有点激动,啊啊啊想明白了attention的含义,然后连着的一大片都能看懂了,茅塞顿开的感觉真好
1. 理解Self-Attention
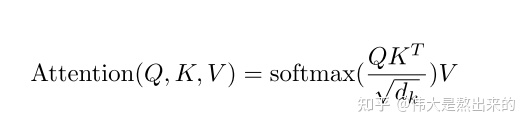
Q, K, V是啥啊???
我们先看 $Softmax(XX^T)X$的含义
线性代数的知识:
X乘X的转置,不就是当前行与其他每一行求內积吗?
內积有什么含义?$a\cdot b = |a||b|cos\theta $,假设a,b的模是常数,內积就表示夹角,夹角表示相似度
所以$XX^T$得到的是一个相似度矩阵,Softmax再做一个归一化
$Softmax(XX^T)X$,再乘一个X有什么含义呢?就是将系数加到每个行向量上再求和得到新的每个行向量
......总之
$XX^T$ 计算每个词向量与其他向量的相似度;再乘X,将相似度加权到每个向量,得到加权后的词向量,也就是attention之后的词向量

而Q, K, V都是X*W 形式,其实就是X,W只是为了增加拟合度的吧(可能有其他目的但在这个不care
还有一点:
打乱每个词向量的顺序,得到的attention词向量还是一样的,顺序应该不一样了吧?
2.普通的Attention
Attention是一种广泛的思想(机制)
Attention机制模型:
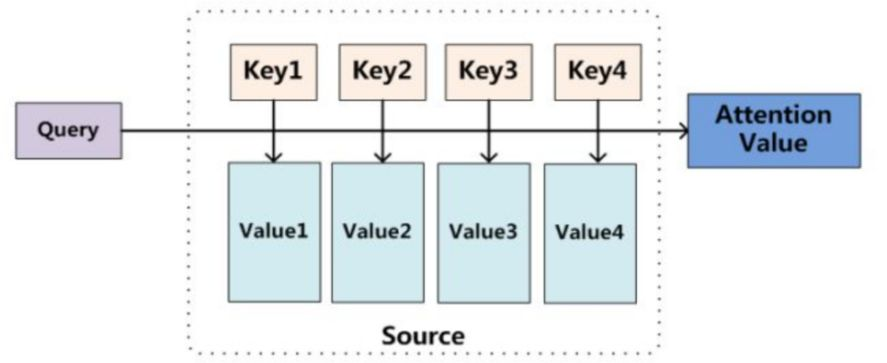
不管具体的计算时,就是:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和
而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理
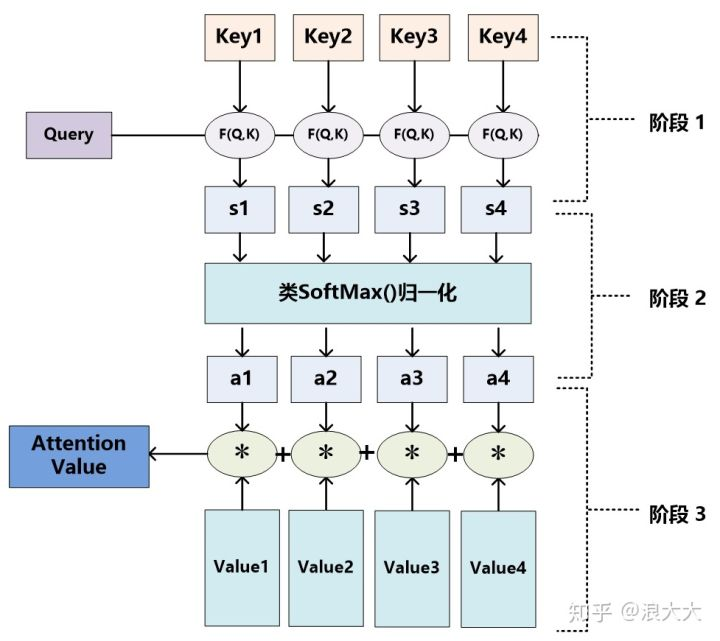
(第一步)计算(Query, Keyi)的相关性有很多方式,常见的有:向量的点积、向量的夹角或引入额外的神经网络来计算相似度

(第二步)一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重

(第三步)$ai$ 即为 $Valuei$ 对应的权重系数,然后进行加权求和即可得到Attention数值
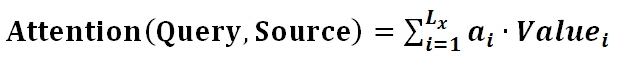
通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
3.早期机器翻译中Attention机制与RNN的结合
Attention机制详解(一)_Seq2Seq中的Attention

这些hi组成一个向量,就相当于self-attention中的X向量,hi相当于矩阵X中的一行。具体的,就是先计算hi之间的相似度,再对相似度归一化,在加权求和得到每个新的hi,也就是attention之后的hi
4.理解Transformer
Attention机制详解(二)_Self-Attention与Transformer
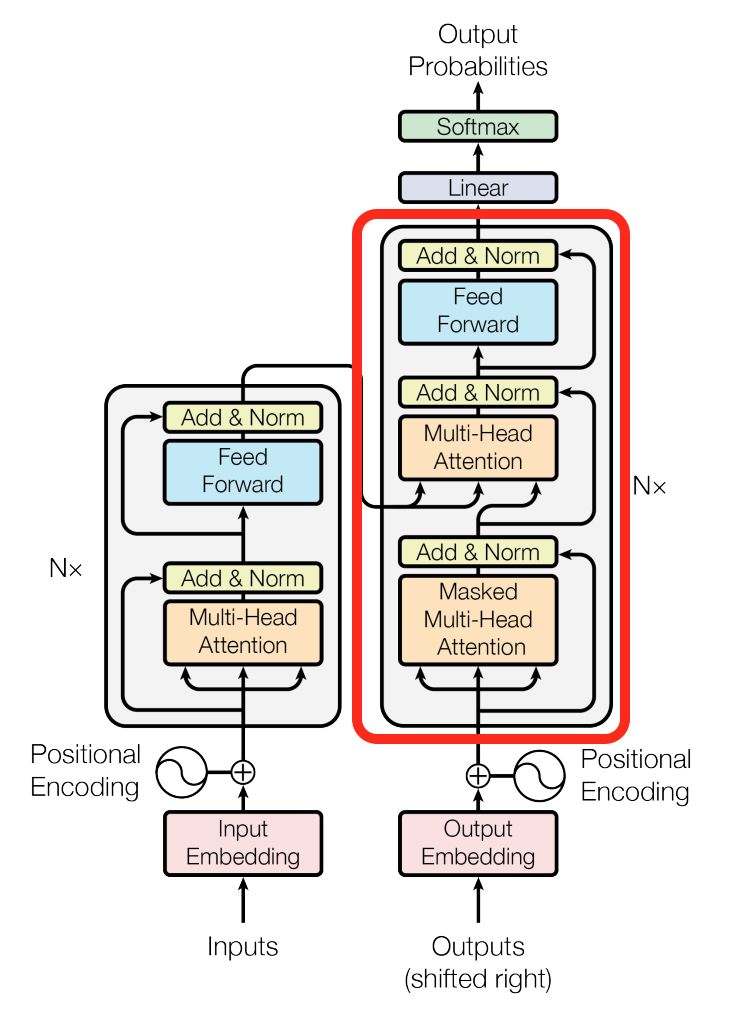
和Seq2Seq一样的,还是Encoder-Decoder结构
Transformer的思路是:在Decoder阶段,不用RNN decoder去获得hi数组,而是对input求attention得到embedding,$embedding_i$代替$h_i$。感觉就是拥有改良后的embedding(也是实际正确的向量表示),就可以为所欲为了
5.Transformer在CV中的应用: ViT
"未来"的经典之作ViT:transformer is all you need!
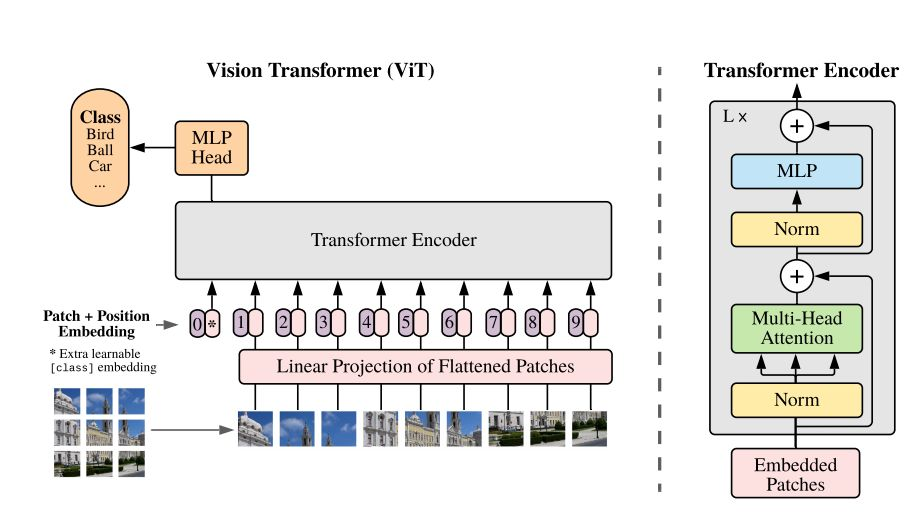
ViT的思路很简单:直接把图像分成固定大小的patchs,然后通过线性变换得到patch embedding,这就类比NLP的words和word embedding,由于transformer的输入就是a sequence of token embeddings,所以将图像的patch embeddings送入transformer后就能够进行特征提取从而分类了。ViT模型原理如上图所示,其实ViT模型只是用了transformer的Encoder来提取特征,然后就能用来做分类、识别等各种任务了
6.Hierarchical ViT: Swin Transformer
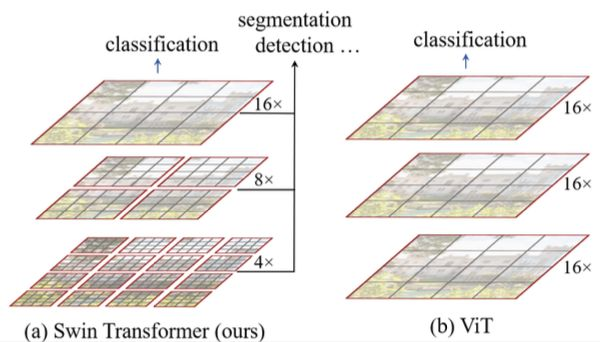
Transformer的确把CNN的活干了,但Self-Attention的计算复杂性一直没解决(其他没啥好解决的,n的元素两两匹配本来就需要$O(n^2)$......)
Self-Attention对于N个token需要计算$N^2$个相互关系矩阵,不行...慢了。
因此我们提出层次模型, 分组。假设每个n个token,有$N/n$组,复杂度就降为$O(N*n)$
论文中n=4,也就是每次只计算相邻4块的相似度
7.linear projection与卷积
为什么VIT模型使用卷积来实现linear projection?
pure transformer,在nlp中input转换成attention embedding,cv中类似,给图像切片再线性映射得到一个个embedding
其实将patch线性变换,本质是一种特殊的卷积。kernek_size和stride都为patch size。因此还不如多卷积几次,stride小一点,效果好。