代价函数
在一开始,我们会完全随机地初始化所有的权重和偏置值。可想而知,这个网络对于给定的训练示例,会表现得非常糟糕。例如输入一个3的图像,理想状态应该是输出层3这个点最亮。
可是实际情况并不是这样。这是就需定义一个代价函数。(吴恩达老师称单个样本上的代价为$Loss function$,称为损失函数 )



接下来就要考虑几万个训练样本中代价的平均值

梯度下降法
还得告诉它,怎么改变这些权重和偏置值,才能有进步。
为了简化问题,我们先不去想一个有13000多个变量的函数,而考虑简单的一元函数,只有一个输入变量,只输出一个数字。学过微积分的都知道,有时你可以直接算出这个最小值,不过函数很复杂的话就不一定能写出,而我们这个超复杂的13000元的代价函数,就更加不可能做到了。
(这里有个问题:神经网络中,为何不直接对损失函数求偏导后令其等于零,求出最有权重,而要使用梯度下降法(迭代)计算权重)?
知乎上对于这个问题的回答:https://www.zhihu.com/question/267021131
这里我主要关注了两点:
- 神经网络的代价函数其实是非凸函数
- 非凸优化问题被认为是非常难求解的,因为可行域集合可能存在无数个局部最优点,通常求解全局最优的算法复杂度是指数级的(NP难)。
一个灵活的技巧是:以下图为例,先随便挑一个输入值,找到函数在这里的斜率,斜率为正就向左走,斜率为负就向右走,你就会逼近函数的某个局部最小值。(其实是沿着负梯度方向,函数减少的最快)
但由于不知道一开始输入值在哪里,最后你可能会落到许多不同的坑里,而且无法保证你落到的局部最小值就是代价函数的全局最小值。
值得一提的是,如果每步的步长与斜率成比例,那么在最小值附近斜率会越来越平缓,每步会越来越小,这样可以防止调过头。

当我们提到让网络学习,实质上就是让代价函数的值最小。代价函数有必要是平滑的,这样我们才可以挪动以找到全局最小值,这也就是为什么人工神经元的激活值是连续的。
没道理的回答
当输入是一个噪音图片时,神经网络却仍很自信的把它识别成一个数字。换句话说,即使网络学会了如何识别数字,但是它却不会自己写数字。
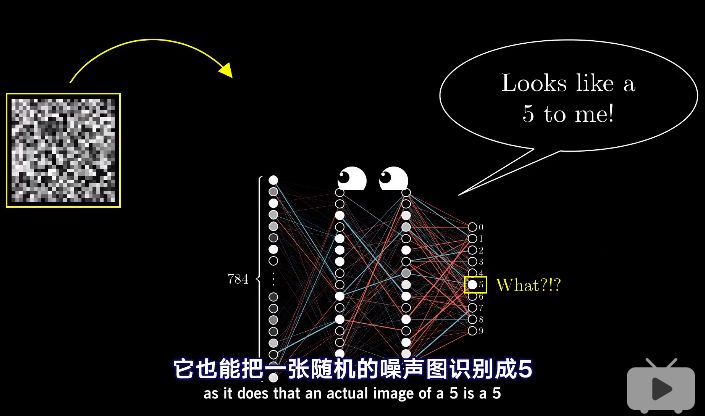
究其原因,因为网络的训练被限制在很小的框架内,在网络的世界里,整个宇宙都是由小网格内清晰的静止的手写数字构成的。
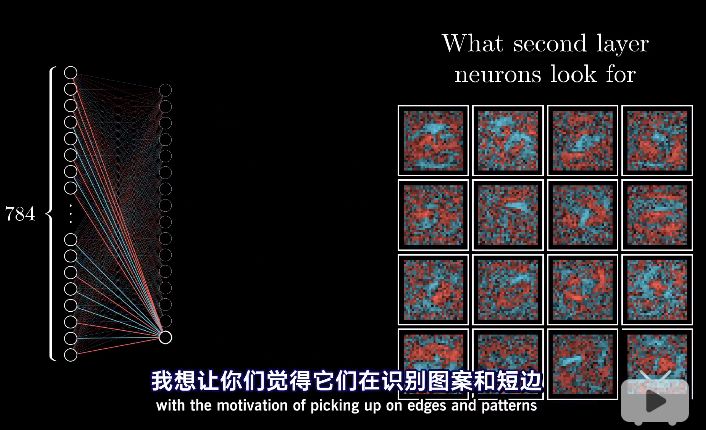
最后,作者给出上期问题的答案:神经元根本就没有取去识别图案和短边!
参考链接: