欲抽取的部分源码放到RegexBuddy中作为测试代码,用来测试我们撰写的正则
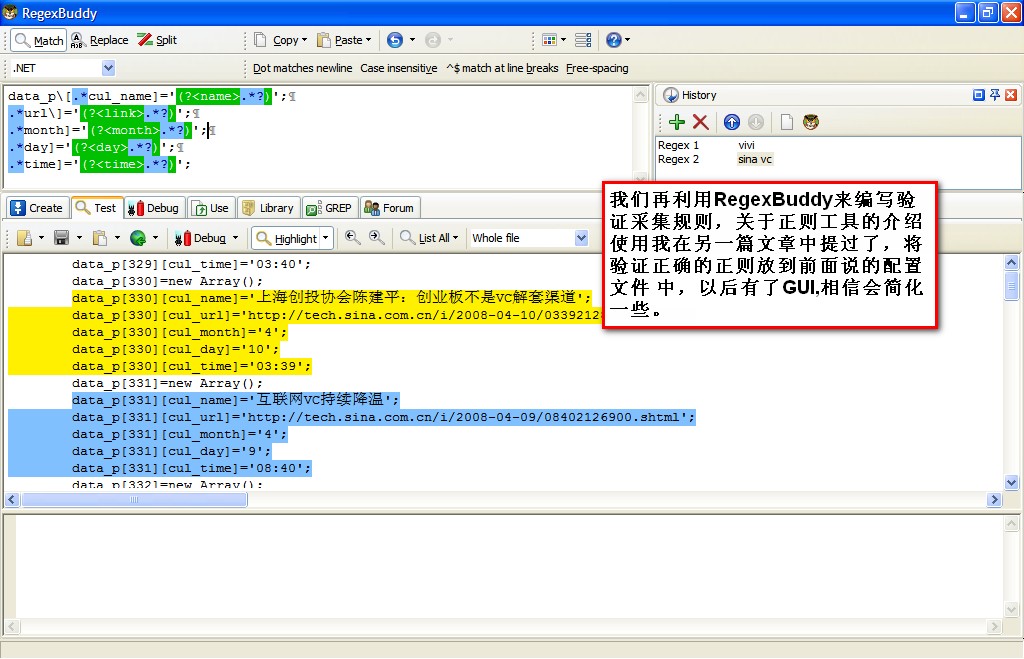
将测试完的正则放到组件的指定属性中,目前只能手工配置了,在实际中应用有一个图形化的环境,提供step by step的操作提示
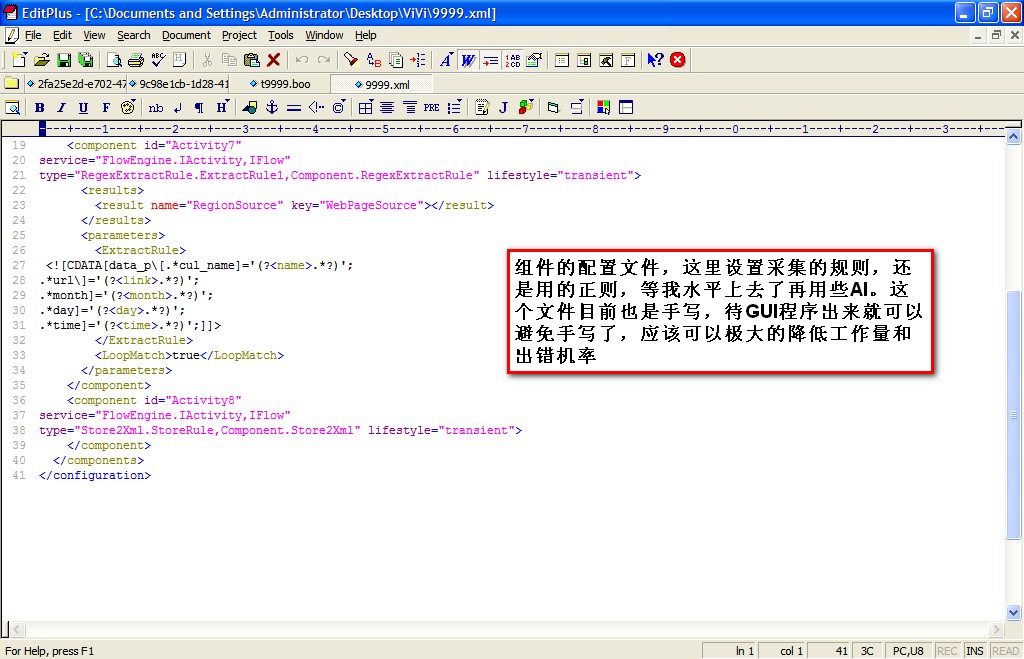
最后我们来设计组件装配置执行的流程,使用的是boo解释引擎,类似ironpython

在设计阶段总共有三个文件 ,其中文本文件储存的是欲采集的网址集,一行一个
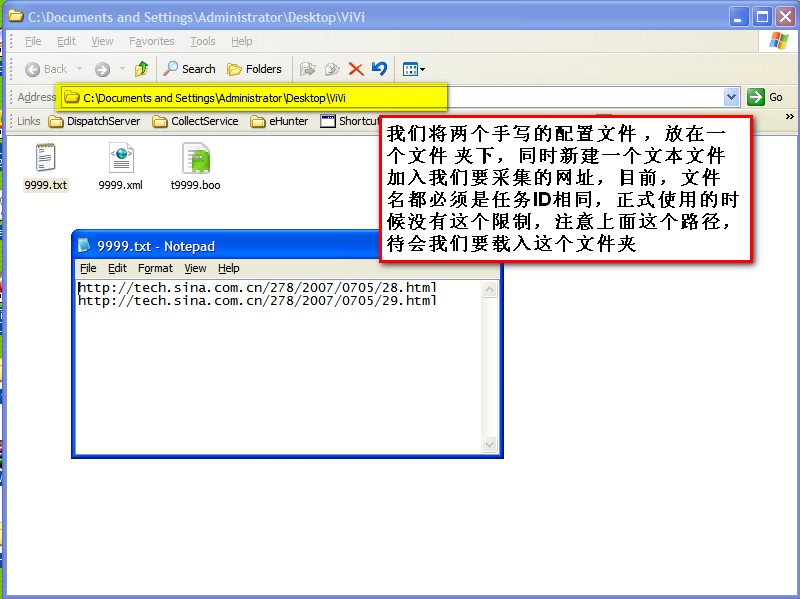
Step 2:添加任务
将设计阶段制作好的任务包添加进来,填写好信息,就可以提交任务了

下图是程序后台运行的过程
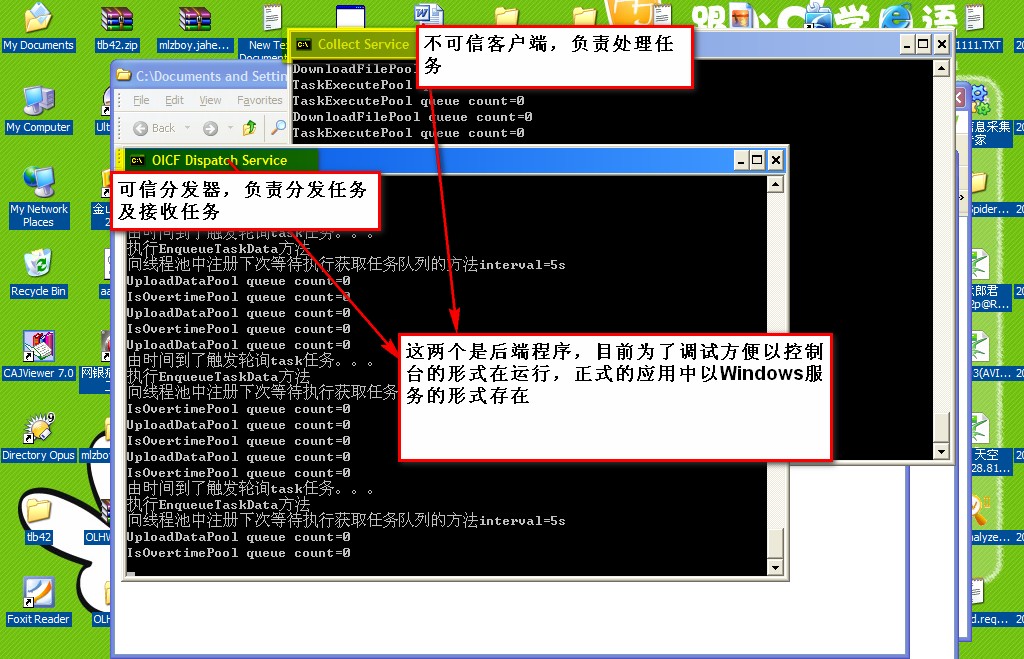
附采集的结果