原文:https://blog.csdn.net/jasonchen_gbd/article/details/51511261
参考:
https://www.cnblogs.com/jimbo17/p/10107318.html
https://blog.csdn.net/u010487568/article/details/79606141
https://blog.csdn.net/u011784994/article/details/52614935
https://blog.csdn.net/u010424605/article/details/41842877
https://blog.csdn.net/mignatian/article/details/81673713
https://download.csdn.net/download/yunsongice/3326879
1. 通用文件模型
Linux内核支持装载不同的文件系统类型,不同的文件系统有各自管理文件的方式。Linux中标准的文件系统为Ext文件系统族,当然,开发者不能为他们使用的每种文件系统采用不同的文件存取方式,这与操作系统作为一种抽象机制背道而驰。
为支持各种文件系统,Linux内核在用户进程(或C标准库)和具体的文件系统之间引入了一个抽象层,该抽象层称之为“虚拟文件系统(VFS)”。
VFS一方面提供一种操作文件、目录及其他对象的统一方法,使用户进程不必知道文件系统的细节。另一方面,VFS提供的各种方法必须和具体文件系统的实现达成一种妥协,毕竟对几十种文件系统类型进行统一管理并不是件容易的事。
为此,VFS中定义了一个通用文件模型,以支持文件系统中对象(或文件)的统一视图。
Linux对Ext文件系统族的支持是最好的,因为VFS抽象层的组织与Ext文件系统类似,这样在处理Ext文件系统时可以提高性能,因为在Ext和VFS之间转换几乎不会损失时间。
内核处理文件的关键是inode,每个文件(和目录)都有且只有一个对应的inode(struct inode实例),其中包含元数据和指向文件数据的指针,但inode并不包含文件名。系统中所有的inode都有一个特定的编号,用于唯一的标识各个inode。文件名可以随时更改,但是索引节点对文件是唯一的,并且随文件的存在而存在。
对于每个已经挂载的文件系统,VFS在内核中都生成一个超级块结构(struct super_block实例),超级块代表一个已经安装的文件系统,用于存储文件系统的控制信息,例如文件系统类型、大小、所有inode对象、脏的inode链表等。
inode和super block在存储介质中都是有实际映射的,即存储介质中也存在超级块和inode。但是由于不同类型的文件系统差异,超级块和inode的结构不尽相同。而VFS的作用就是通过具体的设备驱动获得某个文件系统中的超级块和inode节点,然后将其中的信息填充到内核中的struct super_block和struct inode中,以此来试图对不同文件系统进行统一管理。
由于块设备速度较慢(于内存而言),可能需要很长时间才能找到与一个文件名关联的inode。Linux使用目录项(dentry)缓存来快速访问此前的查找操作结果。在VFS读取了一个目录或文件的数据之后,则创建一个dentry实例(struct dentry),以缓存找到的数据。
dentry结构的主要用途就是建立文件名和相关的inode之间的联系。一个文件系统中的dentry对象都被放在一个散列表中,同时不再使用的dentry对象被放到超级块指向的一个LRU链表中,在某个时间点会删除比较老的对象以释放内存。
另外简单提一下两个数据结构:
每种注册到内核的文件系统类型以struct file_system_type结构表示,每种文件系统类型中都有一个链表,指向所有属于该类型的文件系统的超级块。
当一个文件系统挂载到内核文件系统的目录树上,会生成一个挂载点,用来管理所挂载的文件系统的信息。该挂载点用一个struct vfsmount结构表示,这个结构后面会提到。
上面的这些结构的关系大致如下:
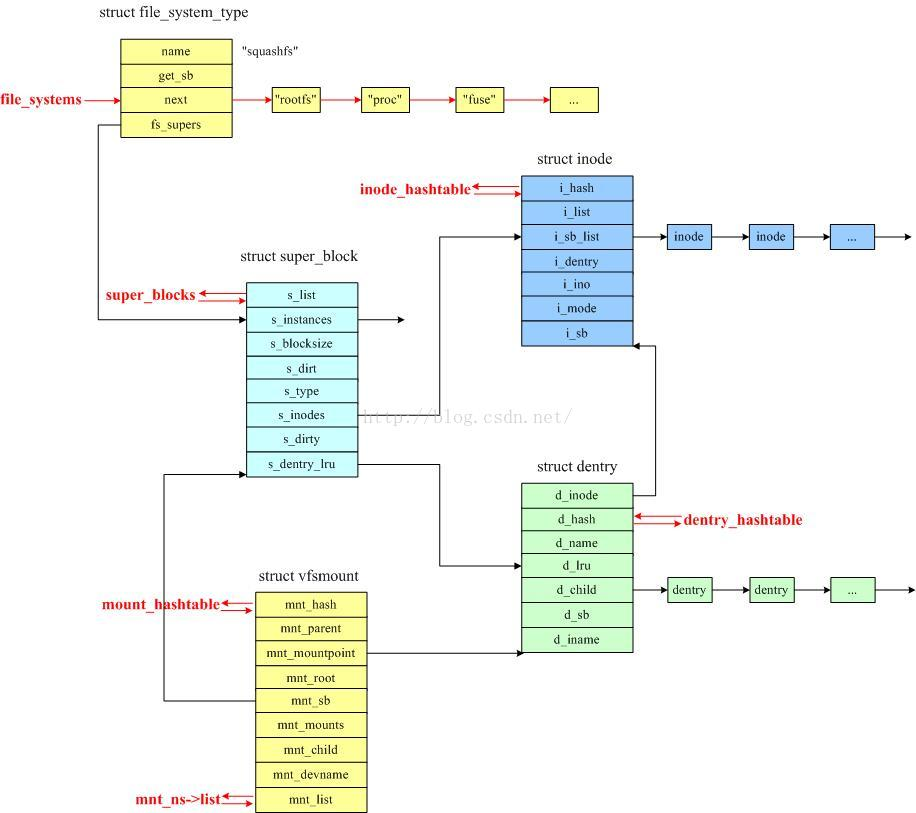
其中红色字体的链表为内核中的全局链表。
2. 挂载文件系统
在用户程序中,使用mount系统调用来挂载文件系统,相应的使用umount卸载文件系统。当然,内核必须支持将要挂载的文件系统类型,在内核启动时或者在安装内核模块时,可以注册特定的文件系统类型到内核,注册的函数为register_filesystem()。
mount命令最常用的方式是mount [-t fstype] something somewhere
其中something是将要被挂载的设备或目录,somewhere指明要挂载到何处。-t选项指明挂载的文件系统类型。由于something指向的设备是一个已知设备,即其上的文件系统类型是确定的,所以-t选项必须设置正确才能挂载成功。
每个装载的文件系统都对应一个vfsmount结构的实例。
由于装载过程是向内核文件系统目录树中添加装载点,这些装载点就存在一种父子关系,这和父目录与子目录的关系类似。例如,我的根文件系统类型是squashfs,装载到根目录“/”,生成一个挂载点,之后我又在/tmp目录挂载了ramfs文件系统,在根文件系统中的tmp目录生成了一个挂载点,这两个挂载点就是父子关系。这种关系存储在struct vfsmount结构中。
在下图中,根文件系统为squashfs,根目录为“/”,然后创建/tmp目录,并挂载为ramfs,之后又创建了/tmp/usbdisk/volume9和/tmp/usbdisk/volume1两个目录,并将/tmp/dev/sda1和/tmp/dev/sdb1两个分区挂载到这两个目录上。其中/tmp/dev/sda1设备上有如下文件:
gccbacktrace/
----> gcc_backtrace.c
---->man_page.log
---->readme.txt
notes-fs.txt
smb.conf
挂载完成后,VFS中相关的数据结构的关系如图所示。
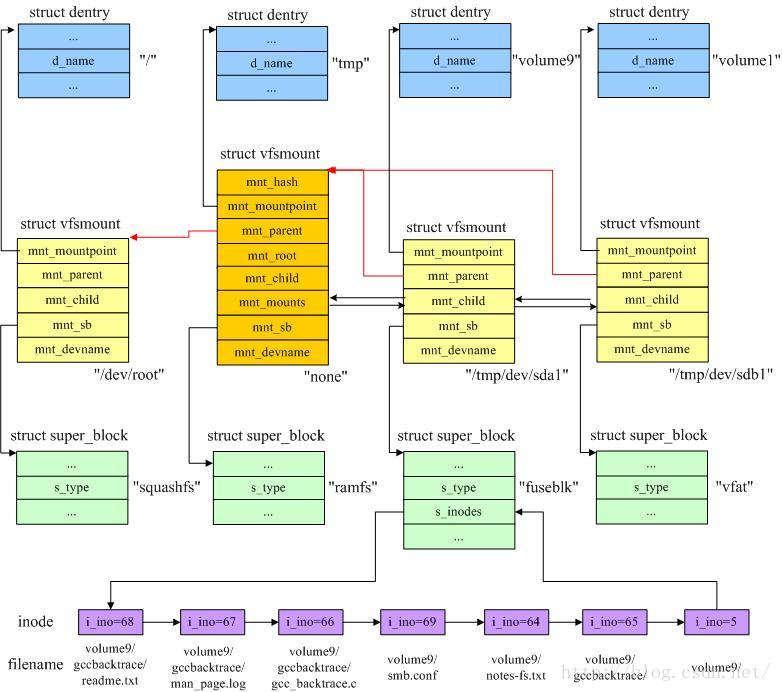
mount系统调用在内核中的入口点是sys_mount函数,该函数将装载的选项从用户态复制一份,然后调用do_mount()函数进行挂载,这个函数做的事情就是通过特定文件系统读取超级块和inode信息,然后建立VFS的数据结构并建立上图中的关系。
在父文件系统中的某个目录上挂载另一个文件系统后,该目录原来的内容就被隐藏了。例如,/tmp/samba/是非空的,然后,我将/tmp/dev/sda1挂载到/tmp/samba上,那这时/tmp/samba/目录下就只能看到/tmp/dev/sda1设备上的文件,直到将该设备卸载,原来目录中的文件才会显示出来。这是通过struct vfsmount中的mnt_mountpoint和mnt_root两个成员来实现的,这两个成员分别保存了在父文件系统中挂载点的dentry和在当前文件系统中挂载点的dentry,在卸载当前挂载点之后,可以找回挂载目录在父文件系统中的dentry对象。
3. 一个进程中与文件系统相关的信息
struct task_struct { …… /* filesystem information */ struct fs_struct *fs; /* open file information */ struct files_struct *files; /* namespaces */ struct nsproxy *nsproxy; …… }
其中fs成员指向进程当前工作目录的文件系统信息。files成员指向了进程打开的文件的信息。nsproxy指向了进程所在的命名空间,其中包含了虚拟文件系统命名空间。

从上图可以看到,fs中包含了文件系统的挂载点和挂载点的dentry信息。而files指向了一系列的struct file结构,其中struct path结构用于将struct file和vfsmount以及dentry联系起来。struct file保存了内核所看到的文件的特征信息,进程打开的文件列表就存放在task_struct->files->fd_array[]数组以及fdtable中。
task_struct结构还存放了其打开文件的文件描述符fd的信息,这是用户进程需要用到的,用户进程在通过文件名打开一个文件后,文件名就没有用处了,之后的操作都是对文件描述符fd的,在内核中,fget_light()函数用于通过整数fd来查找对应的struct file对象。由于每个进程都维护了自己的fd列表,所以不同进程维护的fd的值可以重复,例如标准输入、标准输出和标准错误对应的fd分别为0、1、2。
struct file的mapping成员指向属于文件相关的inode实例的地址空间映射,通常它设置为inode->i_mapping。在读写一个文件时,每次都从物理设备上获取文件的话,速度会很慢,在内核中对每个文件分配一个地址空间,实际上是这个文件的数据缓存区域,在读写文件时只是操作这块缓存,通过内核有相应的同步机制将脏的页写回物理设备。super_block中维护了一个脏的inode的链表。
struct file的f_op成员指向一个struct file_operations实例(图中画错了,不是f_pos),该结构保存了指向所有可能文件操作的指针,如read/write/open等。
struct file_operations { struct module *owner; loff_t (*llseek) (struct file *, loff_t, int); ssize_t (*read) (struct file *, char __user *, size_t, loff_t *); ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *); ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t); ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t); int (*readdir) (struct file *, void *, filldir_t); unsigned int (*poll) (struct file *, struct poll_table_struct *); int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long); long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long); long (*compat_ioctl) (struct file *, unsigned int, unsigned long); int (*mmap) (struct file *, struct vm_area_struct *); int (*open) (struct inode *, struct file *); int (*flush) (struct file *, fl_owner_t id); int (*release) (struct inode *, struct file *); int (*fsync) (struct file *, struct dentry *, int datasync); …… };
4. 打包文件系统
在制作好了文件系统的目录之后,可通过特定于文件系统类型的工具对目录进行打包,即制作文件系统。例如squashfs文件系统的打包工具为mksquashfs。除了打包之外,打包工具还针对特定文件系统生成超级块和inode节点信息,最终生成的文件系统镜像可以被内核解释并挂载。
附录 VFS相关数据结构
inode:
struct inode { /* 全局的散列表 */ struct hlist_node i_hash; /* 根据inode的状态可能处理不同的链表中(inode_unused/inode_in_use/super_block->dirty) */ struct list_head i_list; /* super_block->s_inodes链表的节点 */ struct list_head i_sb_list; /* inode对应的dentry链表,可能多个dentry指向同一个文件 */ struct list_head i_dentry; /* inode编号 */ unsigned long i_ino; /* 访问该inode的进程数目 */ atomic_t i_count; /* inode的硬链接数 */ unsigned int i_nlink; uid_t i_uid; gid_t i_gid; /* inode表示设备文件时的设备号 */ dev_t i_rdev; u64 i_version; /* 文件的大小,以字节为单位 */ loff_t i_size; #ifdef __NEED_I_SIZE_ORDERED seqcount_t i_size_seqcount; #endif /* 最后访问时间 */ struct timespec i_atime; /* 最后修改inode数据的时间 */ struct timespec i_mtime; /* 最后修改inode自身的时间 */ struct timespec i_ctime; /* 以block为单位的inode的大小 */ blkcnt_t i_blocks; unsigned int i_blkbits; unsigned short i_bytes; /* 文件属性,低12位为文件访问权限,同chmod参数含义,其余位为文件类型,如普通文件、目录、socket、设备文件等 */ umode_t i_mode; spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */ struct mutex i_mutex; struct rw_semaphore i_alloc_sem; /* inode操作 */ const struct inode_operations *i_op; /* file操作 */ const struct file_operations *i_fop; /* inode所属的super_block */ struct super_block *i_sb; struct file_lock *i_flock; /* inode的地址空间映射 */ struct address_space *i_mapping; struct address_space i_data; #ifdef CONFIG_QUOTA struct dquot *i_dquot[MAXQUOTAS]; #endif struct list_head i_devices; /* 若为设备文件的inode,则为设备的打开文件列表节点 */ union { struct pipe_inode_info *i_pipe; struct block_device *i_bdev; /* 若为块设备的inode,则指向该设备实例 */ struct cdev *i_cdev; /* 若为字符设备的inode,则指向该设备实例 */ }; __u32 i_generation; #ifdef CONFIG_FSNOTIFY __u32 i_fsnotify_mask; /* all events this inode cares about */ struct hlist_head i_fsnotify_mark_entries; /* fsnotify mark entries */ #endif #ifdef CONFIG_INOTIFY struct list_head inotify_watches; /* watches on this inode */ struct mutex inotify_mutex; /* protects the watches list */ #endif unsigned long i_state; unsigned long dirtied_when; /* jiffies of first dirtying */ unsigned int i_flags; /* 文件打开标记,如noatime */ atomic_t i_writecount; #ifdef CONFIG_SECURITY void *i_security; #endif #ifdef CONFIG_FS_POSIX_ACL struct posix_acl *i_acl; struct posix_acl *i_default_acl; #endif void *i_private; /* fs or device private pointer */ };
super_block:
struct super_block { /* 全局链表元素 */ struct list_head s_list; /* 底层文件系统所在的设备 */ dev_t s_dev; /* 文件系统中每一块的长度 */ unsigned long s_blocksize; /* 文件系统中每一块的长度(以2为底的对数) */ unsigned char s_blocksize_bits; /* 是否需要向磁盘回写 */ unsigned char s_dirt; unsigned long long s_maxbytes; /* Max file size */ /* 文件系统类型 */ struct file_system_type *s_type; /* 超级块操作方法 */ const struct super_operations *s_op; struct dquot_operations *dq_op; struct quotactl_ops *s_qcop; const struct export_operations *s_export_op; unsigned long s_flags; unsigned long s_magic; /* 全局根目录的dentry */ struct dentry *s_root; struct rw_semaphore s_umount; struct mutex s_lock; int s_count; int s_need_sync; atomic_t s_active; #ifdef CONFIG_SECURITY void *s_security; #endif struct xattr_handler **s_xattr; /* 超级块管理的所有inode的链表 */ struct list_head s_inodes; /* all inodes */ /* 脏的inode的链表 */ struct list_head s_dirty; /* dirty inodes */ struct list_head s_io; /* parked for writeback */ struct list_head s_more_io; /* parked for more writeback */ struct hlist_head s_anon; /* anonymous dentries for (nfs) exporting */ /* file结构的链表,该超级块上所有打开的文件 */ struct list_head s_files; /* s_dentry_lru and s_nr_dentry_unused are protected by dcache_lock */ /* 不再使用的dentry的LRU链表 */ struct list_head s_dentry_lru; /* unused dentry lru */ int s_nr_dentry_unused; /* # of dentry on lru */ struct block_device *s_bdev; struct mtd_info *s_mtd; /* 相同文件系统类型的超级块链表的节点 */ struct list_head s_instances; struct quota_info s_dquot; /* Diskquota specific options */ int s_frozen; wait_queue_head_t s_wait_unfrozen; char s_id[32]; /* Informational name */ void *s_fs_info; /* Filesystem private info */ fmode_t s_mode; /* * The next field is for VFS *only*. No filesystems have any business * even looking at it. You had been warned. */ struct mutex s_vfs_rename_mutex; /* Kludge */ /* Granularity of c/m/atime in ns. Cannot be worse than a second */ u32 s_time_gran; /* * Filesystem subtype. If non-empty the filesystem type field * in /proc/mounts will be "type.subtype" */ char *s_subtype; /* * Saved mount options for lazy filesystems using * generic_show_options() */ char *s_options; };
dentry:
struct dentry { atomic_t d_count; unsigned int d_flags; /* protected by d_lock */ spinlock_t d_lock; /* per dentry lock */ /* 该dentry是否是一个装载点 */ int d_mounted; /* 文件所属的inode */ struct inode *d_inode; /* * The next three fields are touched by __d_lookup. Place them here so they all fit in a cache line. */ /* 全局的dentry散列表 */ struct hlist_node d_hash; /* lookup hash list */ /* 父目录的dentry */ struct dentry *d_parent; /* parent directory */ /* 文件的名称,例如对/tmp/a.sh,文件名即为a.sh */ struct qstr d_name; /* 脏的dentry链表的节点 */ struct list_head d_lru; /* LRU list */ /* * d_child and d_rcu can share memory */ union { struct list_head d_child; /* child of parent list */ struct rcu_head d_rcu; } d_u; /* 该dentry子目录中的dentry的节点链表 */ struct list_head d_subdirs; /* our children */ /* 硬链接使用几个不同名称表示同一个文件时,用于连接各个dentry */ struct list_head d_alias; /* inode alias list */ unsigned long d_time; /* used by d_revalidate */ const struct dentry_operations *d_op; /* 所属的super_block */ struct super_block *d_sb; /* The root of the dentry tree */ void *d_fsdata; /* fs-specific data */ /* 如果文件名由少量字符组成,在保存在这里,加速访问 */ unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */ };
vfsmount:
struct vfsmount { /* 全局散列表 */ struct list_head mnt_hash; /* 父文件系统的挂载点 */ struct vfsmount *mnt_parent; /* fs we are mounted on */ /* 父文件系统中该挂载点的dentry */ struct dentry *mnt_mountpoint; /* dentry of mountpoint */ /* 当前文件系统中该挂载点的dentry */ struct dentry *mnt_root; /* root of the mounted tree */ /* 指向super_block */ struct super_block *mnt_sb; /* pointer to superblock */ /* 该挂载点下面的子挂载点列表 */ struct list_head mnt_mounts; /* list of children, anchored here */ /* 父文件系统的子挂载点的列表节点 */ struct list_head mnt_child; /* and going through their mnt_child */ int mnt_flags; /* 4 bytes hole on 64bits arches */ /* 挂载的设备,如/dev/dsk/hda1 */ const char *mnt_devname; /* 虚拟文件系统命名空间中的链表节点 */ struct list_head mnt_list; struct list_head mnt_expire; /* link in fs-specific expiry list */ struct list_head mnt_share; /* circular list of shared mounts */ struct list_head mnt_slave_list;/* list of slave mounts */ struct list_head mnt_slave; /* slave list entry */ struct vfsmount *mnt_master; /* slave is on master->mnt_slave_list */ /* 所在的虚拟文件系统命名空间*/ struct mnt_namespace *mnt_ns; /* containing namespace */ int mnt_id; /* mount identifier */ int mnt_group_id; /* peer group identifier */ /* * We put mnt_count & mnt_expiry_mark at the end of struct vfsmount * to let these frequently modified fields in a separate cache line * (so that reads of mnt_flags wont ping-pong on SMP machines) */ atomic_t mnt_count; int mnt_expiry_mark; /* true if marked for expiry */ int mnt_pinned; int mnt_ghosts; #ifdef CONFIG_SMP int *mnt_writers; #else int mnt_writers; #endif };