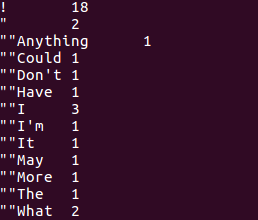
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
到http://novel.tingroom.com/duanpian/2123/英文小说网下载英文小说,总共10万多行

通过WinSCP将该文件放置在虚拟机的wc文件目录下

启动hadoop
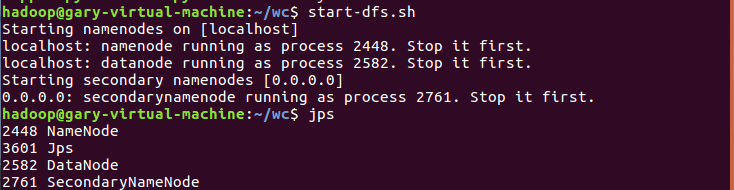
将wc文件夹的story.txt上传文件至hdfs的hive文件夹

启动Hive
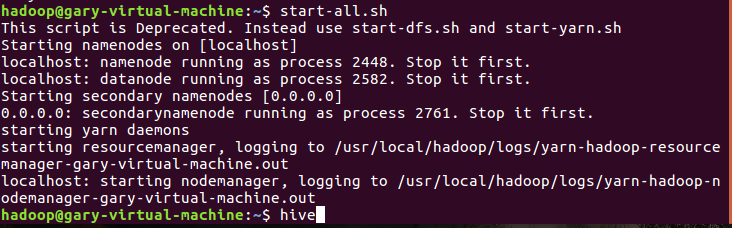
创建原始文档表

导入文件内容到表docs并查看
导入文件:

用HQL进行词频统计,结果放在表story_count里
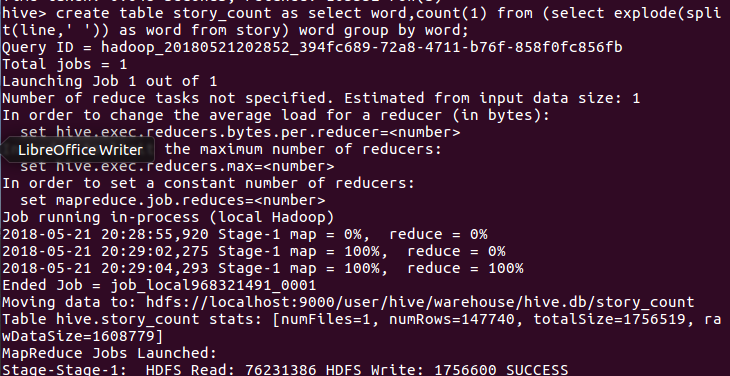
查看统计结果

2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
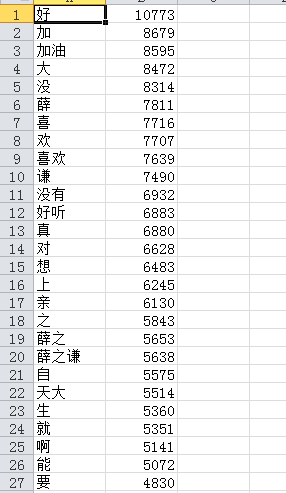
我爬是网易云音乐的薛之谦的评论,并根据评论做了词频统计,产生的csv如下
将csv通过WinSCP放入虚拟机,并上传到dfs

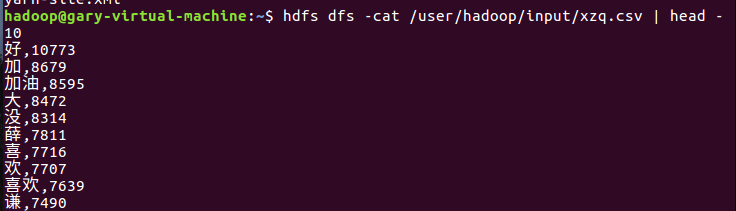
查看前10个数据
启动hive,创建表将csv数据导入到表中

导入数据到名为xzq的表

显示前20条数据
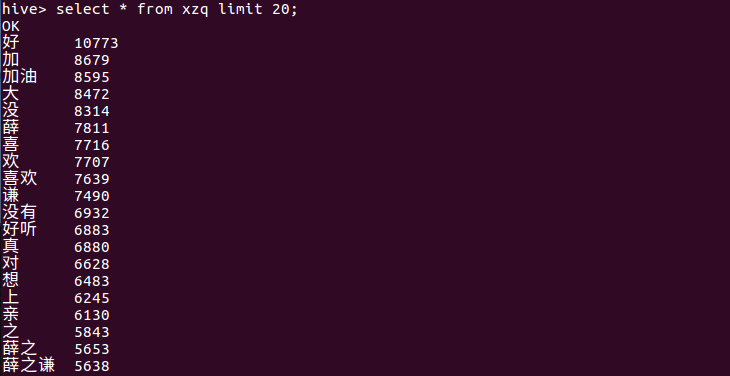
分析结果:从评论上如好、加油、喜欢等可以得出,薛之谦的歌曲还是深受大家喜欢的,黑粉比较少。