下载一首英文的歌词或文章
将所有,.?!’:等分隔符全部替换为空格
将所有大写转换为小写
生成单词列表
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
输出词频最大TOP20
将分析对象存为utf-8编码的文件,通过文件读取的方式获得词频分析内容。
f=open('new.txt','r')
str0 = f.read();
f.close();
str1 = ''',.'?!"''';
for i in str1:
list1 = str0.replace(i,' ');
list1 = str0.lower().split();
gath2={'in','to','your','you','and','the','for'};
gath=set(list1)-gath2;
print(gath)
#字典
dict={}
for w in gath:
dict[w]=list1.count(w)
list1 = list(dict.items())
list1.sort(key=lambda x:x[1],reverse=True)
print(list1)
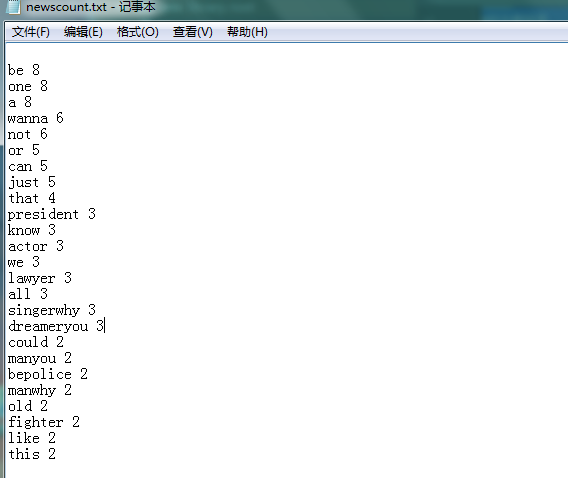
f=open('newscount.txt','a')
for i in range(25):
f.write(list1[i][0]+' '+str(list1[i][1])+'
')
f.close()
运行结果:
[('be', 8), ('one', 8), ('a', 8), ('wanna', 6), ('not', 6), ('or', 5), ('can', 5), ('just', 5), ('that', 4), ('president', 3), ('know', 3), ('actor', 3), ('we', 3), ('lawyer', 3), ('all', 3), ('singerwhy', 3), ('dreameryou', 3), ('could', 2), ('manyou', 2), ('bepolice', 2), ('manwhy', 2), ('old', 2), ('fighter', 2), ('like', 2), ('this', 2), ('got', 2), ('something', 2), ('what', 2), ('really', 2), ('man', 2), ('life', 2), ('post', 2), ('fire', 2), ('on', 2), ('foryou', 1), ('it', 1), ('matterwe', 1), ('matterluxury', 1), ('live', 1), ('real', 1), ('cars', 1), ('caught', 1), ('ways', 1), ('reach', 1), ('lifefocus', 1), ('team', 1), ('nice', 1), ('does', 1), ("that's", 1), ("thingthat's", 1), ('of', 1), ('little', 1), ('play', 1), ("doesn't", 1), ('medoctor', 1), ('topmake', 1), ('dream', 1), ('fori', 1), ('may', 1), ("bring'cause", 1), ('foreverjust', 1), ('nothing', 1), ('every', 1), ('steam', 1), ('lasts', 1), ('bedoctor', 1), ('up', 1), ('bei', 1), ('hold', 1), ('bewe', 1), ('doctor', 1), ('never', 1), ('thingthat', 1), ('different', 1), ('have', 1), ('stopbe', 1), ('sure', 1), ('benow', 1), ('share', 1), ('thinkbut', 1), ('with', 1), ('bling', 1), ("won't", 1), ('sing', 1), ('togetherwe', 1)]
2.中文词频统计:
下载一长篇中文文章。
从文件读取待分析文本。
news = open('gzccnews.txt','r',encoding = 'utf-8')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
输出词频最大TOP20(或把结果存放到文件里)
import jieba
f=open('xiyouji.txt','r',encoding='utf-8')
result = f.read()
f.close();
str1 = ''',。‘’“”:;()!?、 '''
dele = {'我', '道', '不', '一', '了', '那', '是', '来', '他', '个', '行', '你', '的',
'者','有','
','-','出'}
jieba.add_word('三藏')
jieba.add_word('孙行者')
jieba.add_word('猴王')
for i in str1:
result = result.replace(i, '')
tempwords = list(jieba.cut(result))
count = {}
words = list(set(tempwords) - dele)
for i in range(0, len(words)):
count[words[i]] = result.count(str(words[i]))
countList = list(count.items())
countList.sort(key=lambda x: x[1], reverse=True)
print(countList)
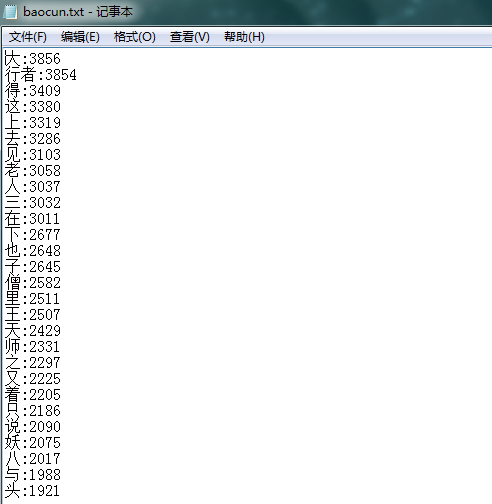
f = open('baocun.txt', 'a',encoding='utf-8')
for i in range(30):
f.write(countList[i][0] + ':' + str(countList[i][1]) + '
')
f.close()
运行结果: