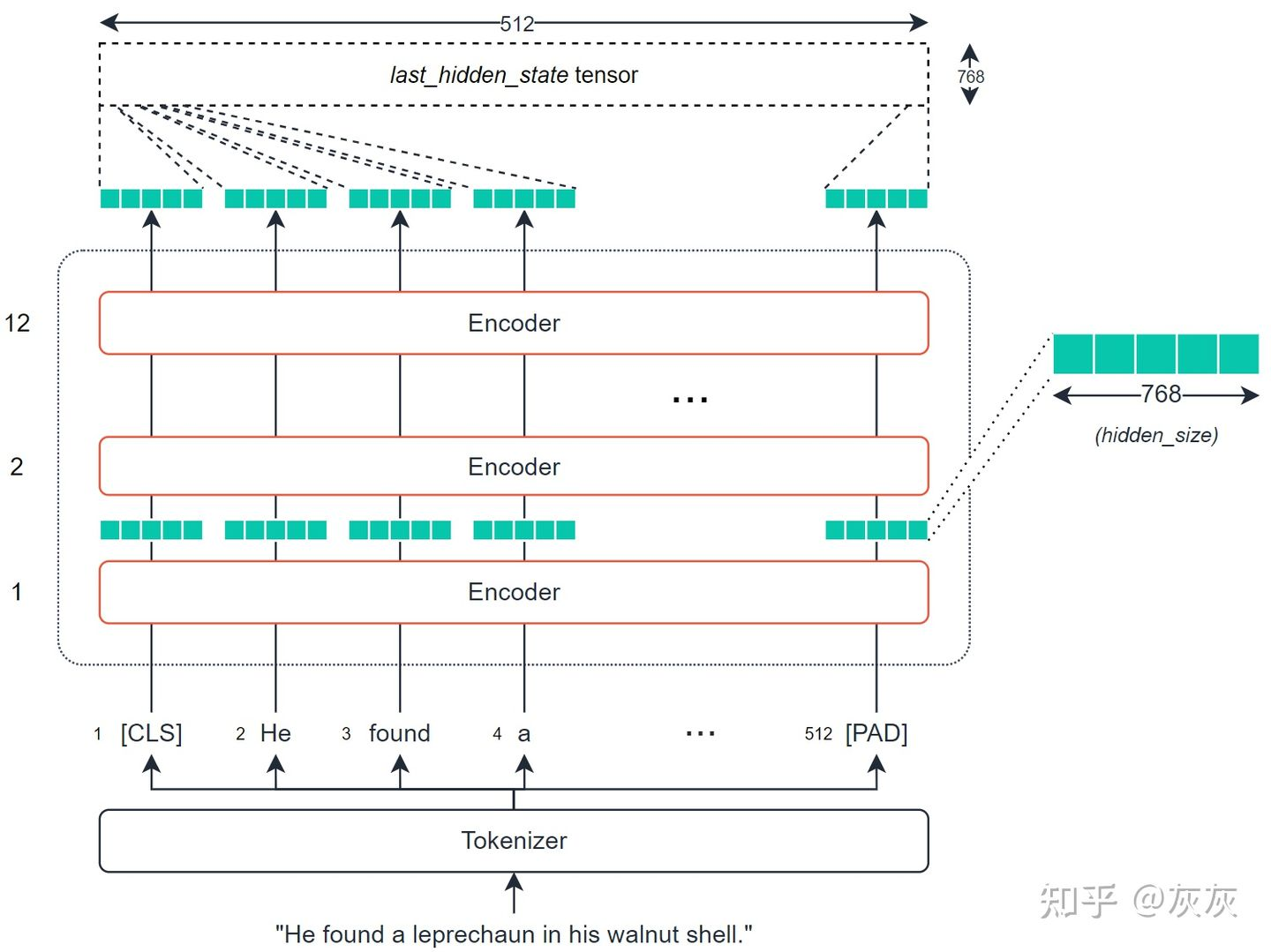
视频1 https://www.youtube.com/watch?v=1_gRK9EIQpc&ab_channel=Hung-yiLee
视频2 https://www.youtube.com/watch?v=gh0hewYkjgo&ab_channel=Hung-yiLee
Bert论文链接 https://arxiv.org/pdf/1810.04805.pdf
1. Bigger Model与Small Model
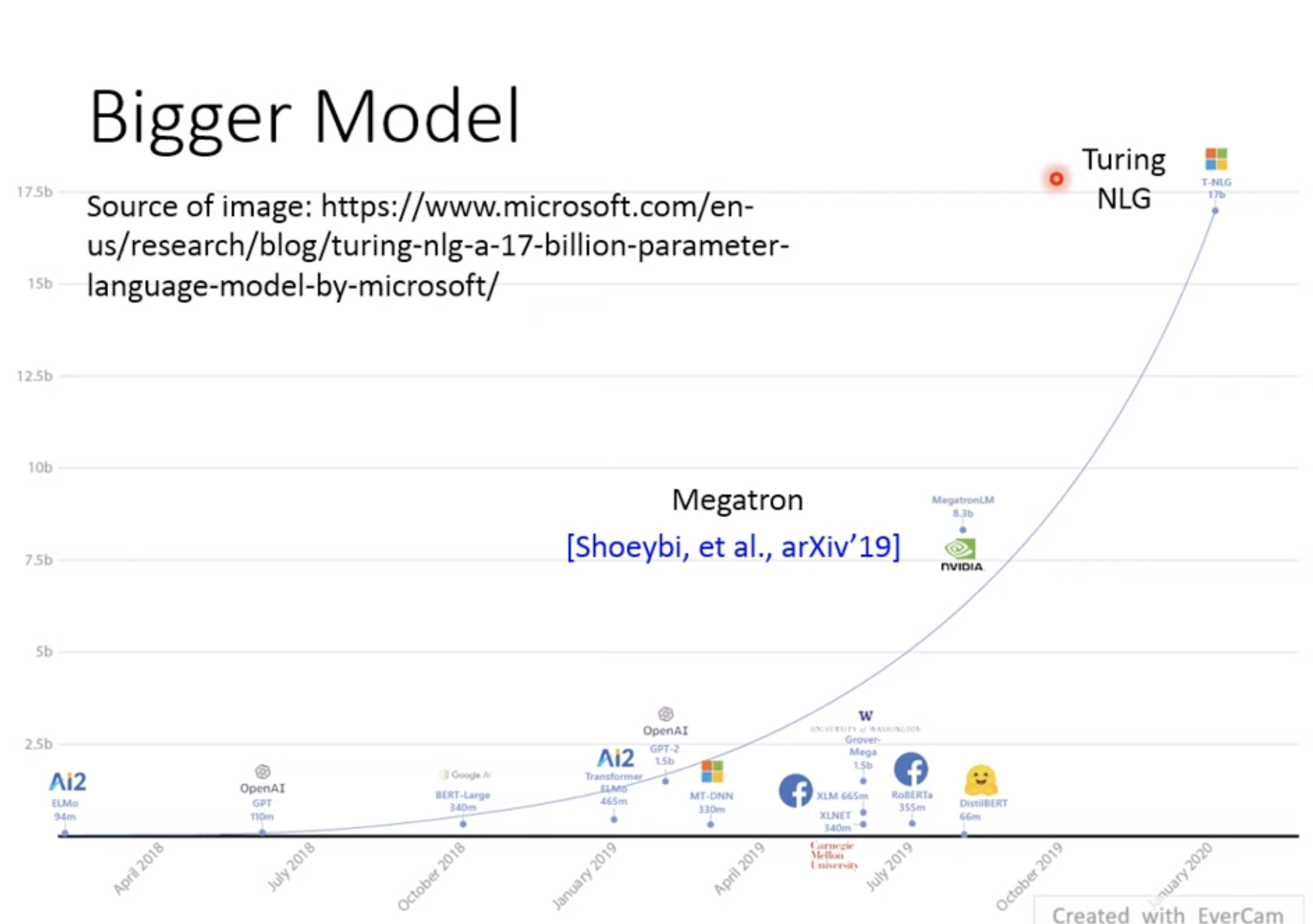
BERT、GPT啥的都太大的,所以看一些穷人使用的Small model

其中最有名的是ALBERT,它的神奇之处是和原BERT结构几乎一样,但是Bert是12层,24层参数不一样,ALBERT每层参数是一样的,而且其performance甚至更好一点
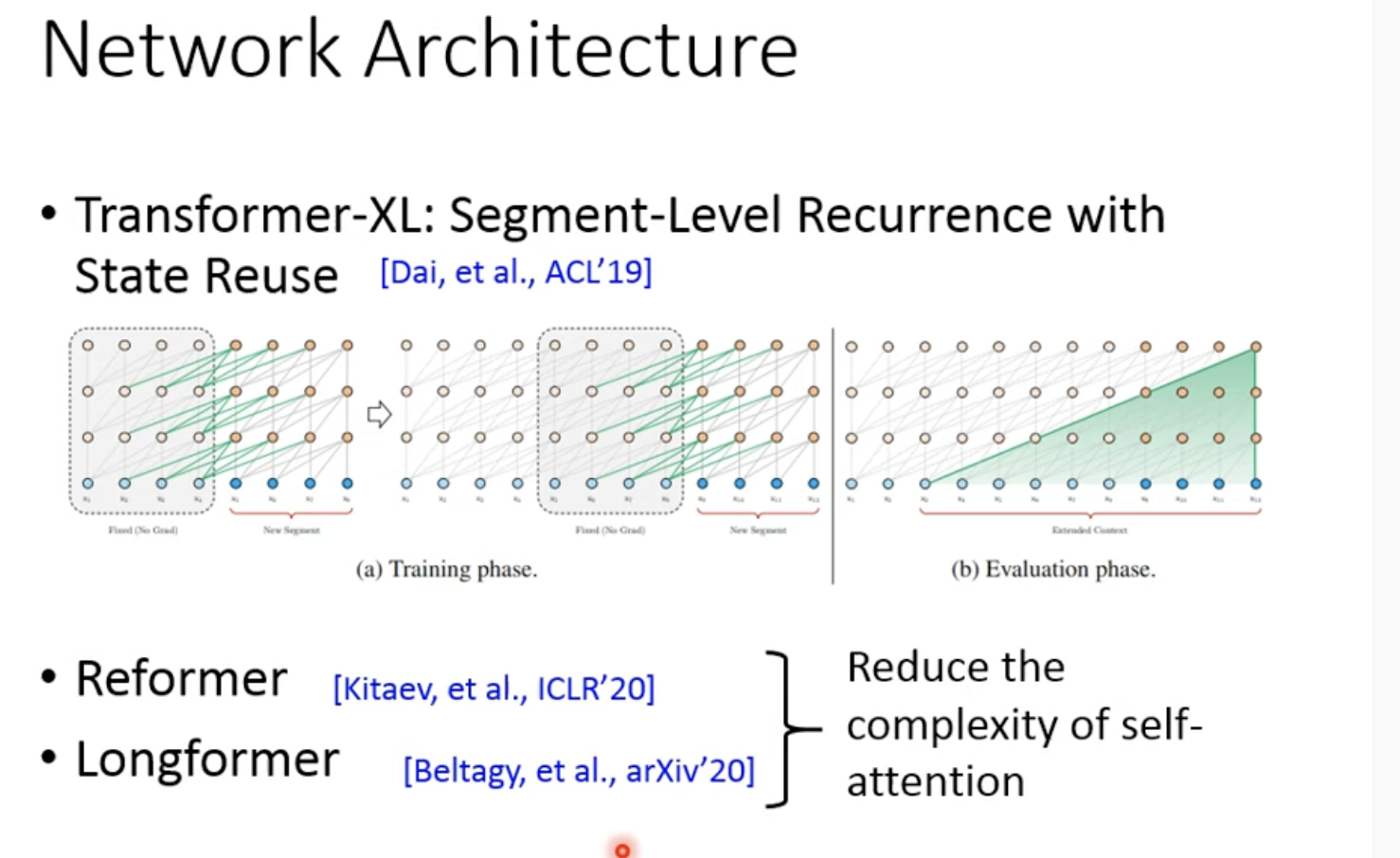
2. 一些Network在Architecture上的创新
这些model的设计目的都是为了让transformer能获得非常长的信息,不只是有一整篇文章,甚至是一整本书的长度,例如Transformer-XL
self-attention的复杂度是O(n^2),n是sequence的长度,所有一些transformer提出来降低复杂度,例如Reformer、Longformer
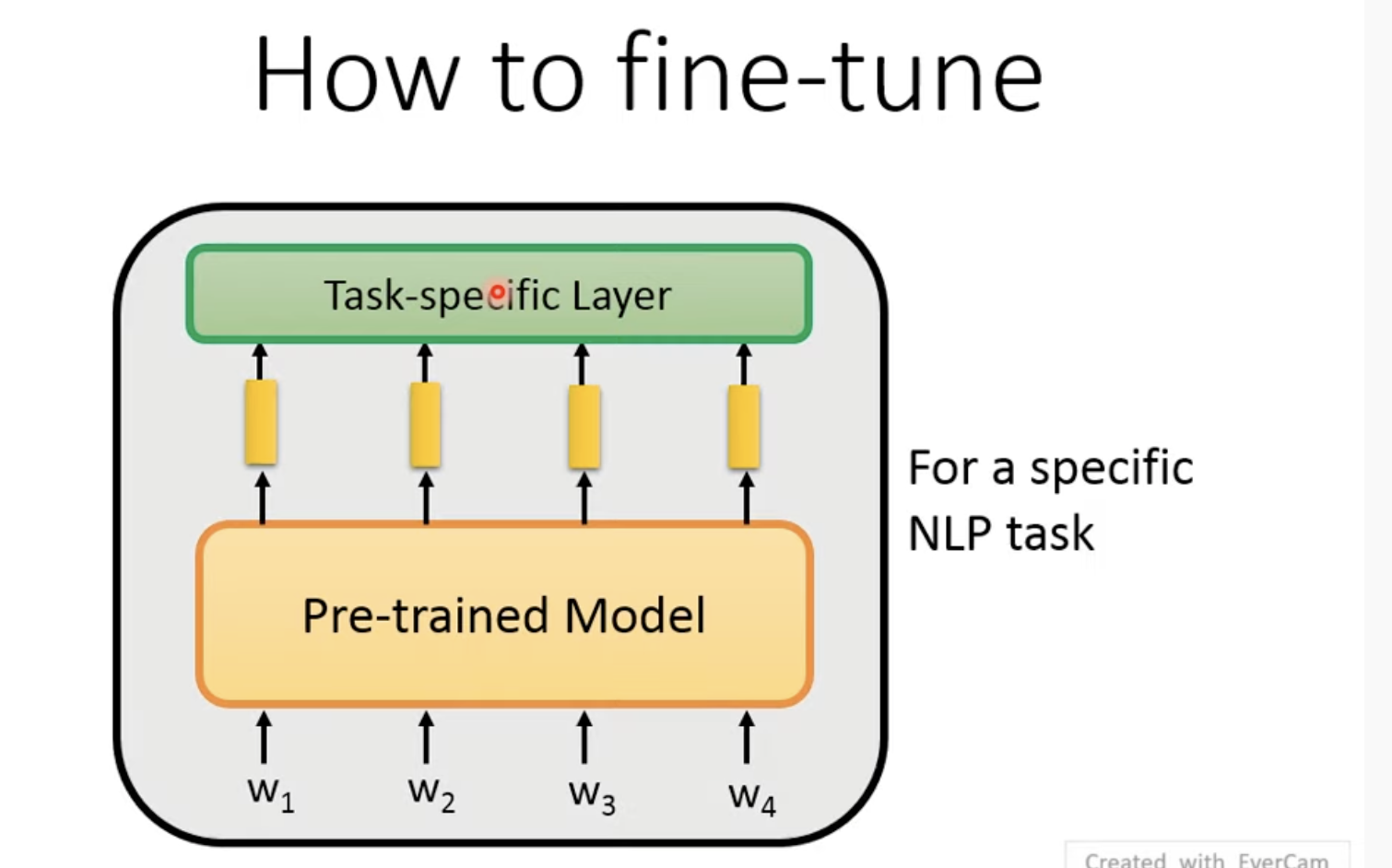
3. How to fine-tune: 怎样进行微调
总的来说就是添加一个Task-specific Layer
针对具体的NLP任务,要如何fine-tune呢?
先看下NLP任务的分类,包括2种输入和4种输出
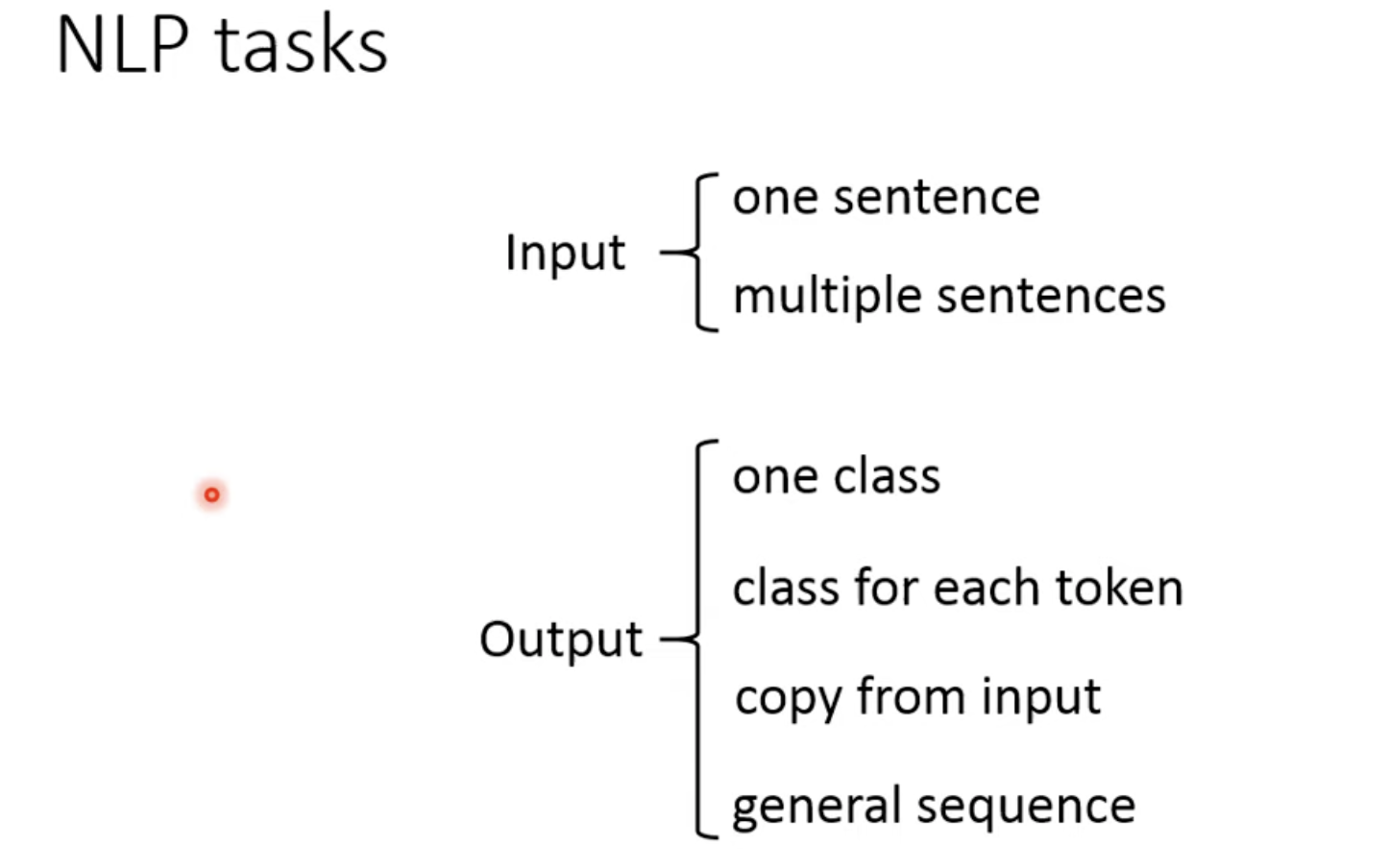
fine-tune时如何处理输入部分?
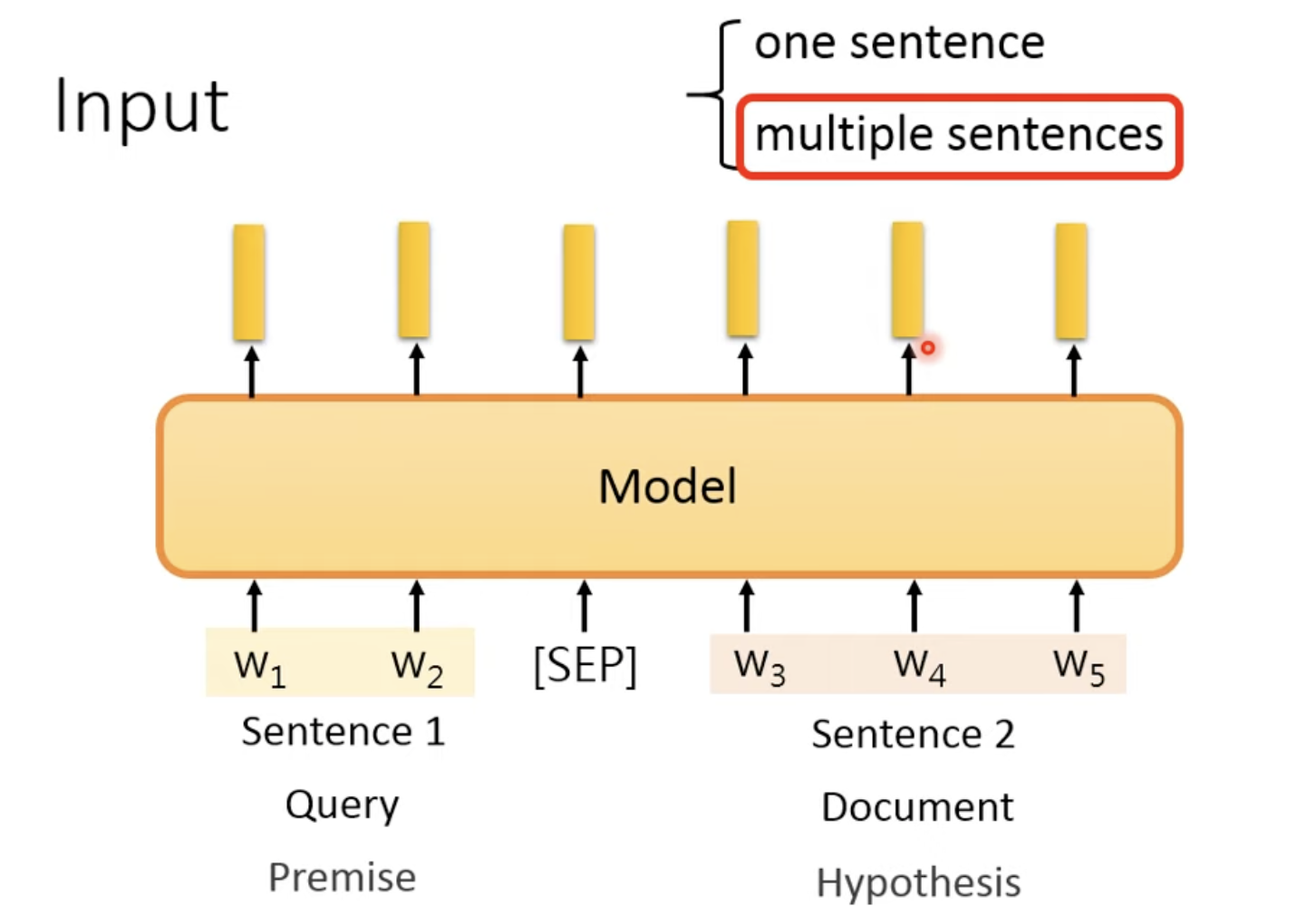
如果是一个sentence,直接扔到pretrain model中就结束了;
如果是多个sentence,例如是2个句子,一个是Query一个是Document
在中间加一个分隔符SEP,pretrain-model能看懂SEP,因为在训练pretrain-model的时候看过SEP(后面讲预训练模型的时候会讲)
fine-tune时如何处理输出部分?
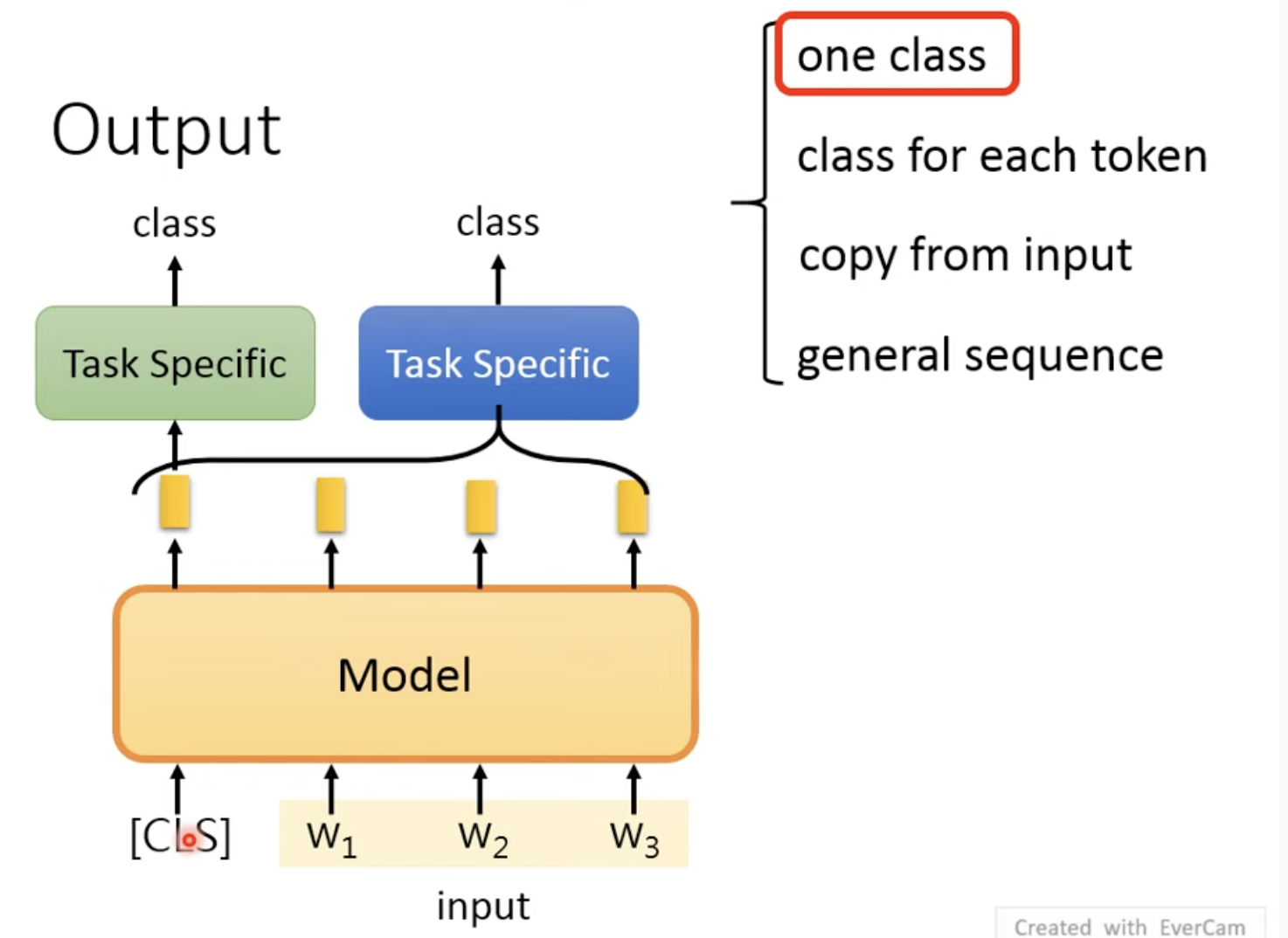
输出有4个可能,第一个是one class: 就是读入一整个句子后输出一个class
原BERT paper中是在输入中加入CLS这个token,其产生的embedding对应class
另一种方法是:不加CLS,将所有output embedding加个Task Specific层,再输出一个class
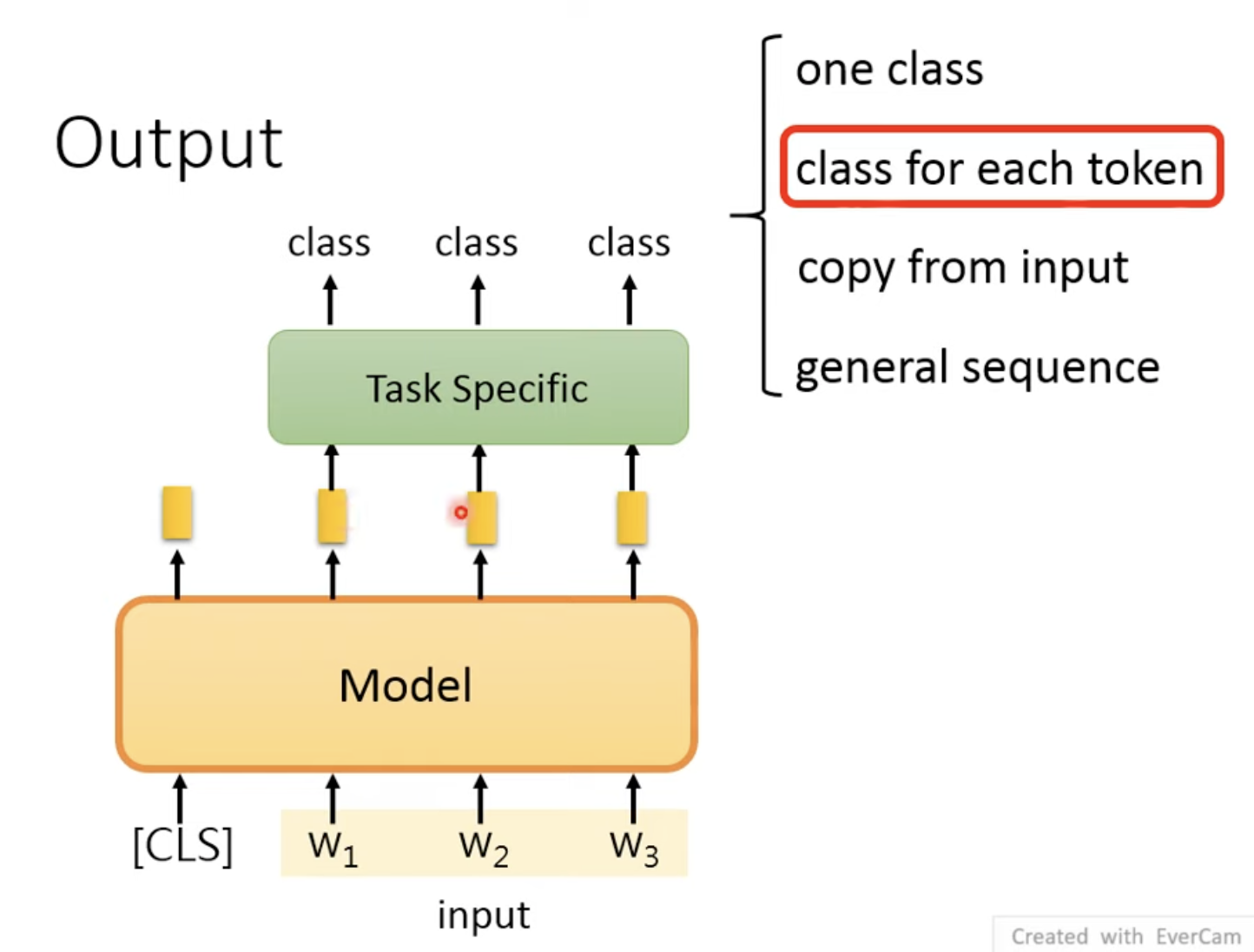
第二种是:class for each token,就是每个token对应一个token
只需要将每个token对应一个embedding,一个embedding对应一个class
例如Task Specific可以是一个LSTM
第三种是:copy from input,例如给定一个Query,在Document中查询,返回Document中的一段话
例如,返回一段话,其在文章的起始位是s,终止位是e

绿色向量与输出的embedding相乘,权重最大的位置得到起始位置;蓝色向量同理,得到终止位置


第四种是:General Sequence,就是输出也是一个Seq
有两种产生Seq的方法:
第一个是参考常见的Encoder-Decoder,但是这样有一个缺点,Decoder是没有pre train的,不太好
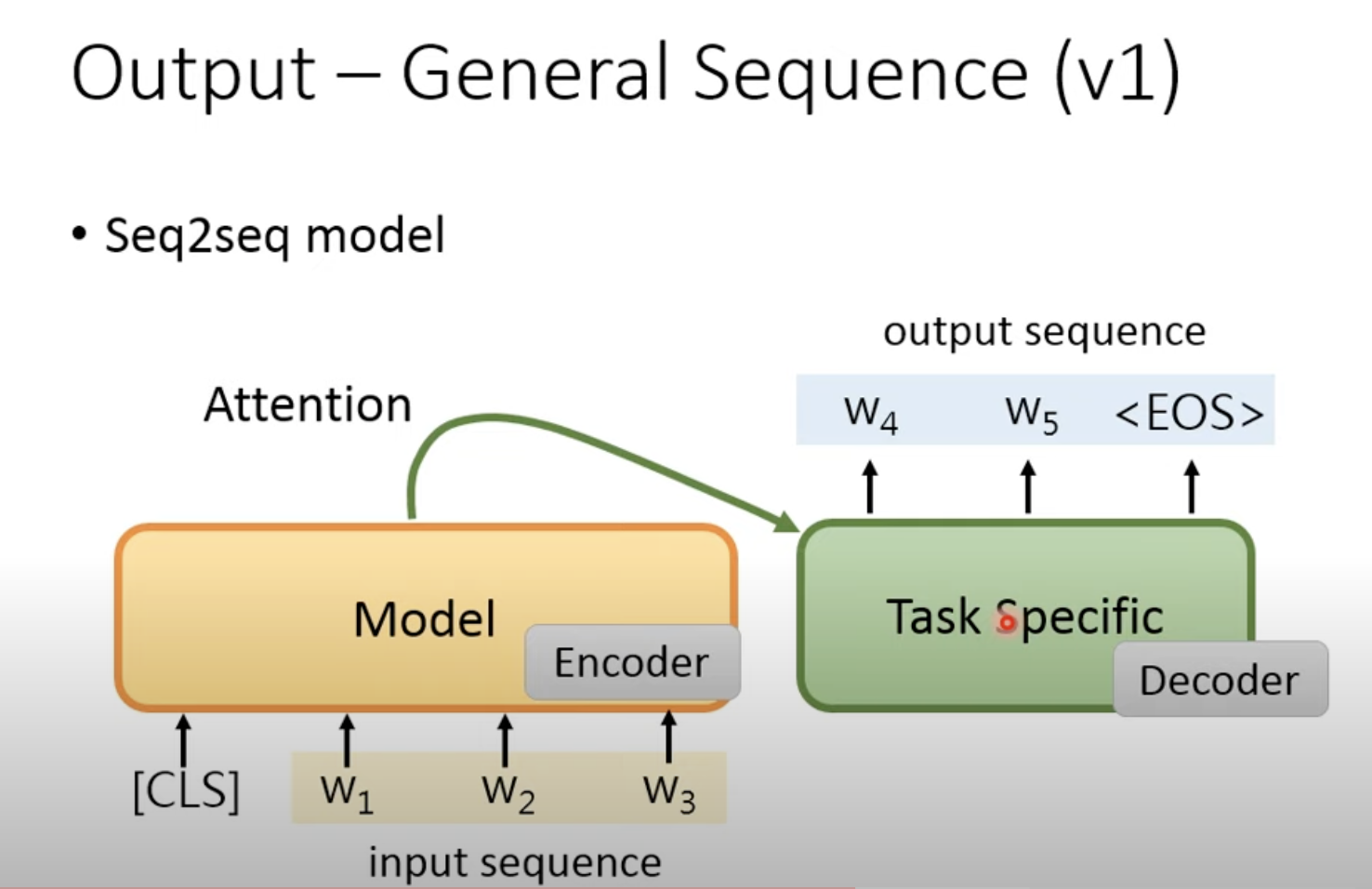
第二个是:将产生的词汇掉回Model中
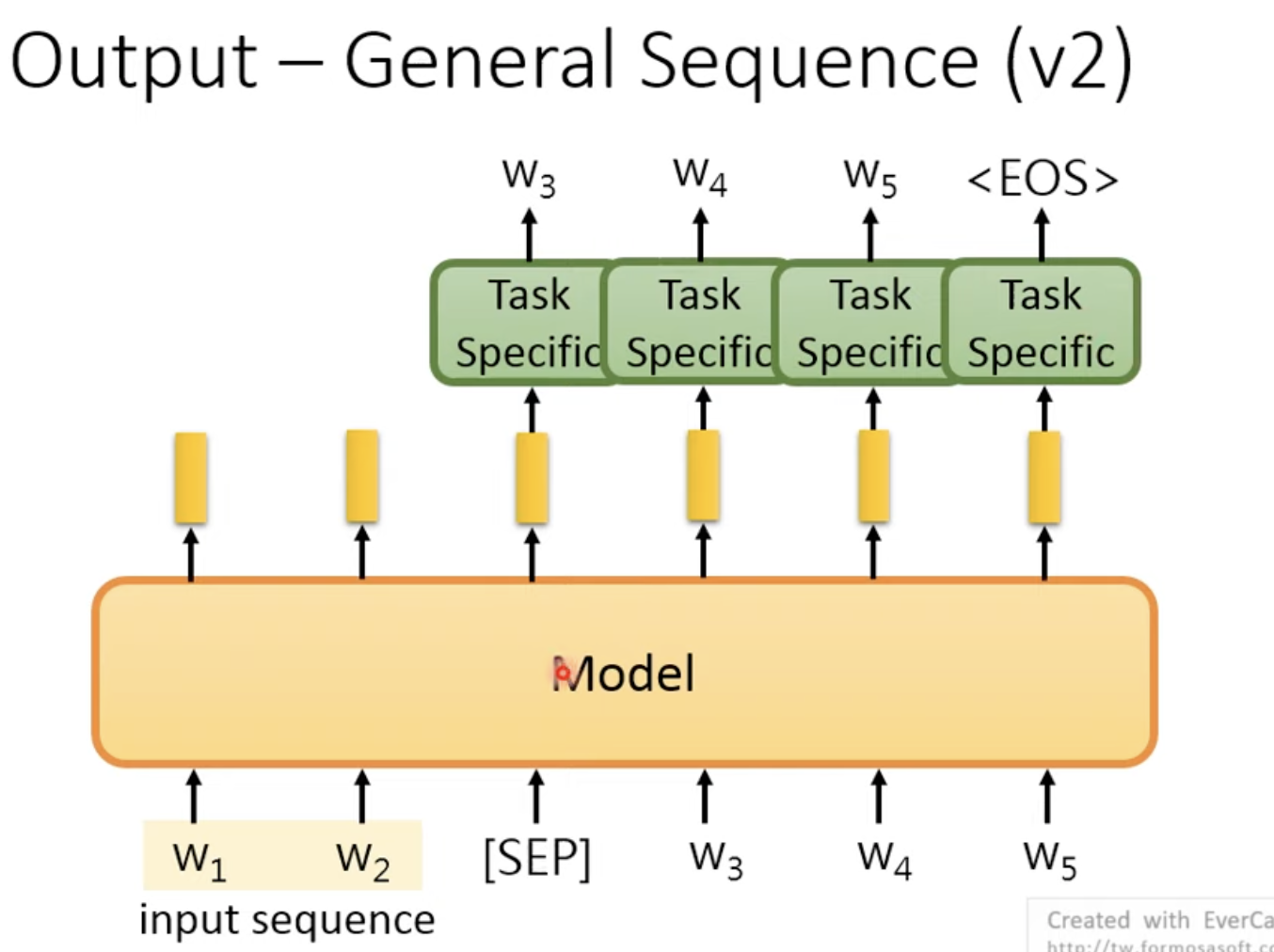
4. How to fine-tune: 微调有哪些方式
一是固定pretrain model,当特征提取器
二是整体再进行训练

如果现在我们是fine tune怎么model会有什么问题?
不同的任务需要存一个model,例如下面3个黄色的model,变成3个不同颜色的model
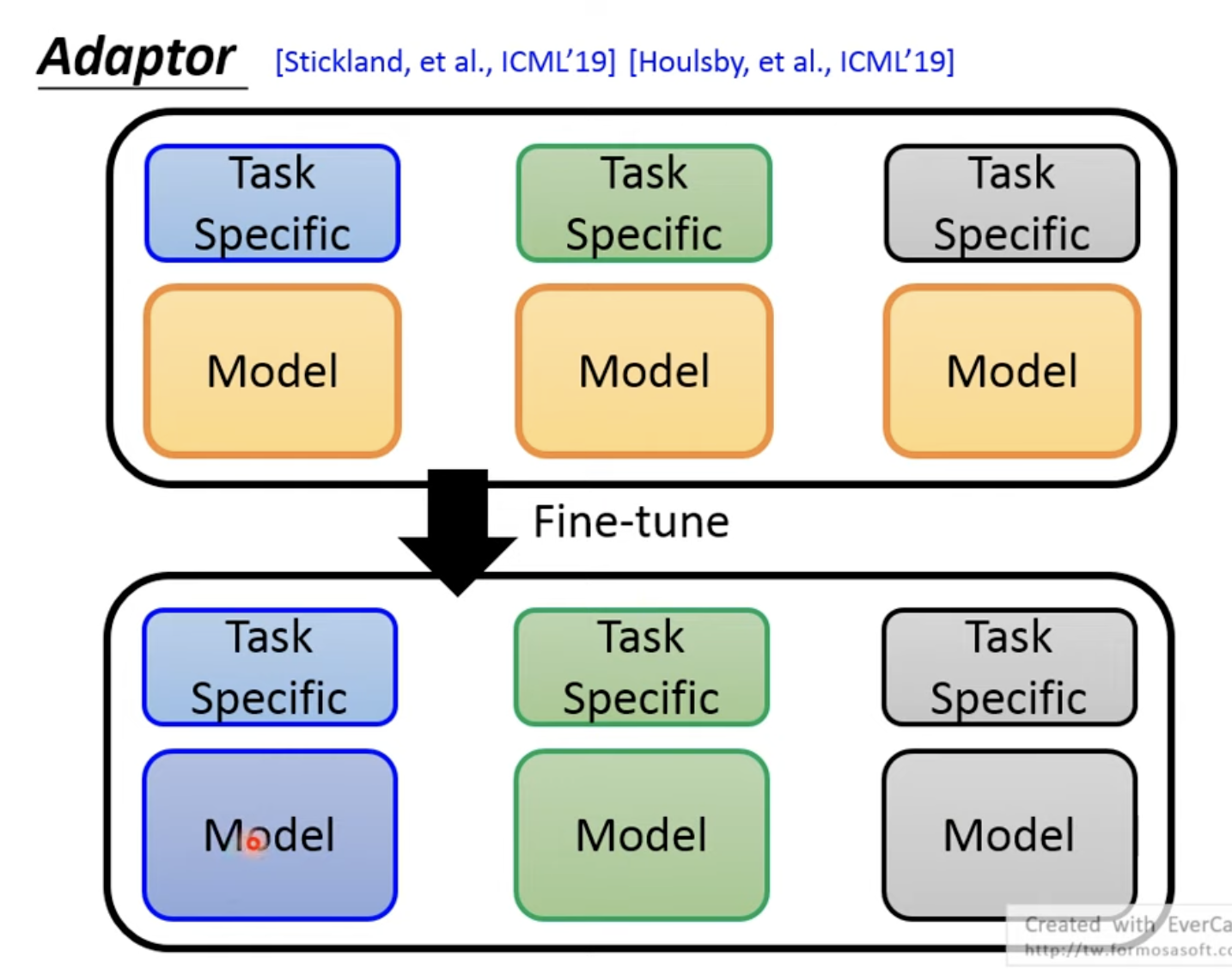
所以,我们可以提取公共部分吗,我们在pretrain model中加入一些layer,这些layer叫做Adaptor
fine tune的时候整体训练,也只要调Adap, modle没变

这样在存模型的时候,也可以只存Apt,不必存一个完整的pretrain Model
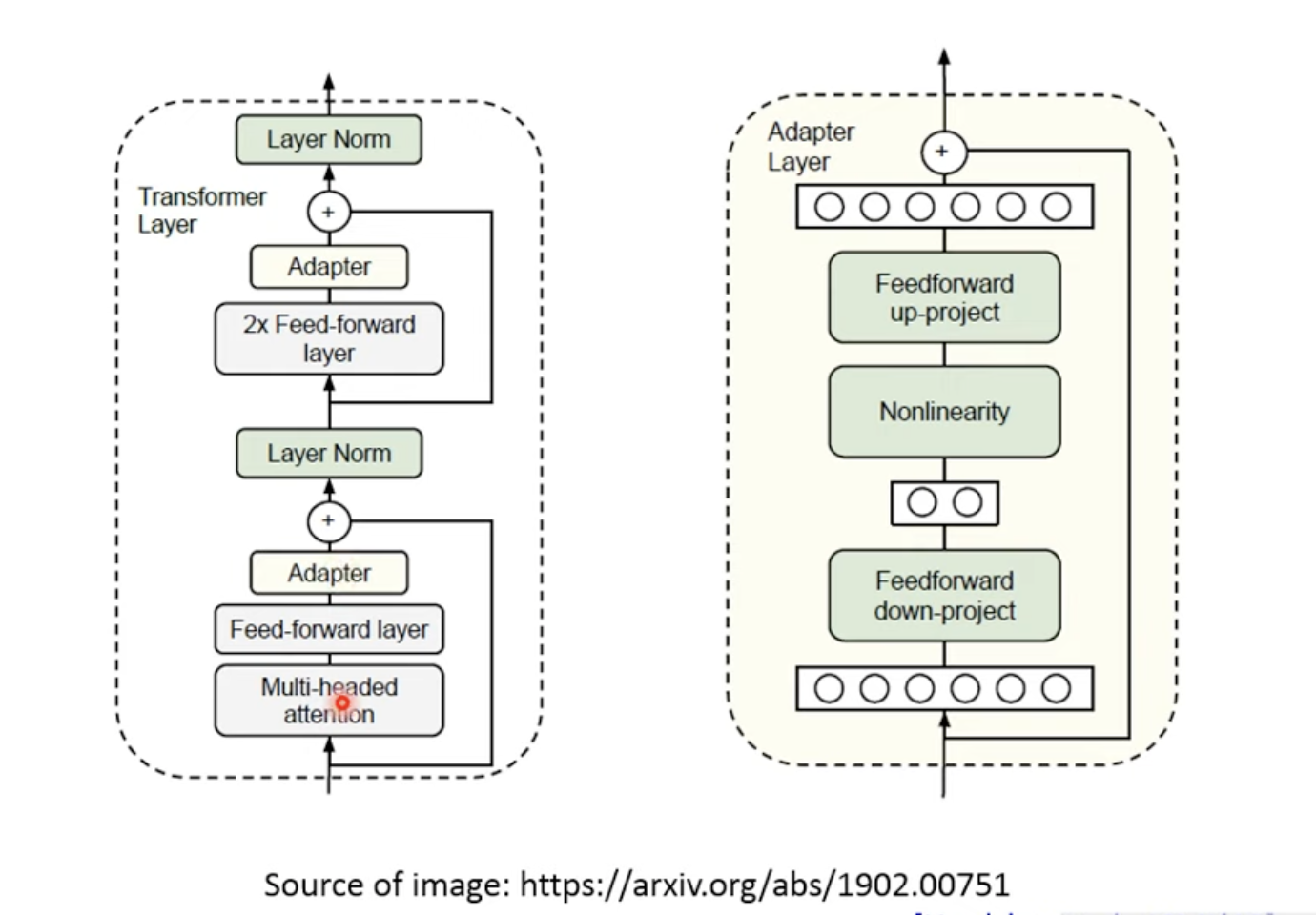
一个Adaptor的例子:
训练的时候只会调整Adap
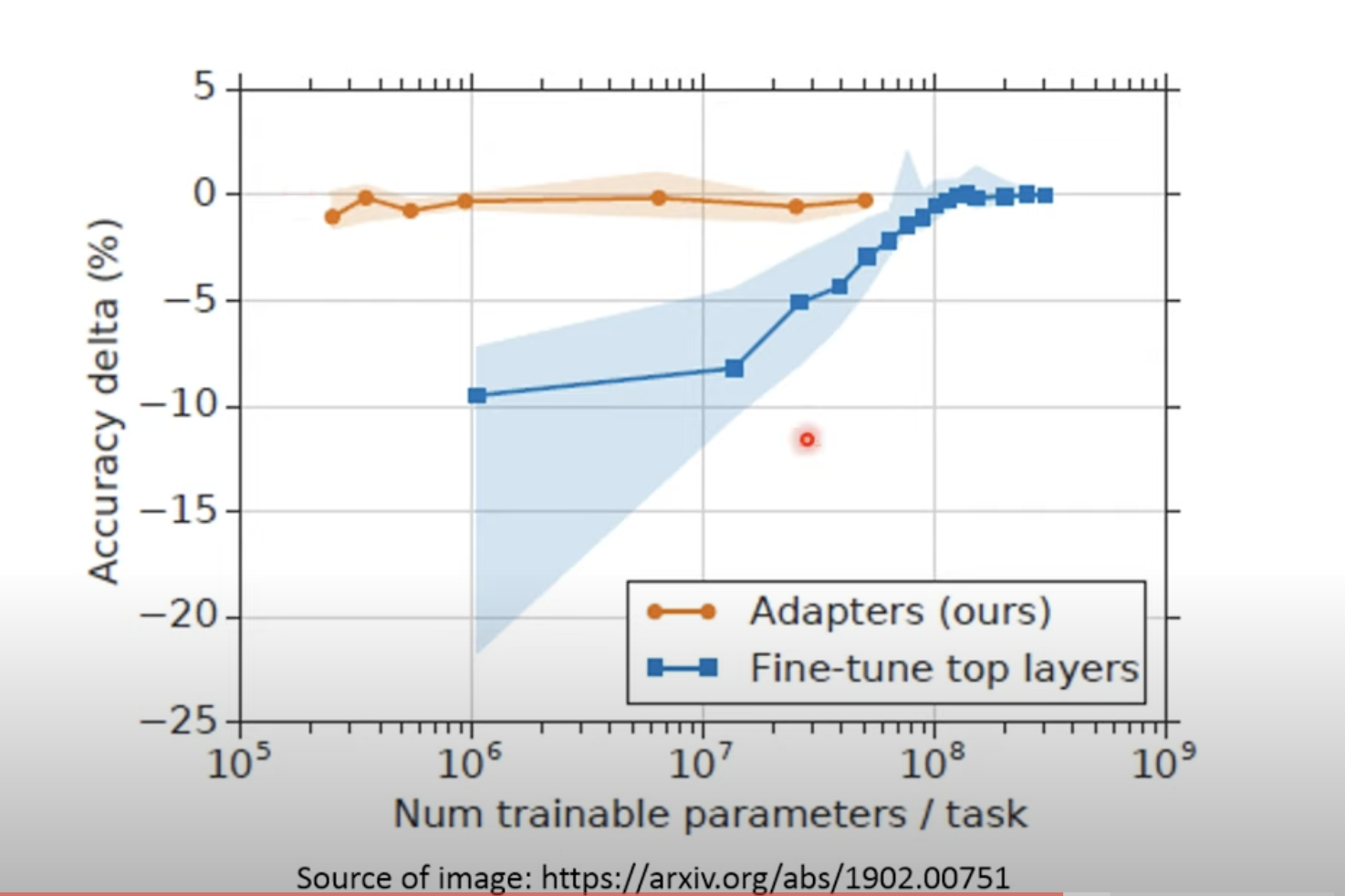
Adap的效果怎么样呢?
水平线0是fine tune整个模型的基准,可见Adap几乎接近训练整个模型
5. 多层layer得到的feature加权:weighted feature
通常是只用最后的输出作embedding,也可以抽取每层的feature,加权得到结合每一层输出的embedding
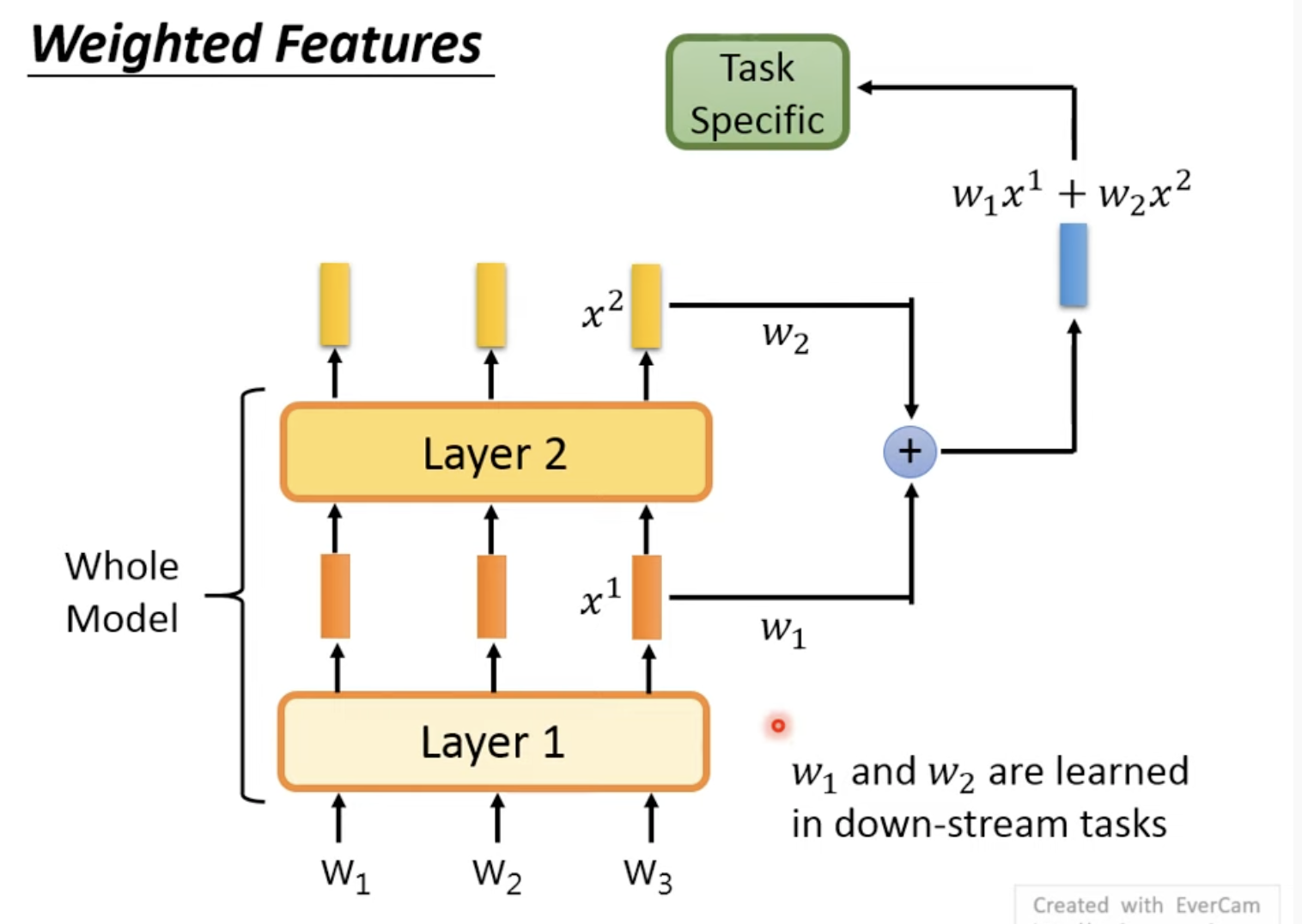
这里w1, w2可以是人工设置,也可以是学习出来的
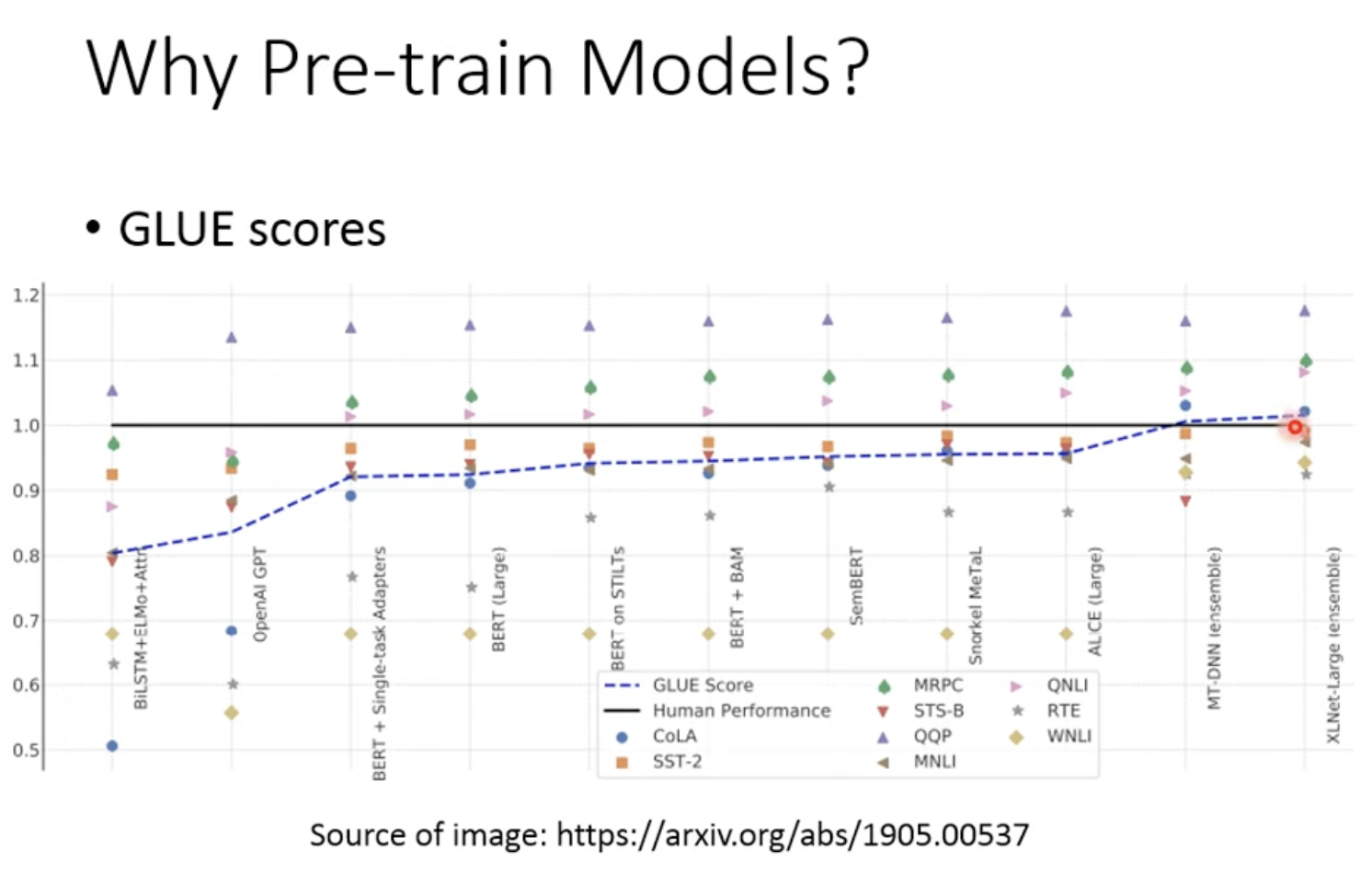
6. 为什么需要Pre-train model?:Why Pre-train Models
有了预训练模型后,GLUE benchmark超过了人类
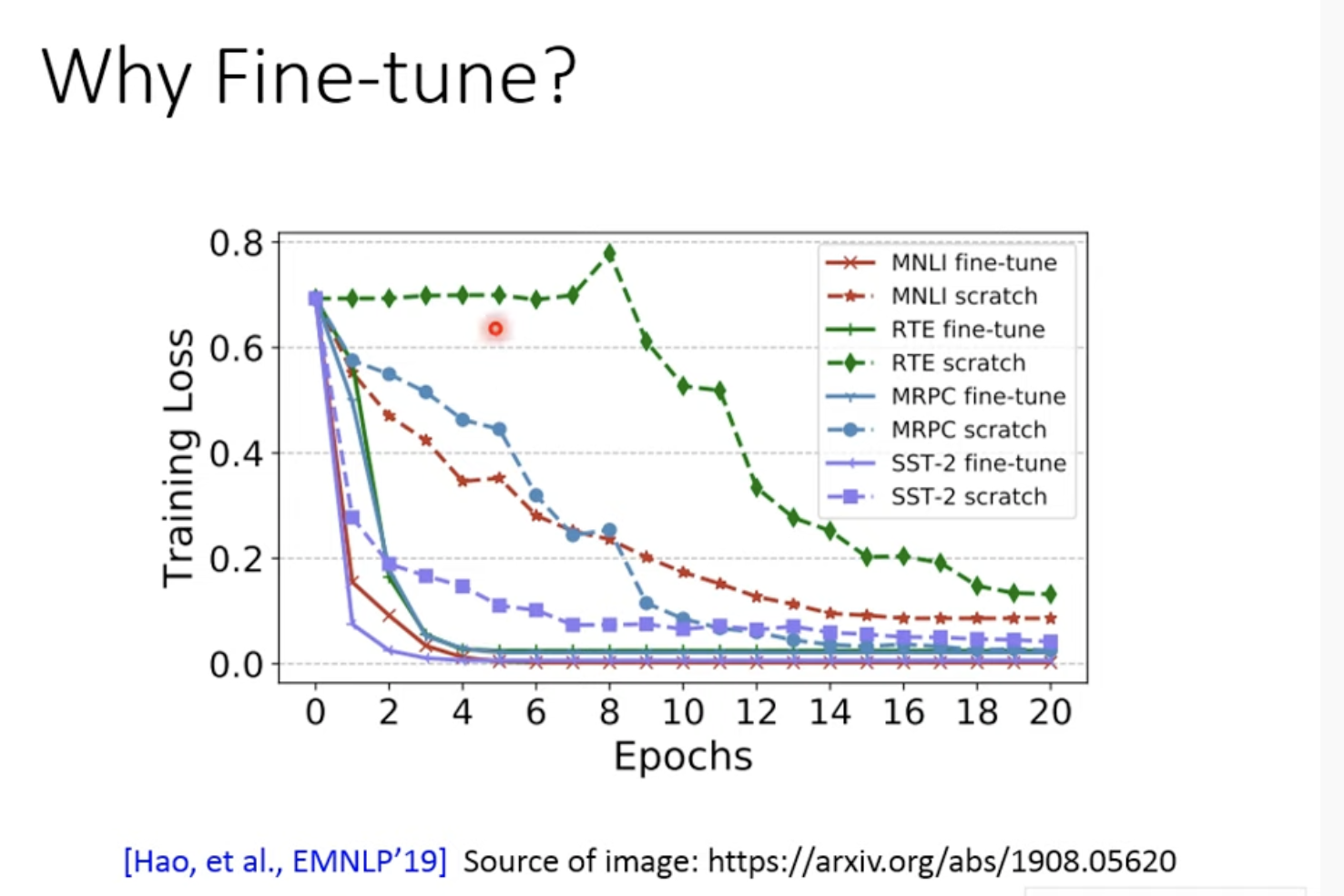
7. 为什么需要微调:Why Fine-tune
虚线是全部自己训练(即参数都是随机开始),实线是采用Pre train, 两个模型的大小是一样的
可以发现实线的loss降得非常快
loss很低并不一定好,可能是overfit(过拟合)呢?我们来看一下Pre train的泛化能力
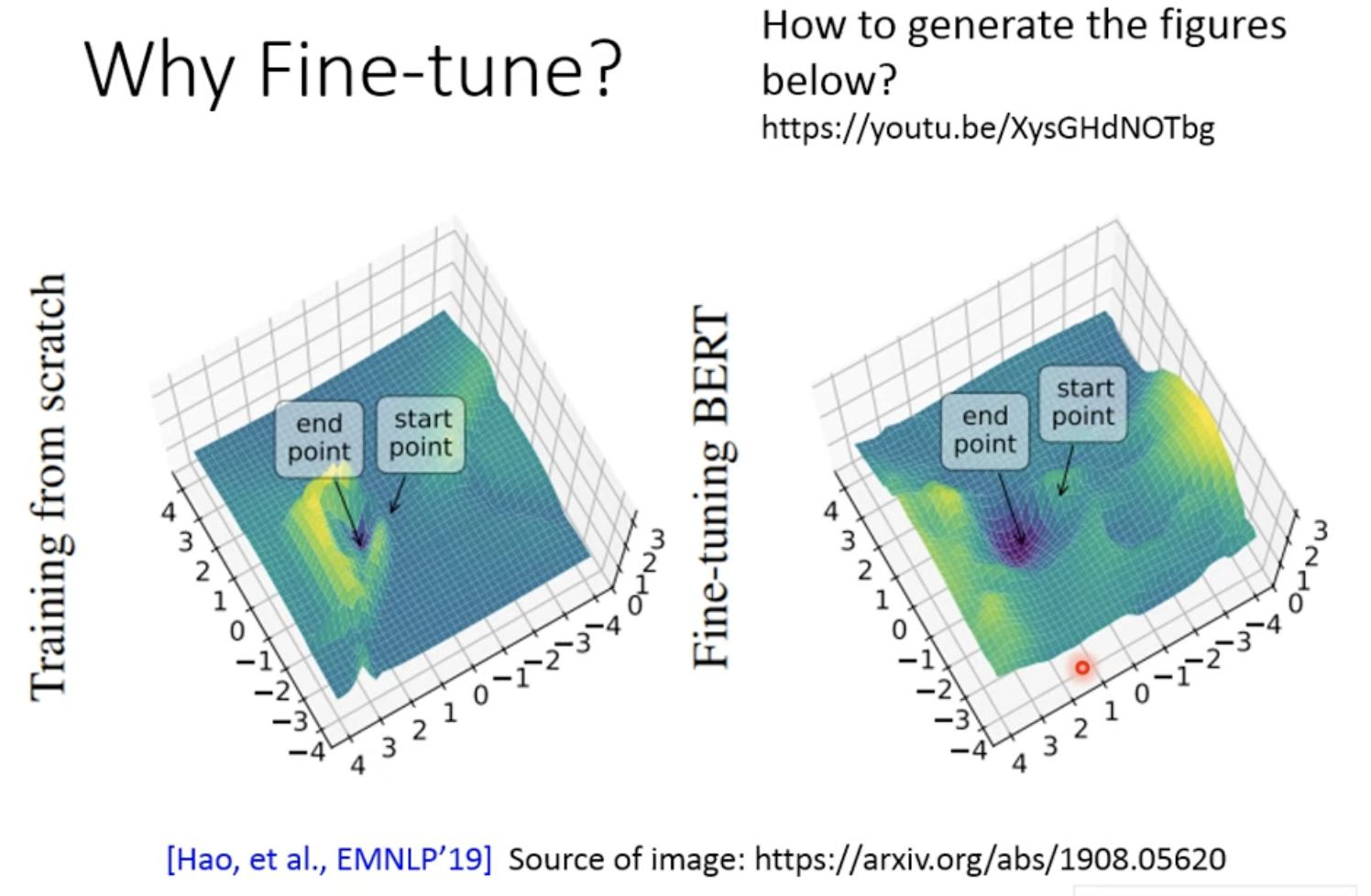
如何分析模型的泛化能力呢?start-point是参数的起始点,end-point是参数训练后的位置。
start-point与end-point的海拔差是能训练的loss,两者的坡度表示泛化能力,如果两点之间越陡峭表示泛化能力越弱,如果越平缓表示表示泛化能力越强
8. Pre train model是怎么训练出来的
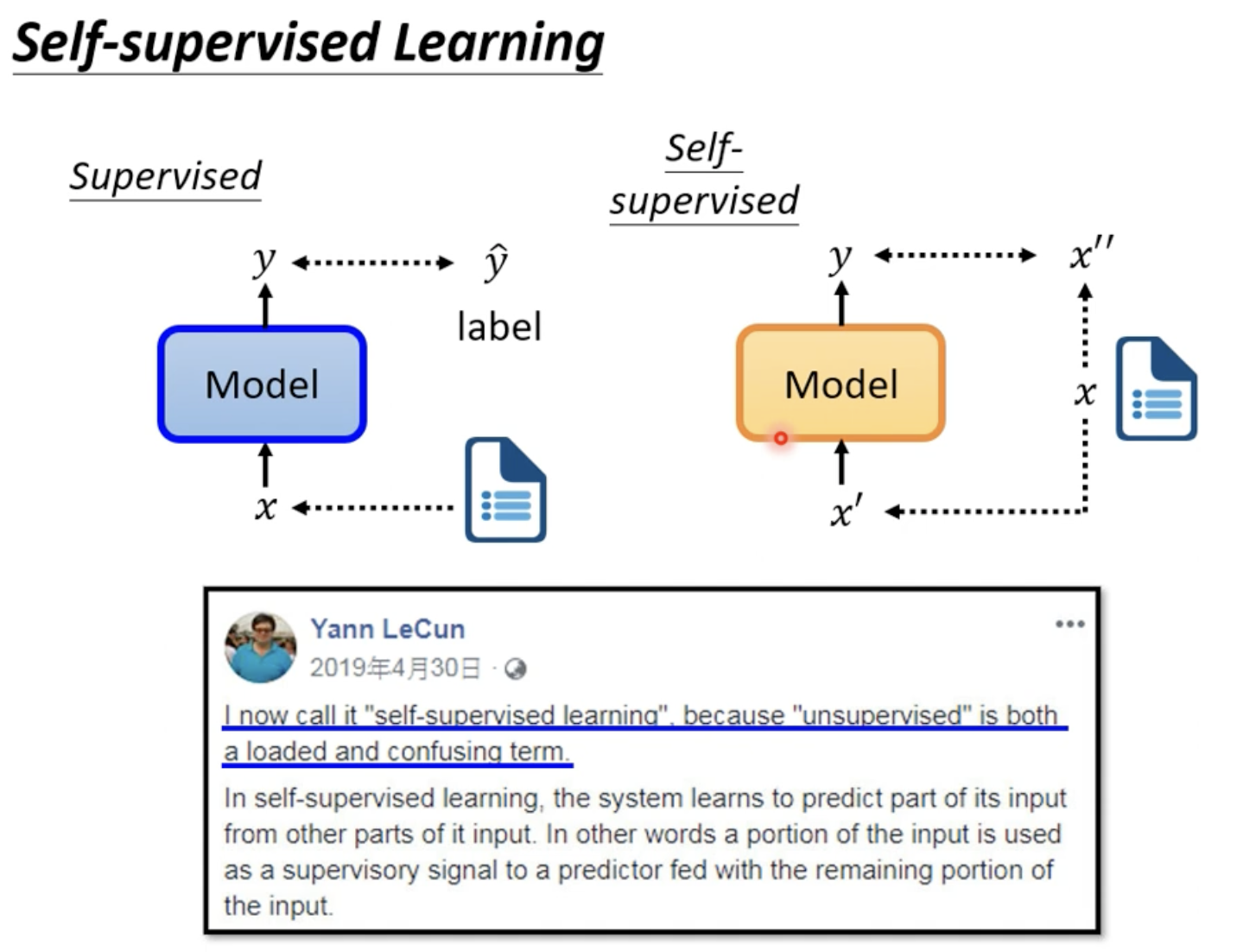
BERT采用的Self-supervised的训练方法,就是在没有label的情况下做supervised
self-supervised没有用到label,我们可称之为unsupervised;unsupervised的范围更大,像CycleGAN也没有用到标签信息,但它只能算作unsupervised而不是self-supervised
要注意的是,下游任务训练的时候是有标签的数据,所以总体而言的大量数据的self-supervised和小量下游数据的supervised
这里self-supervised将x复制了两份, x', x'',后面会具体讲
9. BERT实际上是怎么Self-supervised的?
BERT用了两种训练方法:Masked token prediction和Next sentence prediction
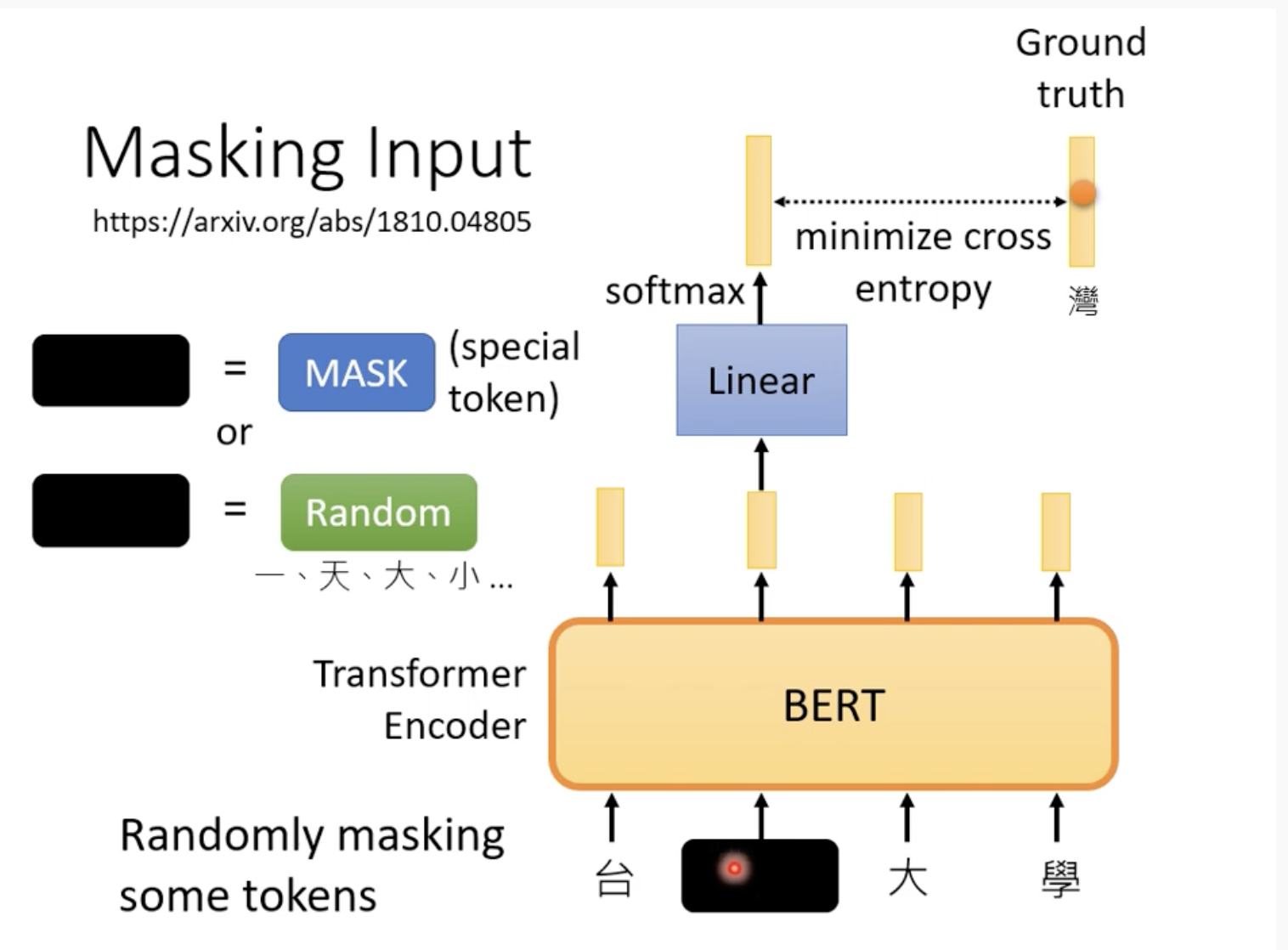
一种是Mask input, mask的时候也分两种,先随机找一个位置,要么把它直接mask,要么把它替换成其他单词,
怎么计算loss呢?把mask位输出的vector与目标单词的vector计算cross entropy(因为是我们自己mask的,我们当然知道被mask的是什么单词)
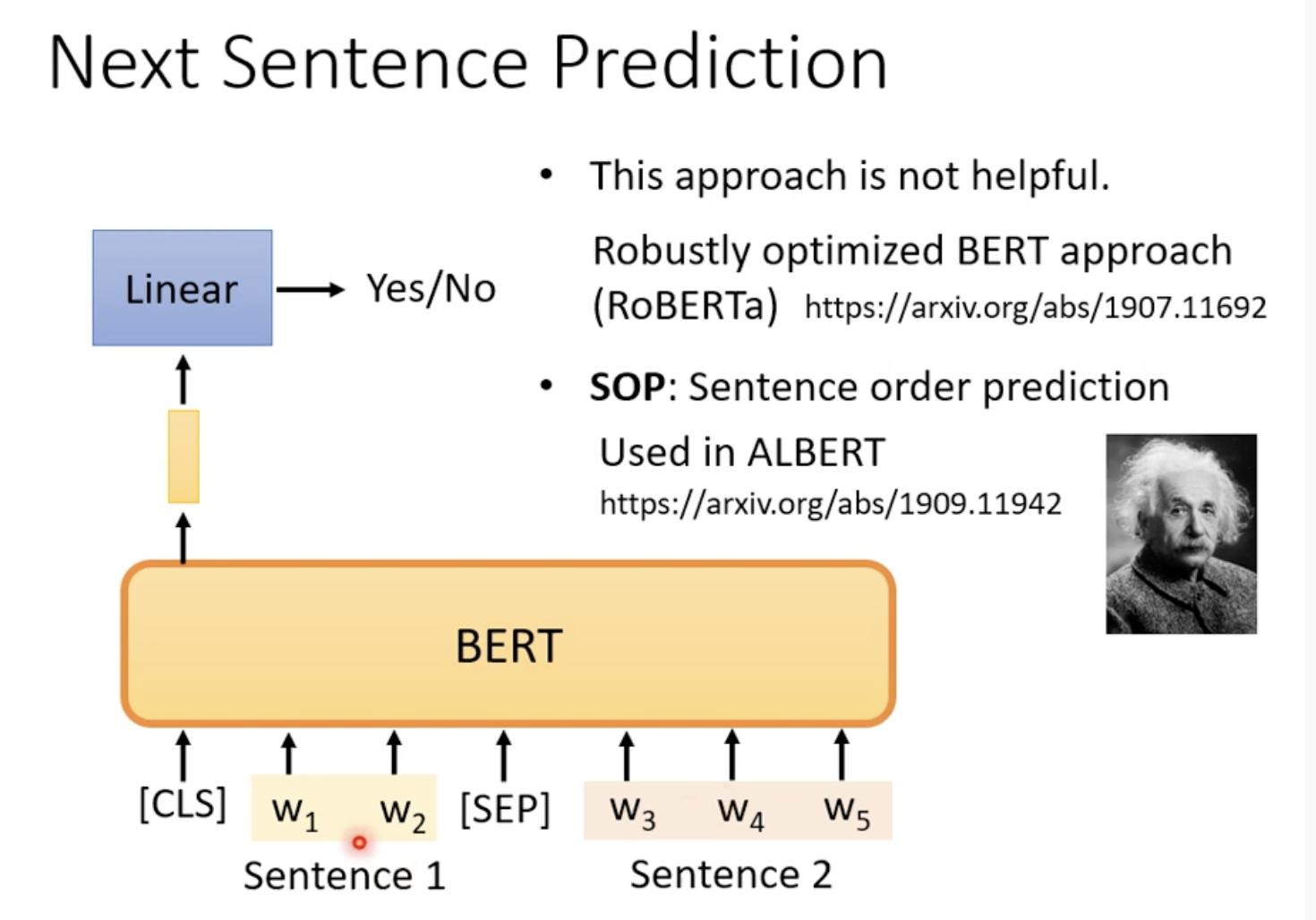
另一种是Next sentence Prediction,就是给定两个句子,问你其中一个句子是不是另一个句子的下一句,如果是返回True
跟前面讲的fine-tune方法中的一个一样,在输入添加CLS,只关注CLS对应输出的vector,再接一个线性层得到True/False
但是研究发现这个训练策略不太有用(因为判断是不是下个句子可能对BERT来说太简单了),RoBERTa就指出了这个缺陷,例如在ALBERT中换用了SOP
神奇之处是虽然BERT是在这两个任务上训练的,但是它可以在一些列下游任务上直接使用,可能是和这两个任务完全没有关系的任务